In this tutorial, you will learn three approaches to dealing with missing values. Then you'll compare the effectiveness of these approaches on a real-world dataset.
在本教程中,您将学习三种处理缺失值的方法。 然后,您将在现实数据集上比较这些方法的有效性。
Introduction
介绍
There are many ways data can end up with missing values. For example,
数据最终可能会出现缺失值的情况有很多。 例如,
- A 2 bedroom house won't include a value for the size of a third bedroom.
- 两居室房屋不包含第三间卧室大小的价值。
- A survey respondent may choose not to share his income.
- 调查受访者可以选择不分享他的收入。
Most machine learning libraries (including scikit-learn) give an error if you try to build a model using data with missing values. So you'll need to choose one of the strategies below.
如果您尝试使用缺失值的数据构建模型,大多数机器学习库(包括 scikit-learn)都会出错。 因此,您需要选择以下策略之一。
Three Approaches
三种方法
1) A Simple Option: Drop Columns with Missing Values
1) 一个简单的选项:删除缺失值的列
The simplest option is to drop columns with missing values.
最简单的选择是删除缺少值的列。

Unless most values in the dropped columns are missing, the model loses access to a lot of (potentially useful!) information with this approach. As an extreme example, consider a dataset with 10,000 rows, where one important column is missing a single entry. This approach would drop the column entirely!
除非删除的列中的大多数值丢失,否则模型将无法使用此方法访问大量(可能有用!)信息。 作为一个极端的示例,请考虑一个包含 10,000 行的数据集,其中一个重要列缺少单个条目。 这种方法会完全删除该列!
2) A Better Option: Imputation
2) 更好的选择:插补
Imputation fills in the missing values with some number. For instance, we can fill in the mean value along each column.
插补用一些数字填充缺失值。 例如,我们可以填写每列的平均值。
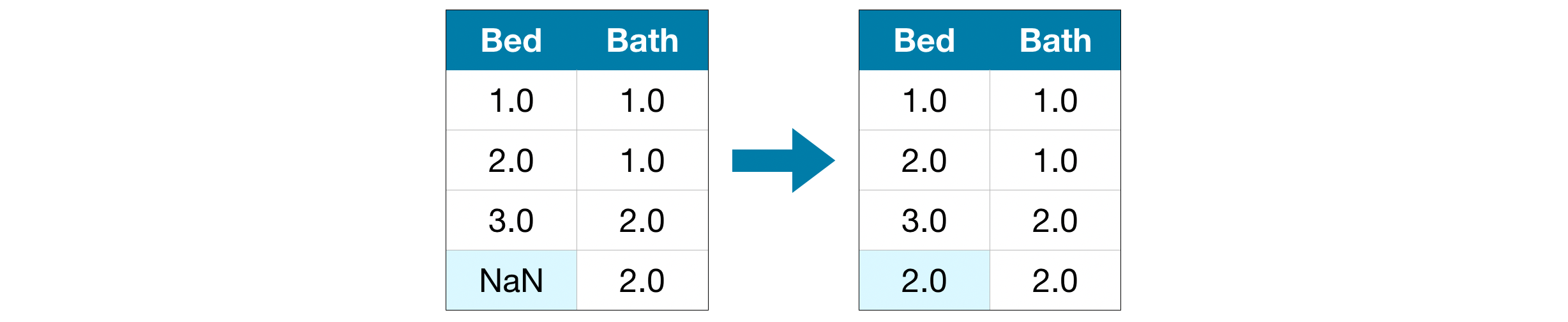
The imputed value won't be exactly right in most cases, but it usually leads to more accurate models than you would get from dropping the column entirely.
在大多数情况下,估算值并不完全正确,但与完全删除列相比,它通常会产生更准确的模型。
3) An Extension To Imputation
3) 插补的扩展
Imputation is the standard approach, and it usually works well. However, imputed values may be systematically above or below their actual values (which weren't collected in the dataset). Or rows with missing values may be unique in some other way. In that case, your model would make better predictions by considering which values were originally missing.
插补是标准方法,通常效果较好。 但是,估算值可能系统地高于或低于其实际值(未在数据集中收集)。 或者,具有缺失值的行可能以其他方式是唯一的。 在这种情况下,您的模型将通过考虑最初丢失的值来做出更好的预测。
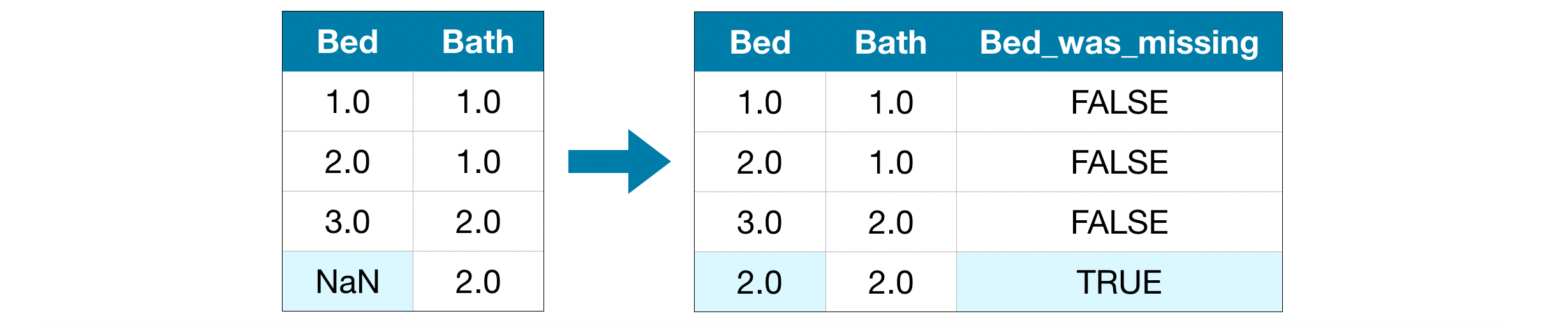
In this approach, we impute the missing values, as before. And, additionally, for each column with missing entries in the original dataset, we add a new column that shows the location of the imputed entries.
在这种方法中,我们像以前一样估算缺失值。 此外,对于原始数据集中缺少条目的每一列,我们添加一个新列来显示估算条目的位置。
In some cases, this will meaningfully improve results. In other cases, it doesn't help at all.
在某些情况下,这将显着改善结果。 在其他情况下,它根本没有帮助。
Example
例子
In the example, we will work with the Melbourne Housing dataset. Our model will use information such as the number of rooms and land size to predict home price.
在示例中,我们将使用墨尔本住房数据集。 我们的模型将使用房间数量和土地面积等信息来预测房价。
We won't focus on the data loading step. Instead, you can imagine you are at a point where you already have the training and validation data in X_train, X_valid, y_train, and y_valid.
我们不会关注数据加载步骤。 相反,您可以想象您已经在X_train、X_valid、y_train和y_valid中拥有训练和验证数据。
import pandas as pd
from sklearn.model_selection import train_test_split
# Load the data
data = pd.read_csv('../00 datasets/dansbecker/melbourne-housing-snapshot/melb_data.csv')
# Select target
y = data.Price
# To keep things simple, we'll use only numerical predictors
melb_predictors = data.drop(['Price'], axis=1)
X = melb_predictors.select_dtypes(exclude=['object'])
# Divide data into training and validation subsets
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)Define Function to Measure Quality of Each Approach
定义函数来衡量每种方法的质量
We define a function score_dataset() to compare different approaches to dealing with missing values. This function reports the mean absolute error (MAE) from a random forest model.
我们定义一个函数score_dataset()来比较处理缺失值的不同方法。 此函数报告随机森林模型的平均绝对误差 (MAE)。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches
# 比较不同方法的函数
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)Score from Approach 1 (Drop Columns with Missing Values)
方法 1 的得分(删除缺失值的列)
Since we are working with both training and validation sets, we are careful to drop the same columns in both DataFrames.
由于我们同时使用训练集和验证集,因此我们会小心地在两个 DataFrame 中删除相同的列。
# Get names of columns with missing values
# 获取有缺失值的列
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# Drop columns in training and validation data
# 在训练集和验证集中删除列
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))MAE from Approach 1 (Drop columns with missing values):
183550.22137772635Score from Approach 2 (Imputation)
方法 2 的得分(插补)
Next, we use SimpleImputer to replace missing values with the mean value along each column.
接下来,我们使用 SimpleImputer 将缺失值替换为每列的平均值。
Although it's simple, filling in the mean value generally performs quite well (but this varies by dataset). While statisticians have experimented with more complex ways to determine imputed values (such as regression imputation, for instance), the complex strategies typically give no additional benefit once you plug the results into sophisticated machine learning models.
虽然很简单,但填充平均值通常效果很好(但这因数据集而异)。 虽然统计学家尝试了更复杂的方法来确定估算值(例如回归估算),但一旦将结果插入复杂的机器学习模型,复杂的策略通常不会带来额外的好处。
from sklearn.impute import SimpleImputer
# Imputation
# 插补
my_imputer = SimpleImputer(strategy="mean")
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Imputation removed column names; put them back
# 插补删除了列名; 将其放回
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))MAE from Approach 2 (Imputation):
178166.46269899711We see that Approach 2 has lower MAE than Approach 1, so Approach 2 performed better on this dataset.
我们看到方法 2 的 MAE 低于 方法 1,因此 方法 2 在此数据集上表现更好。
Score from Approach 3 (An Extension to Imputation)
方法 3 的得分(插补的扩展)
Next, we impute the missing values, while also keeping track of which values were imputed.
接下来,我们估算缺失值,同时还跟踪估算了哪些值。
# Make copy to avoid changing original data (when imputing)
# 进行复制以避免更改原始数据(插补时)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed
# 创建新列来指示将估算的内容
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
# 插补
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation removed column names; put them back
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))MAE from Approach 3 (An Extension to Imputation):
178927.503183954As we can see, Approach 3 performed slightly worse than Approach 2.
正如我们所看到的,方法 3 的表现比 方法 2 稍差。
So, why did imputation perform better than dropping the columns?
那么,为什么插补比删除列表现更好?
The training data has 10864 rows and 12 columns, where three columns contain missing data. For each column, less than half of the entries are missing. Thus, dropping the columns removes a lot of useful information, and so it makes sense that imputation would perform better.
训练数据有 10864 行和 12 列,其中 3 列包含缺失数据。 对于每一列,缺失的条目不到一半。 因此,删除列会删除很多有用的信息,因此插补会表现得更好是有道理的。
# Shape of training data (num_rows, num_columns)
# 训练集的形状
print(X_train.shape)
# Number of missing values in each column of training data
# 每列训练数据中缺失值的数量
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])(10864, 12)
Car 49
BuildingArea 5156
YearBuilt 4307
dtype: int64Conclusion
结论
As is common, imputing missing values (in Approach 2 and Approach 3) yielded better results, relative to when we simply dropped columns with missing values (in Approach 1).
通常,相对于我们简单地删除包含缺失值的列(在 方法 1 中),估算缺失值(在 方法 2 和 方法 3 中)会产生更好的结果。
Your Turn
到你了
Compare these approaches to dealing with missing values yourself in this exercise!
在本练习中自行比较这些处理缺失值的方法!