Welcome to Deep Learning!
欢迎来到深度学习!
Welcome to Kaggle's Introduction to Deep Learning course! You're about to learn all you need to get started building your own deep neural networks. Using Keras and Tensorflow you'll learn how to:
欢迎来到 Kaggle 的深度学习简介课程! 您将学习开始构建自己的深度神经网络所需的所有知识。 使用 Keras 和 Tensorflow,您将学习如何:
- create a fully-connected neural network architecture
- 创建全连接神经网络架构
- apply neural nets to two classic ML problems: regression and classification
- 将神经网络应用于两个经典的机器学习问题:回归和分类
- train neural nets with stochastic gradient descent, and
- 使用随机梯度下降训练神经网络,以及
- improve performance with dropout, batch normalization, and other techniques
- 通过dropout、批量归一化和其他技术提高性能
The tutorials will introduce you to these topics with fully-worked examples, and then in the exercises, you'll explore these topics in more depth and apply them to real-world datasets.
这些教程将通过完整的示例向您介绍这些主题,然后在练习中,您将更深入地探索这些主题并将它们应用到现实世界的数据集。
Let's get started!
让我们开始吧!
What is Deep Learning?
什么是深度学习?
Some of the most impressive advances in artificial intelligence in recent years have been in the field of deep learning. Natural language translation, image recognition, and game playing are all tasks where deep learning models have neared or even exceeded human-level performance.
近年来,人工智能领域最令人印象深刻的一些进展出现在深度学习领域。 自然语言翻译、图像识别和游戏都是深度学习模型已经接近甚至超过人类水平的表现。
So what is deep learning? Deep learning is an approach to machine learning characterized by deep stacks of computations. This depth of computation is what has enabled deep learning models to disentangle the kinds of complex and hierarchical patterns found in the most challenging real-world datasets.
那么什么是深度学习呢? 深度学习是一种以深度计算堆栈为特征的机器学习方法。 这种计算深度使得深度学习模型能够理清最具挑战性的现实数据集中发现的各种复杂和分层模式。
Through their power and scalability neural networks have become the defining model of deep learning. Neural networks are composed of neurons, where each neuron individually performs only a simple computation. The power of a neural network comes instead from the complexity of the connections these neurons can form.
凭借其强大功能和可扩展性,神经网络已成为深度学习的定义模型。 神经网络由神经元组成,其中每个神经元单独执行简单的计算。 神经网络的力量来自于这些神经元可以形成的连接的复杂性。
The Linear Unit
线性单元
So let's begin with the fundamental component of a neural network: the individual neuron. As a diagram, a neuron (or unit) with one input looks like:
让我们从神经网络的基本组成部分开始:单个神经元。 如图所示,具有一个输入的神经元(或单元)如下所示:
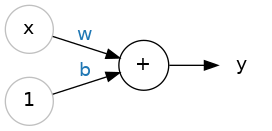
The Linear Unit: $y = w x + b$
The input is x. Its connection to the neuron has a weight which is w. Whenever a value flows through a connection, you multiply the value by the connection's weight. For the input x, what reaches the neuron is w * x. A neural network "learns" by modifying its weights.
输入是x。 它与神经元的连接有一个权重,即w。 每当一个值流经连接时,您就将该值乘以连接的权重。 对于输入x,到达神经元的是w * x。 神经网络通过修改其权重来学习。
The b is a special kind of weight we call the bias. The bias doesn't have any input data associated with it; instead, we put a 1 in the diagram so that the value that reaches the neuron is just b (since 1 * b = b). The bias enables the neuron to modify the output independently of its inputs.
b是一种特殊的权重,我们称之为偏差。 该偏差没有任何与之相关的输入数据; 相反,我们在图中放置1,以便到达神经元的值只是b(因为1 * b = b)。 偏差使神经元能够独立于其输入来修改输出。
The y is the value the neuron ultimately outputs. To get the output, the neuron sums up all the values it receives through its connections. This neuron's activation is y = w * x + b, or as a formula $y = w x + b$.
y是神经元最终输出的值。 为了获得输出,神经元将通过其连接接收到的所有值相加。 该神经元的激活为y = w * x + b,或公式为 $y = w x + b$。
Does the formula $y=w x + b$ look familiar?
公式 $y=w x + b$ 看起来很熟悉吗?
It's an equation of a line! It's the slope-intercept equation, where $w$ is the slope and $b$ is the y-intercept.
这是一个直线方程! 这是斜率截距方程,其中 $w$ 是斜率,$b$ 是 y 轴截距。
Example - The Linear Unit as a Model
示例 - 线性单元作为模型
Though individual neurons will usually only function as part of a larger network, it's often useful to start with a single neuron model as a baseline. Single neuron models are linear models.
尽管单个神经元通常仅作为较大网络的一部分发挥作用,但从单个神经元模型作为基础开始通常很有用。 单神经元模型是线性模型。
Let's think about how this might work on a dataset like 80 Cereals. Training a model with 'sugars' (grams of sugars per serving) as input and 'calories' (calories per serving) as output, we might find the bias is b=90 and the weight is w=2.5. We could estimate the calorie content of a cereal with 5 grams of sugar per serving like this:
让我们考虑一下这如何适用于像 80 Cereals 这样的数据集。 使用糖(每份的糖克数)作为输入和卡路里(每份的卡路里)作为输出来训练模型,我们可能会发现偏差为b=90,权重为w=2.5。 我们可以这样估算每份含 5 克糖的麦片的卡路里含量:

And, checking against our formula, we have $calories = 2.5 \times 5 + 90 = 102.5$, just like we expect.
并且,检查我们的公式,我们有 $calories = 2.5 \times 5 + 90 = 102.5$,就像我们预期的那样。
Multiple Inputs
多个输入
The 80 Cereals dataset has many more features than just 'sugars'. What if we wanted to expand our model to include things like fiber or protein content? That's easy enough. We can just add more input connections to the neuron, one for each additional feature. To find the output, we would multiply each input to its connection weight and then add them all together.
80 Cereals 数据集具有的特征远不止“糖”。 如果我们想扩展我们的模型以包含纤维或蛋白质含量等内容该怎么办? 这很容易。 我们可以向神经元添加更多输入连接,每个附加功能对应一个输入连接。 为了找到输出,我们将每个输入乘以其连接权重,然后将它们全部加在一起。
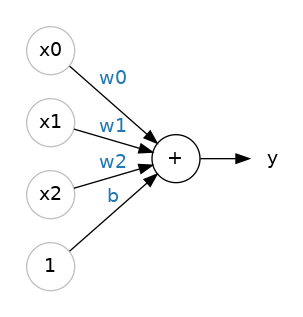
The formula for this neuron would be $y = w_0 x_0 + w_1 x_1 + w_2 x_2 + b$. A linear unit with two inputs will fit a plane, and a unit with more inputs than that will fit a hyperplane.
该神经元的公式为 $y = w_0 x_0 + w_1 x_1 + w_2 x_2 + b$。 具有两个输入的线性单元将拟合一个平面,而具有更多输入的单元将适合一个超平面。
Linear Units in Keras
Keras 中的线性单位
The easiest way to create a model in Keras is through keras.Sequential, which creates a neural network as a stack of layers. We can create models like those above using a dense layer (which we'll learn more about in the next lesson).
在 Keras 中创建模型的最简单方法是通过keras.Sequential,它将神经网络创建为层堆栈。 我们可以使用Dense层创建类似上面的模型(我们将在下一课中详细了解)。
We could define a linear model accepting three input features ('sugars', 'fiber', and 'protein') and producing a single output ('calories') like so:
我们可以定义一个线性模型,接受三个输入特征(糖、纤维和蛋白质)并产生单个输出(卡路里),如下所示:
from tensorflow import keras
from tensorflow.keras import layers
# Create a network with 1 linear unit
# 创建一个具有 1 个线性单元的神经网络
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])2024-02-13 20:22:35.898142: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-02-13 20:22:35.976317: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-02-13 20:22:35.976389: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-02-13 20:22:35.978789: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-02-13 20:22:35.989154: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-02-13 20:22:35.990907: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-13 20:22:39.052589: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRTWith the first argument, units, we define how many outputs we want. In this case we are just predicting 'calories', so we'll use units=1.
通过第一个参数units,我们定义了我们想要的输出数量。 在本例中,我们只是预测卡路里,因此我们将使用units=1。
With the second argument, input_shape, we tell Keras the dimensions of the inputs. Setting input_shape=[3] ensures the model will accept three features as input ('sugars', 'fiber', and 'protein').
通过第二个参数input_shape,我们告诉 Keras 输入的维度。 设置input_shape=[3]可确保模型接受三个特征作为输入(糖、纤维和蛋白质)。
This model is now ready to be fit to training data!
该模型现在已准备好适合训练数据!
Why is input_shape a Python list?
The data we'll use in this course will be tabular data, like in a Pandas dataframe. We'll have one input for each feature in the dataset. The features are arranged by column, so we'll always have input_shape=[num_columns].
The reason Keras uses a list here is to permit use of more complex datasets. Image data, for instance, might need three dimensions: [height, width, channels].
为什么input_shape是一个Python列表?
我们在本课程中使用的数据将是表格数据,例如 Pandas 数据框中的数据。 我们将为数据集中的每个特征提供一个输入。 这些特征按列排列,因此我们始终有 input_shape=[num_columns]。
Keras 在这里使用列表的原因是允许使用更复杂的数据集。 例如,图像数据可能需要三个维度:[高度、宽度、通道]。
Your Turn
到你了
Define a linear model for the Red Wine Quality dataset.
定义一个线性模型用于红酒质量数据集。