At the end of this step, you will understand the concepts of underfitting and overfitting, and you will be able to apply these ideas to make your models more accurate.
在此步骤结束时,您将了解欠拟合和过拟合的概念,并且您将能够应用这些想法使您的模型更加准确。
Experimenting With Different Models
尝试不同的模型
Now that you have a reliable way to measure model accuracy, you can experiment with alternative models and see which gives the best predictions. But what alternatives do you have for models?
现在您已经有了衡量模型准确性的可靠方法,您可以尝试替代模型,看看哪个模型可以提供最佳预测。 但是对于模型你还有什么选择呢?
You can see in scikit-learn's documentation that the decision tree model has many options (more than you'll want or need for a long time). The most important options determine the tree's depth. Recall from the first lesson in this course that a tree's depth is a measure of how many splits it makes before coming to a prediction. This is a relatively shallow tree
您可以在 scikit-learn 的文档中看到决策树模型有很多选项(在很长的一段时间内会比您想要或需要的更多)。 最重要的选项决定树的深度。 回想一下本课程的第一课,树的深度是衡量它在进行预测之前进行了多少次分割的度量。 这是一棵比较浅的树
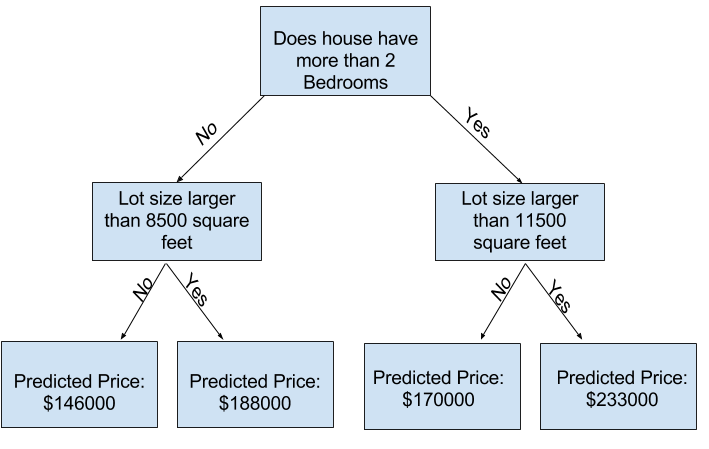
In practice, it's not uncommon for a tree to have 10 splits between the top level (all houses) and a leaf. As the tree gets deeper, the dataset gets sliced up into leaves with fewer houses. If a tree only had 1 split, it divides the data into 2 groups. If each group is split again, we would get 4 groups of houses. Splitting each of those again would create 8 groups. If we keep doubling the number of groups by adding more splits at each level, we'll have \(2^{10}\) groups of houses by the time we get to the 10th level. That's 1024 leaves.
实际上,一棵树在顶层(所有房屋)和叶子之间有 10 个裂缝的情况并不罕见。 随着树变得更深,数据集被分割成具有更少房屋的叶子。 如果一棵树只有 1 次分裂,它会将数据分为 2 组。 如果将每组再次分割,我们将得到 4 组。 再次将每个组分开将创建 8 个组。 如果我们通过在每个级别添加更多分区来继续将组数加倍,那么到第 10 级时我们将拥有 $(2^{10})$ 组房屋。 那是 1024 片叶子。
When we divide the houses amongst many leaves, we also have fewer houses in each leaf. Leaves with very few houses will make predictions that are quite close to those homes' actual values, but they may make very unreliable predictions for new data (because each prediction is based on only a few houses).
当我们将房屋划分为许多叶子时,每个叶子中的枝也会减少。 拥有很少房屋的叶子将做出与这些房屋的实际价值非常接近的预测,但它们可能对新数据做出非常不可靠的预测(因为每个预测仅基于少数房屋)。
This is a phenomenon called overfitting, where a model matches the training data almost perfectly, but does poorly in validation and other new data. On the flip side, if we make our tree very shallow, it doesn't divide up the houses into very distinct groups.
这是一种称为过拟合的现象,其中模型与训练数据几乎完美匹配,但在验证和其他新数据中表现不佳。 另一方面,如果我们把树做得很浅,它就不会把房子分成非常不同的组。
At an extreme, if a tree divides houses into only 2 or 4, each group still has a wide variety of houses. Resulting predictions may be far off for most houses, even in the training data (and it will be bad in validation too for the same reason). When a model fails to capture important distinctions and patterns in the data, so it performs poorly even in training data, that is called underfitting.
在极端情况下,如果一棵树只将房屋分为 2 或 4 个,那么每个组中仍然有各种各样的房屋。 对于大多数房屋来说,即使在训练数据中,最终的预测也可能相差很远(并且出于同样的原因,在验证中也会很糟糕)。 当模型无法捕获数据中的重要区别和模式时,即使在训练数据中它也表现不佳,这称为欠拟合。
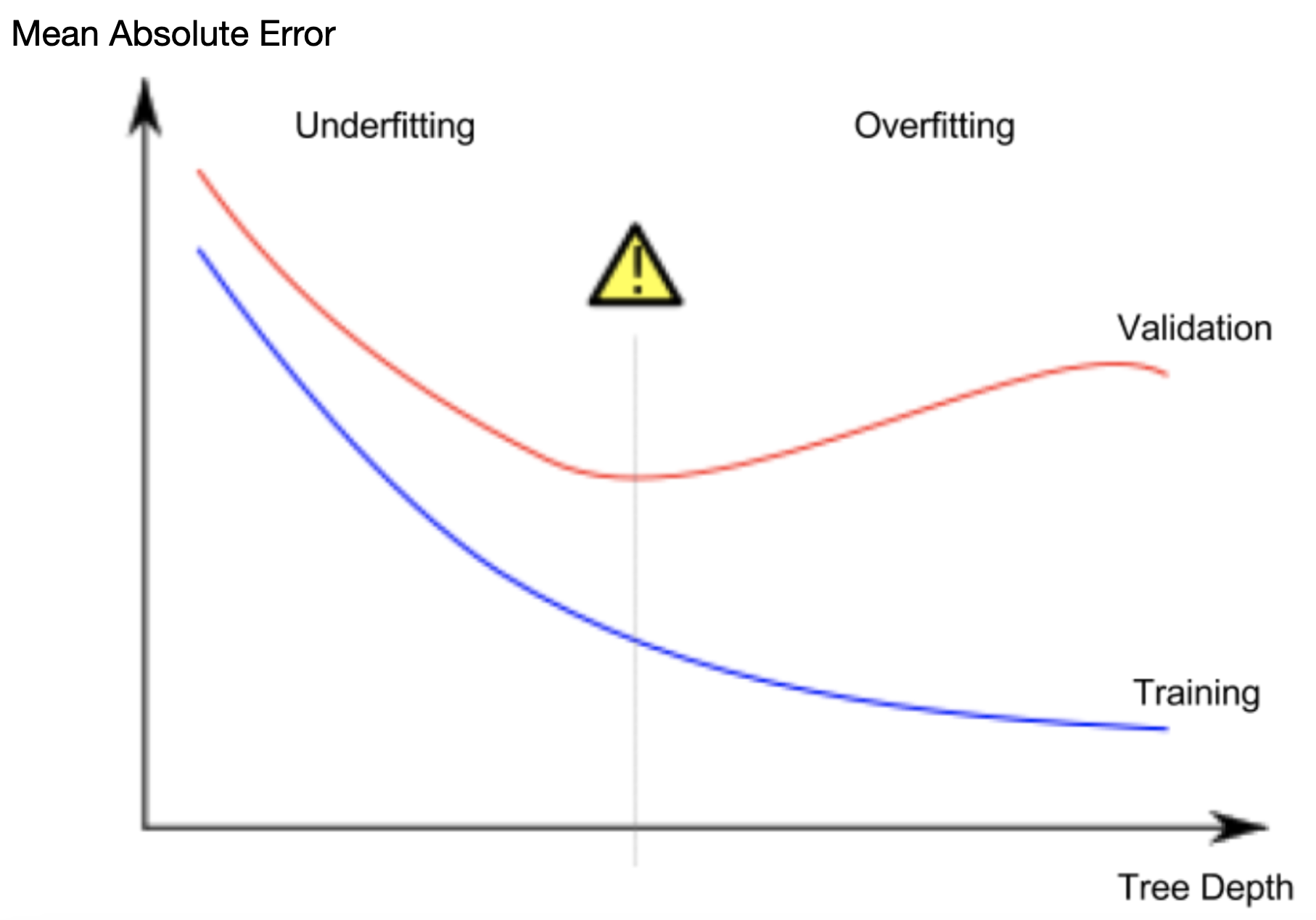
Since we care about accuracy on new data, which we estimate from our validation data, we want to find the sweet spot between underfitting and overfitting. Visually, we want the low point of the (red) validation curve in the figure below.
由于我们关心新数据的准确性,这是我们根据验证数据估计的,因此我们希望找到欠拟合和过度拟合之间的最佳点。 从视觉上看,我们想要下图中(红色)验证曲线的低点。
Example
例子
There are a few alternatives for controlling the tree depth, and many allow for some routes through the tree to have greater depth than other routes. But the max_leaf_nodes argument provides a very sensible way to control overfitting vs underfitting. The more leaves we allow the model to make, the more we move from the underfitting area in the above graph to the overfitting area.
有几种控制树深度的替代方法,并且许多方法允许通过树的某些路线比其他路线具有更大的深度。 但是 max_leaf_nodes 参数提供了一种非常明智的方法来控制过拟合与欠拟合。 我们允许模型制作的叶子越多,我们从上图中的欠拟合区域移动到过拟合区域的程度就越多。
We can use a utility function to help compare MAE scores from different values for max_leaf_nodes:
我们可以使用实用函数来帮助比较 max_leaf_nodes 不同值的 MAE 分数:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)The data is loaded into train_X, val_X, train_y and val_y using the code you've already seen (and which you've already written).
使用您已经见过的代码(以及您已经编写的代码)将数据加载到 train_X、val_X、train_y 和 val_y 中。
# Data Loading Code Runs At This Point
import pandas as pd
# Load data
melbourne_file_path = '../00 datasets/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Filter rows with missing values
# 过滤缺失值
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
# 选择目标和特征
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
# 将数据分为训练数据和验证数据,分别用于特征和目标
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 55)We can use a for-loop to compare the accuracy of models built with different values for max_leaf_nodes.
我们可以使用 for 循环来比较使用不同 max_leaf_nodes 值构建的模型的准确性。
# compare MAE with differing values of max_leaf_nodes
# 将 MAE 与 max_leaf_nodes 的不同值进行比较
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))Max leaf nodes: 5 Mean Absolute Error: 342535
Max leaf nodes: 50 Mean Absolute Error: 261987
Max leaf nodes: 500 Mean Absolute Error: 247069
Max leaf nodes: 5000 Mean Absolute Error: 255518Of the options listed, 500 is the optimal number of leaves.
在上列的选项中,500 是最佳叶子数。
Conclusion
结论
Here's the takeaway: Models can suffer from either:
- Overfitting: capturing spurious patterns that won't recur in the future, leading to less accurate predictions, or
- Underfitting: failing to capture relevant patterns, again leading to less accurate predictions.
要点如下:模型可能会遇到以下任一问题:
- 过拟合:捕获未来不会重复出现的虚假模式,导致预测不太准确,或者
- 欠拟合:未能捕获相关模式,再次导致预测不太准确。
We use validation data, which isn't used in model training, to measure a candidate model's accuracy. This lets us try many candidate models and keep the best one.
我们使用模型训练中未使用的验证数据来衡量候选模型的准确性。 这让我们可以尝试许多候选模型并保留最好的一个。
Your Turn
Try optimizing the model you've previously built.
到你了
尝试优化您之前构建的模型。