This notebook is an exercise in the Pandas course. You can reference the tutorial at this link.
Introduction
介绍
The first step in most data analytics projects is reading the data file. In this exercise, you'll create Series and DataFrame objects, both by hand and by reading data files.
大多数数据分析项目的第一步是读取数据文件。 在本练习中,您将手动或通过读取数据文件来创建 Series 和 DataFrame 对象。
Run the code cell below to load libraries you will need (including code to check your answers).
运行下面的代码单元来加载您需要的库(包括用于检查答案的代码)。
import pandas as pd
# pd.set_option('max_rows', 5)
from learntools.core import binder; binder.bind(globals())
from learntools.pandas.creating_reading_and_writing import *
print("Setup complete.")Setup complete.Exercises
练习
1.
In the cell below, create a DataFrame fruits that looks like this:
在下面的单元格中,创建一个 DataFrame fruits,如下所示:

# Your code goes here. Create a dataframe matching the above diagram and assign it to the variable fruits.
#fruits = ____
fruits = pd.DataFrame({'Apples':[30], 'Bananas':[21]})
# Check your answer
q1.check()
fruitsCorrect
| Apples | Bananas | |
|---|---|---|
| 0 | 30 | 21 |
# q1.hint()
q1.solution()Solution:
fruits = pd.DataFrame([[30, 21]], columns=['Apples', 'Bananas'])2.
Create a dataframe fruit_sales that matches the diagram below:
创建一个与下图匹配的Dataframefruit_sales:
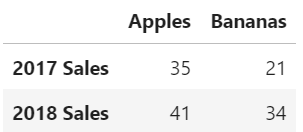
# Your code goes here. Create a dataframe matching the above diagram and assign it to the variable fruit_sales.
#fruit_sales = ____
fruit_sales = pd.DataFrame({'Apples':[35, 41], 'Bananas':[21, 34]}, index=['2017 Sales', '2018 Sales'] )
# Check your answer
q2.check()
fruit_salesCorrect
| Apples | Bananas | |
|---|---|---|
| 2017 Sales | 35 | 21 |
| 2018 Sales | 41 | 34 |
# q2.hint()
q2.solution()Solution:
fruit_sales = pd.DataFrame([[35, 21], [41, 34]], columns=['Apples', 'Bananas'],
index=['2017 Sales', '2018 Sales'])3.
Create a variable ingredients with a Series that looks like:
创建一个Series变量ingredients,如下所示:
Flour 4 cups
Milk 1 cup
Eggs 2 large
Spam 1 can
Name: Dinner, dtype: object#ingredients = ____
ingredients = pd.Series(['4 cups', '1 cup', '2 large', '1 can'], index=['Flour', 'Milk', 'Eggs', 'Spam'], name='Dinner')
# Check your answer
q3.check()Correct
#q3.hint()
q3.solution()Solution:
quantities = ['4 cups', '1 cup', '2 large', '1 can']
items = ['Flour', 'Milk', 'Eggs', 'Spam']
recipe = pd.Series(quantities, index=items, name='Dinner')4.
Read the following csv dataset of wine reviews into a DataFrame called reviews:
将以下葡萄酒评论的 csv 数据集读取到名为reviews的 DataFrame 中:
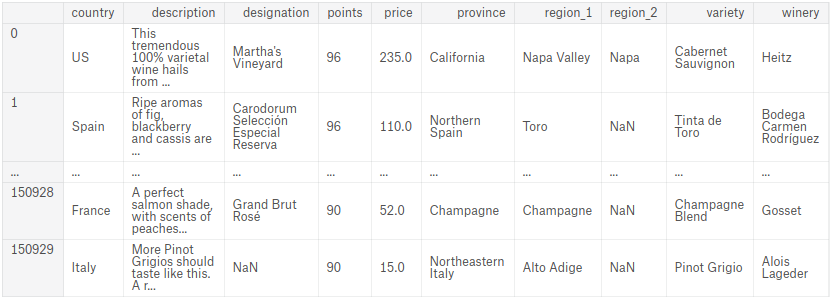
The filepath to the csv file is ../input/wine-reviews/winemag-data_first150k.csv. The first few lines look like:
csv 文件的文件路径是 ../input/wine-reviews/winemag-data_first150k.csv。 前几行看起来像:
,country,description,designation,points,price,province,region_1,region_2,variety,winery
0,US,"This tremendous 100% varietal wine[...]",Martha's Vineyard,96,235.0,California,Napa Valley,Napa,Cabernet Sauvignon,Heitz
1,Spain,"Ripe aromas of fig, blackberry and[...]",Carodorum Selección Especial Reserva,96,110.0,Northern Spain,Toro,,Tinta de Toro,Bodega Carmen Rodríguez#reviews = ____
reviews = pd.read_csv('../input/wine-reviews/winemag-data_first150k.csv', index_col=0)
# Check your answer
q4.check()
reviewsCorrect
| country | description | designation | points | price | province | region_1 | region_2 | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | US | This tremendous 100% varietal wine hails from ... | Martha's Vineyard | 96 | 235.0 | California | Napa Valley | Napa | Cabernet Sauvignon | Heitz |
| 1 | Spain | Ripe aromas of fig, blackberry and cassis are ... | Carodorum Selección Especial Reserva | 96 | 110.0 | Northern Spain | Toro | NaN | Tinta de Toro | Bodega Carmen Rodríguez |
| 2 | US | Mac Watson honors the memory of a wine once ma... | Special Selected Late Harvest | 96 | 90.0 | California | Knights Valley | Sonoma | Sauvignon Blanc | Macauley |
| 3 | US | This spent 20 months in 30% new French oak, an... | Reserve | 96 | 65.0 | Oregon | Willamette Valley | Willamette Valley | Pinot Noir | Ponzi |
| 4 | France | This is the top wine from La Bégude, named aft... | La Brûlade | 95 | 66.0 | Provence | Bandol | NaN | Provence red blend | Domaine de la Bégude |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 150925 | Italy | Many people feel Fiano represents southern Ita... | NaN | 91 | 20.0 | Southern Italy | Fiano di Avellino | NaN | White Blend | Feudi di San Gregorio |
| 150926 | France | Offers an intriguing nose with ginger, lime an... | Cuvée Prestige | 91 | 27.0 | Champagne | Champagne | NaN | Champagne Blend | H.Germain |
| 150927 | Italy | This classic example comes from a cru vineyard... | Terre di Dora | 91 | 20.0 | Southern Italy | Fiano di Avellino | NaN | White Blend | Terredora |
| 150928 | France | A perfect salmon shade, with scents of peaches... | Grand Brut Rosé | 90 | 52.0 | Champagne | Champagne | NaN | Champagne Blend | Gosset |
| 150929 | Italy | More Pinot Grigios should taste like this. A r... | NaN | 90 | 15.0 | Northeastern Italy | Alto Adige | NaN | Pinot Grigio | Alois Lageder |
150930 rows × 10 columns
#q4.hint()
q4.solution()Solution:
reviews = pd.read_csv('../input/wine-reviews/winemag-data_first150k.csv', index_col=0)5.
Run the cell below to create and display a DataFrame called animals:
运行下面的单元格来创建并显示一个名为animals的 DataFrame:
animals = pd.DataFrame({'Cows': [12, 20], 'Goats': [22, 19]}, index=['Year 1', 'Year 2'])
animals| Cows | Goats | |
|---|---|---|
| Year 1 | 12 | 22 |
| Year 2 | 20 | 19 |
In the cell below, write code to save this DataFrame to disk as a csv file with the name cows_and_goats.csv.
在下面的单元格中,编写代码以将此 DataFrame 作为 csv 文件保存到磁盘,名称为cows_and_goats.csv。
# Your code goes here
animals.to_csv('cows_and_goats.csv')
# Check your answer
q5.check()Correct
#q5.hint()
q5.solution()Solution:
animals.to_csv("cows_and_goats.csv")Keep going
继续前进
Move on to learn about indexing, selecting and assigning.
继续了解索引、选择和赋值。