Introduction
介绍
Now that you know how to access and examine a dataset, you're ready to write your first SQL query! As you'll soon see, SQL queries will help you sort through a massive dataset, to retrieve only the information that you need.
现在您已经知道如何访问和检查数据集,您就可以编写您的第一个 SQL 查询了! 您很快就会看到,SQL 查询将帮助您对海量数据集进行排序,以仅检索您需要的信息。
We'll begin by using the keywords SELECT, FROM, and WHERE to get data from specific columns based on conditions you specify.
我们将首先使用关键字 SELECT、FROM 和 WHERE 根据您指定的条件从特定列获取数据。
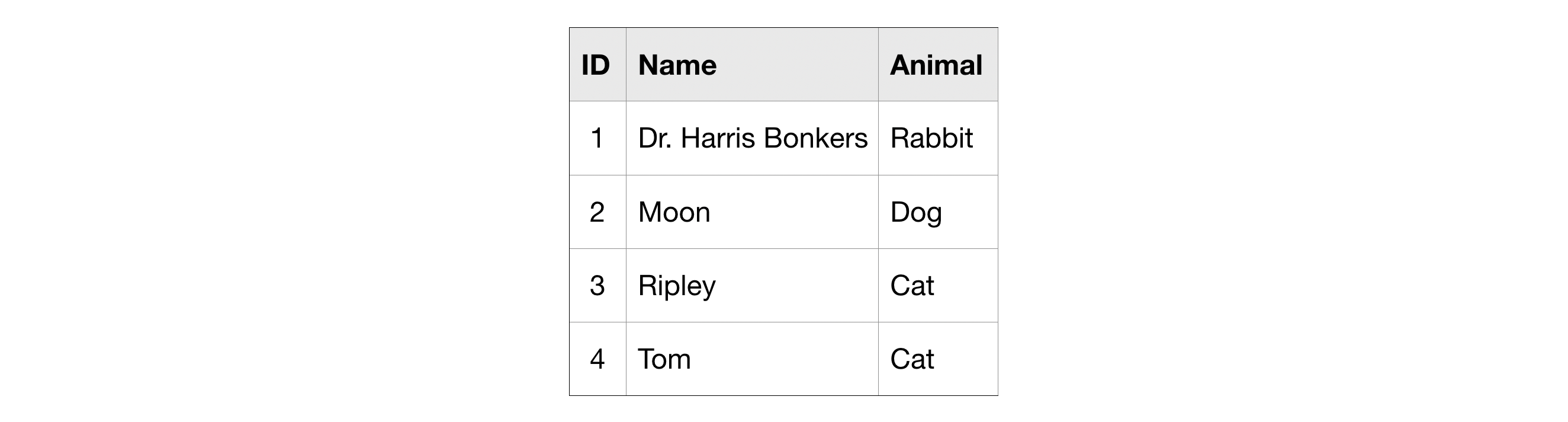
For clarity, we'll work with a small imaginary dataset pet_records which contains just one table, called pets.
为了清楚起见,我们将使用一个小的假想数据集pet_records,其中仅包含一个名为pets的表。
SELECT ... FROM
The most basic SQL query selects a single column from a single table. To do this,
最基本的 SQL 查询从单个表中选择单个列。 去做这个,
- specify the column you want after the word SELECT, and then
- 在 SELECT 一词后指定所需的列,然后
- specify the table after the word FROM.
- 在单词 FROM 之后指定表格。
For instance, to select the Name column (from the pets table in the pet_records database in the bigquery-public-data project), our query would appear as follows:
例如,要选择Name列(来自bigquery-public-data项目中pet_records数据库中的pets表),我们的查询将如下所示:

Note that when writing an SQL query, the argument we pass to FROM is not in single or double quotation marks (' or "). It is in backticks (`).
请注意,在编写 SQL 查询时,我们传递给 FROM 的参数 不是 使用单引号或双引号(' 或 ")。而是使用反引号 (`)。
WHERE ...
BigQuery datasets are large, so you'll usually want to return only the rows meeting specific conditions. You can do this using the WHERE clause.
BigQuery 数据集很大,因此您通常只想返回满足特定条件的行。 您可以使用 WHERE 子句来执行此操作。
The query below returns the entries from the Name column that are in rows where the Animal column has the text 'Cat'.
下面的查询返回Animal字段含有文本Cat的行中的Name字段。

Example: What are all the U.S. cities in the OpenAQ dataset?
示例:OpenAQ 数据集中有哪些美国城市?
Now that you've got the basics down, let's work through an example with a real dataset. We'll use an OpenAQ dataset about air quality.
现在您已经掌握了基础知识,让我们通过一个真实数据集的示例来进行操作。 我们将使用有关空气质量的 OpenAQ 数据集。
First, we'll set up everything we need to run queries and take a quick peek at what tables are in our database. (Since you learned how to do this in the previous tutorial, we have hidden the code. But if you'd like to take a peek, you need only click on the "Code" button below.)
首先,我们将设置运行查询所需的一切,并快速浏览数据库中的表。 ( 由于您在上一教程中学习了如何执行此操作,因此我们隐藏了代码。但是如果您想看一下,只需单击下面的“代码”按钮即可。 )
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "openaq" dataset
dataset_ref = client.dataset("openaq", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# List all the tables in the "openaq" dataset
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset (there's only one!)
for table in tables:
print(table.table_id)/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
global_air_qualityThe dataset contains only one table, called global_air_quality. We'll fetch the table and take a peek at the first few rows to see what sort of data it contains. (Again, we have hidden the code. To take a peek, click on the "Code" button below.)
该数据集仅包含一张表,名为global_air_quality。 我们将获取该表并查看前几行,看看它包含什么类型的数据。 ( _同样,我们隐藏了代码。要查看,请单击下面的MARKDOWN_HASH06e004ef21414c06d3e4ff2cefaf6a04MARKDOWNHASH按钮。 )
# Construct a reference to the "global_air_quality" table
table_ref = dataset_ref.table("global_air_quality")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the "global_air_quality" table
client.list_rows(table, max_results=5).to_dataframe()| location | city | country | pollutant | value | timestamp | unit | source_name | latitude | longitude | averaged_over_in_hours | location_geom | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Borówiec, ul. Drapałka | Borówiec | PL | bc | 0.85217 | 2022-04-28 07:00:00+00:00 | µg/m³ | GIOS | 1.0 | 52.276794 | 17.074114 | POINT(52.276794 1) |
| 1 | Kraków, ul. Bulwarowa | Kraków | PL | bc | 0.91284 | 2022-04-27 23:00:00+00:00 | µg/m³ | GIOS | 1.0 | 50.069308 | 20.053492 | POINT(50.069308 1) |
| 2 | Płock, ul. Reja | Płock | PL | bc | 1.41000 | 2022-03-30 04:00:00+00:00 | µg/m³ | GIOS | 1.0 | 52.550938 | 19.709791 | POINT(52.550938 1) |
| 3 | Elbląg, ul. Bażyńskiego | Elbląg | PL | bc | 0.33607 | 2022-05-03 13:00:00+00:00 | µg/m³ | GIOS | 1.0 | 54.167847 | 19.410942 | POINT(54.167847 1) |
| 4 | Piastów, ul. Pułaskiego | Piastów | PL | bc | 0.51000 | 2022-05-11 05:00:00+00:00 | µg/m³ | GIOS | 1.0 | 52.191728 | 20.837489 | POINT(52.191728 1) |
Everything looks good! So, let's put together a query. Say we want to select all the values from the city column that are in rows where the country column is 'US' (for "United States").
一切看起来都不错! 那么,让我们组合一个查询。 假设我们要从city列中选择country列为US(代表美国)的行中的所有值。
# Query to select all the items from the "city" column where the "country" column is 'US'
query = """
SELECT city
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""Take the time now to ensure that this query lines up with what you learned above.
现在花点时间确保该查询与您在上面学到的内容相符。
Submitting the query to the dataset
向数据集提交查询
We're ready to use this query to get information from the OpenAQ dataset. As in the previous tutorial, the first step is to create a Client object.
我们已准备好使用此查询从 OpenAQ 数据集中获取信息。 与上一个教程一样,第一步是创建一个 Client 对象。
# Create a "Client" object
client = bigquery.Client()/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)We begin by setting up the query with the query() method. We run the method with the default parameters, but this method also allows us to specify more complicated settings that you can read about in the documentation. We'll revisit this later.
我们首先使用 query() 方法设置查询。 我们使用默认参数运行该方法,但此方法还允许我们指定更复杂的设置,您可以在文档中了解详情。 我们稍后会再讨论这个问题。
# Set up the query
query_job = client.query(query)Next, we run the query and convert the results to a pandas DataFrame.
接下来,我们运行查询并将结果转换为 pandas DataFrame。
# API request - run the query, and return a pandas DataFrame
us_cities = query_job.to_dataframe()Now we've got a pandas DataFrame called us_cities, which we can use like any other DataFrame.
现在我们有了一个名为us_cities的 pandas DataFrame,我们可以像任何其他 DataFrame 一样使用它。
# What five cities have the most measurements?
us_cities.city.value_counts().head()city
Phoenix-Mesa-Scottsdale 39414
Los Angeles-Long Beach-Santa Ana 27479
Riverside-San Bernardino-Ontario 26887
New York-Northern New Jersey-Long Island 25417
San Francisco-Oakland-Fremont 22710
Name: count, dtype: int64More queries
更多查询
If you want multiple columns, you can select them with a comma between the names:
如果您想要多个列,可以在名称之间添加逗号来选择它们:
query = """
SELECT city, country
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""query_job = client.query(query)
us_city_county = query_job.to_dataframe()
us_city_county.value_counts().head()city country
Phoenix-Mesa-Scottsdale US 39414
Los Angeles-Long Beach-Santa Ana US 27479
Riverside-San Bernardino-Ontario US 26887
New York-Northern New Jersey-Long Island US 25417
San Francisco-Oakland-Fremont US 22710
Name: count, dtype: int64You can select all columns with a * like this:
您可以使用*来选择所有列,如下所示:
query = """
SELECT *
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""query_job = client.query(query)
us_city_county = query_job.to_dataframe()
us_city_county.head()| location | city | country | pollutant | value | timestamp | unit | source_name | latitude | longitude | averaged_over_in_hours | location_geom | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Seattle-10th & Welle | Seattle-Tacoma-Bellevue | US | bc | 1.30 | 2022-05-03 08:00:00+00:00 | µg/m³ | AirNow | 1.0 | 47.597222 | -122.319722 | POINT(47.597222 1) |
| 1 | Portland Humboldt Sc | Portland-Vancouver-Beaverton | US | bc | 0.32 | 2022-04-28 13:00:00+00:00 | µg/m³ | AirNow | 1.0 | 45.558081 | -122.670985 | POINT(45.558081 1) |
| 2 | HARRINGTON BCH | Milwaukee-Waukesha-West Allis | US | bc | 0.21 | 2022-04-29 12:00:00+00:00 | µg/m³ | AirNow | 1.0 | 43.498100 | -87.810000 | POINT(43.4981 1) |
| 3 | HU-Beltsville | Washington-Arlington-Alexandria | US | bc | 0.10 | 2022-04-29 17:00:00+00:00 | µg/m³ | AirNow | 1.0 | 39.055302 | -76.878304 | POINT(39.055302 1) |
| 4 | McMillan Reservoir | Washington-Arlington-Alexandria | US | bc | 0.30 | 2022-05-13 16:00:00+00:00 | µg/m³ | AirNow | 1.0 | 38.921848 | -77.013176 | POINT(38.921848 1) |
Q&A: Notes on formatting
问答:格式化注意事项
The formatting of the SQL query might feel unfamiliar. If you have any questions, you can ask in the comments section at the bottom of this page. Here are answers to two common questions:
SQL 查询的格式可能会让人感到陌生。 如果您有任何疑问,可以在本页底部的评论部分提问。 以下是两个常见问题的解答:
Question: What's up with the triple quotation marks (""")?
问题:三引号 (""") 是怎么回事?
Answer: These tell Python that everything inside them is a single string, even though we have line breaks in it. The line breaks aren't necessary, but they make it easier to read your query.
答案:这些告诉 Python 其中的所有内容都是一个字符串,即使其中有换行符。 换行符不是必需的,但它们使您的查询更容易阅读。
Question: Do you need to capitalize SELECT and FROM?
问题:SELECT 和 FROM 需要大写吗?
Answer: No, SQL doesn't care about capitalization. However, it's customary to capitalize your SQL commands, and it makes your queries a bit easier to read.
答案:不,SQL 不关心大小写。 然而,习惯上将 SQL 命令大写,这使得查询更容易阅读。
Working with big datasets
处理大数据集
BigQuery datasets can be huge. We allow you to do a lot of computation for free, but everyone has some limit.
BigQuery 数据集可能非常庞大。 我们允许您免费进行大量计算,但每个人都有一些限制。
Each Kaggle user can scan 5TB every 30 days for free. Once you hit that limit, you'll have to wait for it to reset.
每个 Kaggle 用户每 30 天可以免费扫描 5TB。 一旦达到该限制,您将不得不等待它重置。
The biggest dataset currently on Kaggle is 3TB, so you can go through your 30-day limit in a couple queries if you aren't careful.
目前 Kaggle 上最大的数据集 为 3TB,因此,如果您不小心,您可能会在几次查询中就会超出 30 天的限制。
Don't worry though: we'll teach you how to avoid scanning too much data at once, so that you don't run over your limit.
不过不用担心:我们将教您如何避免一次扫描太多数据,这样您就不会超出限制。
To begin,you can estimate the size of any query before running it. Here is an example using the (very large!) Hacker News dataset. To see how much data a query will scan, we create a QueryJobConfig object and set the dry_run parameter to True.
首先,您可以在运行任何查询之前估计其大小。 这是使用(非常大!)黑客新闻数据集的示例。 要查看查询将扫描多少数据,我们创建一个QueryJobConfig对象并将dry_run参数设置为True。
# Query to get the score column from every row where the type column has value "job"
query = """
SELECT score, title
FROM `bigquery-public-data.hacker_news.full`
WHERE type = "job"
"""
# Create a QueryJobConfig object to estimate size of query without running it
dry_run_config = bigquery.QueryJobConfig(dry_run=True)
# API request - dry run query to estimate costs
dry_run_query_job = client.query(query, job_config=dry_run_config)
print("This query will process {} Mega bytes.".format(round(dry_run_query_job.total_bytes_processed/1024/1024,2)))This query will process 468.09 Mega bytes.You can also specify a parameter when running the query to limit how much data you are willing to scan. Here's an example with a low limit.
您还可以在运行查询时指定一个参数来限制您愿意扫描的数据量。 这是一个具有下限的示例。
# Only run the query if it's less than 1 MB
ONE_MB = 1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_MB)
# Set up the query (will only run if it's less than 1 MB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
safe_query_job.to_dataframe()---------------------------------------------------------------------------
InternalServerError Traceback (most recent call last)
Cell In[13], line 9
6 safe_query_job = client.query(query, job_config=safe_config)
8 # API request - try to run the query, and return a pandas DataFrame
----> 9 safe_query_job.to_dataframe()
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1887, in QueryJob.to_dataframe(self, bqstorage_client, dtypes, progress_bar_type, create_bqstorage_client, max_results, geography_as_object, bool_dtype, int_dtype, float_dtype, string_dtype, date_dtype, datetime_dtype, time_dtype, timestamp_dtype)
1721 def to_dataframe(
1722 self,
1723 bqstorage_client: Optional["bigquery_storage.BigQueryReadClient"] = None,
(...)
1736 timestamp_dtype: Union[Any, None] = None,
1737 ) -> "pandas.DataFrame":
1738 """Return a pandas DataFrame from a QueryJob
1739
1740 Args:
(...)
1885 :mod:shapely library cannot be imported.
1886 """
-> 1887 query_result = wait_for_query(self, progress_bar_type, max_results=max_results)
1888 return query_result.to_dataframe(
1889 bqstorage_client=bqstorage_client,
1890 dtypes=dtypes,
(...)
1901 timestamp_dtype=timestamp_dtype,
1902 )
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/_tqdm_helpers.py:107, in wait_for_query(query_job, progress_bar_type, max_results)
103 progress_bar = get_progress_bar(
104 progress_bar_type, "Query is running", default_total, "query"
105 )
106 if progress_bar is None:
--> 107 return query_job.result(max_results=max_results)
109 i = 0
110 while True:
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1590, in QueryJob.result(self, page_size, max_results, retry, timeout, start_index, job_retry)
1587 if retry_do_query is not None and job_retry is not None:
1588 do_get_result = job_retry(do_get_result)
-> 1590 do_get_result()
1592 except exceptions.GoogleAPICallError as exc:
1593 exc.message = _EXCEPTION_FOOTER_TEMPLATE.format(
1594 message=exc.message, location=self.location, job_id=self.job_id
1595 )
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:293, in Retry.__call__..retry_wrapped_func(*args, **kwargs)
289 target = functools.partial(func, *args, **kwargs)
290 sleep_generator = exponential_sleep_generator(
291 self._initial, self._maximum, multiplier=self._multiplier
292 )
--> 293 return retry_target(
294 target,
295 self._predicate,
296 sleep_generator,
297 timeout=self._timeout,
298 on_error=on_error,
299 )
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:153, in retry_target(target, predicate, sleep_generator, timeout, on_error, exception_factory, **kwargs)
149 # pylint: disable=broad-except
150 # This function explicitly must deal with broad exceptions.
151 except Exception as exc:
152 # defer to shared logic for handling errors
--> 153 _retry_error_helper(
154 exc,
155 deadline,
156 sleep,
157 error_list,
158 predicate,
159 on_error,
160 exception_factory,
161 timeout,
162 )
163 # if exception not raised, sleep before next attempt
164 time.sleep(sleep)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_base.py:212, in _retry_error_helper(exc, deadline, next_sleep, error_list, predicate_fn, on_error_fn, exc_factory_fn, original_timeout)
206 if not predicate_fn(exc):
207 final_exc, source_exc = exc_factory_fn(
208 error_list,
209 RetryFailureReason.NON_RETRYABLE_ERROR,
210 original_timeout,
211 )
--> 212 raise final_exc from source_exc
213 if on_error_fn is not None:
214 on_error_fn(exc)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:144, in retry_target(target, predicate, sleep_generator, timeout, on_error, exception_factory, **kwargs)
142 for sleep in sleep_generator:
143 try:
--> 144 result = target()
145 if inspect.isawaitable(result):
146 warnings.warn(_ASYNC_RETRY_WARNING)
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1579, in QueryJob.result..do_get_result()
1576 self._retry_do_query = retry_do_query
1577 self._job_retry = job_retry
-> 1579 super(QueryJob, self).result(retry=retry, timeout=timeout)
1581 # Since the job could already be "done" (e.g. got a finished job
1582 # via client.get_job), the superclass call to done() might not
1583 # set the self._query_results cache.
1584 if self._query_results is None or not self._query_results.complete:
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:971, in _AsyncJob.result(self, retry, timeout)
968 self._begin(retry=retry, timeout=timeout)
970 kwargs = {} if retry is DEFAULT_RETRY else {"retry": retry}
--> 971 return super(_AsyncJob, self).result(timeout=timeout, **kwargs)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/future/polling.py:261, in PollingFuture.result(self, timeout, retry, polling)
256 self._blocking_poll(timeout=timeout, retry=retry, polling=polling)
258 if self._exception is not None:
259 # pylint: disable=raising-bad-type
260 # Pylint doesn't recognize that this is valid in this case.
--> 261 raise self._exception
263 return self._result
InternalServerError: 500 Query exceeded limit for bytes billed: 1000000. 491782144 or higher required.; reason: bytesBilledLimitExceeded, message: Query exceeded limit for bytes billed: 1000000. 491782144 or higher required.
Location: US
Job ID: 66b495bd-64a7-426f-b619-d595276a6237 In this case, the query was cancelled, because the limit of 1 MB was exceeded. However, we can increase the limit to run the query successfully!
在本例中,查询被取消,因为超出了 1 MB 的限制。 但是,我们可以增加限制以成功运行查询!
# Only run the query if it's less than 1 GB
ONE_GB = 1000*1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_GB)
# Set up the query (will only run if it's less than 1 GB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
job_post_scores = safe_query_job.to_dataframe()
# Print average score for job posts
job_post_scores.score.mean()1.700647369595952Your turn
到你了
Writing SELECT statements is the key to using SQL. So try your new skills!
编写SELECT语句是使用SQL的关键。 所以尝试你的新技能!