In this tutorial, you will learn how to use cross-validation for better measures of model performance.
在本教程中,您将学习如何使用交叉验证来更好地衡量模型性能。
Introduction
介绍
Machine learning is an iterative process.
机器学习是一个迭代过程。
You will face choices about what predictive variables to use, what types of models to use, what arguments to supply to those models, etc. So far, you have made these choices in a data-driven way by measuring model quality with a validation (or holdout) set.
您将面临有关使用哪些预测变量、使用什么类型的模型、为这些模型提供哪些参数等的选择。到目前为止,您已经以数据驱动的方式,通过验证集来衡量模型质量。
But there are some drawbacks to this approach. To see this, imagine you have a dataset with 5000 rows. You will typically keep about 20% of the data as a validation dataset, or 1000 rows. But this leaves some random chance in determining model scores. That is, a model might do well on one set of 1000 rows, even if it would be inaccurate on a different 1000 rows.
但这种方法有一些缺点。 要看到这一点,假设您有一个包含 5000 行的数据集。 您通常会保留大约 20% 的数据作为验证数据集,即 1000 行。 但这在确定模型分数时留下了一些随机机会。 也就是说,模型可能在一组 1000 行上表现良好,即使它在不同的 1000 行上可能不准确。
At an extreme, you could imagine having only 1 row of data in the validation set. If you compare alternative models, which one makes the best predictions on a single data point will be mostly a matter of luck!
在极端情况下,您可以想象验证集中只有 1 行数据。 如果您比较其他模型,哪个模型对单个数据点做出最好的预测将主要取决于运气!
In general, the larger the validation set, the less randomness (aka "noise") there is in our measure of model quality, and the more reliable it will be. Unfortunately, we can only get a large validation set by removing rows from our training data, and smaller training datasets mean worse models!
一般来说,验证集越大,我们衡量模型质量的随机性(也称为噪声)就越少,并且越可靠。 不幸的是,我们只能通过从训练数据中删除行来获得大的验证集,而较小的训练数据集意味着更差的模型!
What is cross-validation?
什么是交叉验证?
In cross-validation, we run our modeling process on different subsets of the data to get multiple measures of model quality.
在交叉验证中,我们对不同的数据子集运行建模过程,以获得模型质量的多种度量。
For example, we could begin by dividing the data into 5 pieces, each 20% of the full dataset. In this case, we say that we have broken the data into 5 "folds".
例如,我们可以首先将数据分为 5 部分,每部分占完整数据集的 20%。 在这种情况下,我们说我们已将数据分成 5 个“折叠”。
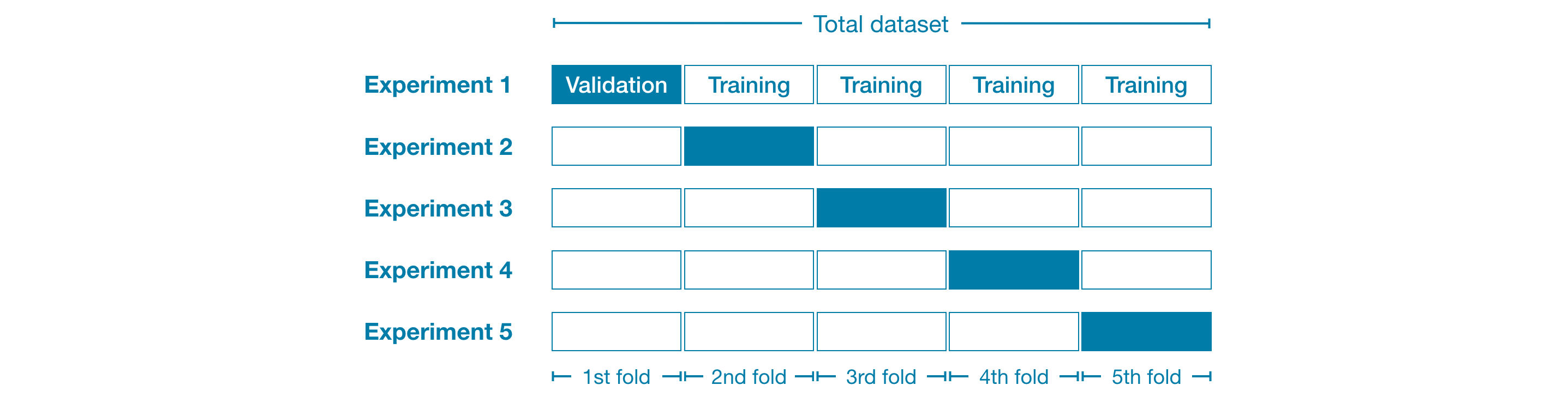
Then, we run one experiment for each fold:
然后,我们为每个折叠运行一个实验:
- In Experiment 1, we use the first fold as a validation (or holdout) set and everything else as training data. This gives us a measure of model quality based on a 20% holdout set.
- 在 实验 1 中,我们使用第一次折叠作为验证(或保留)集,并将其他所有内容作为训练数据。 这为我们提供了基于 20% 保留集的模型质量衡量标准。
- In Experiment 2, we hold out data from the second fold (and use everything except the second fold for training the model). The holdout set is then used to get a second estimate of model quality.
- 在实验 2 中,我们保留第二次折叠中的数据(并使用除第二次折叠之外的所有数据来训练模型)。 然后使用保留集来获得模型质量的第二次估计。
- We repeat this process, using every fold once as the holdout set. Putting this together, 100% of the data is used as holdout at some point, and we end up with a measure of model quality that is based on all of the rows in the dataset (even if we don't use all rows simultaneously).
- 我们重复这个过程,使用每个折叠一次作为保留集。 总而言之,100% 的数据在某个时刻被用作保留,最终我们得到了基于数据集中所有行的模型质量度量(即使我们不同时使用所有行) 。
When should you use cross-validation?
什么时候应该使用交叉验证?
Cross-validation gives a more accurate measure of model quality, which is especially important if you are making a lot of modeling decisions. However, it can take longer to run, because it estimates multiple models (one for each fold).
交叉验证可以更准确地衡量模型质量,如果您要做出大量建模决策,这一点尤其重要。 但是,它可能需要更长的时间来运行,因为它估计多个模型(每个折叠一个)。
So, given these tradeoffs, when should you use each approach?
那么,考虑到这些权衡,您应该何时使用这种方法?
- For small datasets, where extra computational burden isn't a big deal, you should run cross-validation.
- 对于小型数据集,额外的计算负担并不是什么大问题,您应该运行交叉验证。
- For larger datasets, a single validation set is sufficient. Your code will run faster, and you may have enough data that there's little need to re-use some of it for holdout.
- 对于较大的数据集,单个验证集就足够了。 您的代码将运行得更快,并且您可能拥有足够的数据,几乎不需要重复使用其中的一些数据来保留。
There's no simple threshold for what constitutes a large vs. small dataset. But if your model takes a couple minutes or less to run, it's probably worth switching to cross-validation.
对于什么样的是大数据集和小数据集,没有简单的阈值。 但是,如果您的模型需要几分钟或更短的时间就能运行,则可能值得切换到交叉验证。
Alternatively, you can run cross-validation and see if the scores for each experiment seem close. If each experiment yields the same results, a single validation set is probably sufficient.
或者,您可以运行交叉验证,看看每个实验的分数是否看起来很接近。 如果每个实验产生相同的结果,则单个验证集可能就足够了。
Example
例子
We'll work with the same data as in the previous tutorial. We load the input data in X and the output data in y.
我们将使用与上一个教程中相同的数据。 我们将输入数据加载到X中,将输出数据加载到y中。
import pandas as pd
# Read the data
data = pd.read_csv('../00 datasets/dansbecker/melbourne-housing-snapshot/melb_data.csv')
# Select subset of predictors
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Select target
y = data.PriceThen, we define a pipeline that uses an imputer to fill in missing values and a random forest model to make predictions.
然后,我们定义一个管道,使用输入器来填充缺失值,并使用随机森林模型来进行预测。
While it's possible to do cross-validation without pipelines, it is quite difficult! Using a pipeline will make the code remarkably straightforward.
虽然可以在没有管道的情况下进行交叉验证,但这非常困难! 使用管道将使代码变得非常简单。
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),
('model', RandomForestRegressor(n_estimators=50,
random_state=0))
])We obtain the cross-validation scores with the cross_val_score() function from scikit-learn. We set the number of folds with the cv parameter.
我们使用 scikit-learn 中的 cross_val_score() 函数获取交叉验证分数。 我们使用cv参数设置折叠次数。
from sklearn.model_selection import cross_val_score
# Multiply by -1 since sklearn calculates *negative* MAE
# 乘以 -1,因为 sklearn 计算*负* MAE
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5,
scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)MAE scores:
[301628.7893587 303164.4782723 287298.331666 236061.84754543
260383.45111427]The scoring parameter chooses a measure of model quality to report: in this case, we chose negative mean absolute error (MAE). The docs for scikit-learn show a list of options.
评分参数选择要报告的模型质量度量:在本例中,我们选择负平均绝对误差 (MAE)。 scikit-learn 的文档显示了选项列表。
It is a little surprising that we specify negative MAE. Scikit-learn has a convention where all metrics are defined so a high number is better. Using negatives here allows them to be consistent with that convention, though negative MAE is almost unheard of elsewhere.
我们指定负MAE 有点令人惊讶。 Scikit-learn 有一个约定,其中定义了所有指标,因此数字越大越好。 在这里使用负数可以使它们与该约定保持一致,尽管负 MAE 在其他地方几乎闻所未闻。
We typically want a single measure of model quality to compare alternative models. So we take the average across experiments.
我们通常需要单一的模型质量度量来比较替代模型。 所以我们取实验的平均值。
print("Average MAE score (across experiments):")
print(scores.mean())Average MAE score (across experiments):
277707.3795913405Conclusion
结论
Using cross-validation yields a much better measure of model quality, with the added benefit of cleaning up our code: note that we no longer need to keep track of separate training and validation sets. So, especially for small datasets, it's a good improvement!
使用交叉验证可以更好地衡量模型质量,并具有清理代码的额外好处:请注意,我们不再需要跟踪单独的训练集和验证集。 因此,特别是对于小型数据集,这是一个很好的改进!
Your Turn
到你了
Put your new skills to work in the next exercise!
在 下一个练习 中运用您的新技能!