Introduction
介绍
Now that you can select raw data, you're ready to learn how to group your data and count things within those groups. This can help you answer questions like:
现在您可以选择原始数据,您已经准备好学习如何对数据进行分组并对这些组中的内容进行计数。 这可以帮助您回答以下问题:
- How many of each kind of fruit has our store sold?
- 我们店每种水果销售了多少?
- How many species of animal has the vet office treated?
- 兽医办公室治疗过多少种动物?
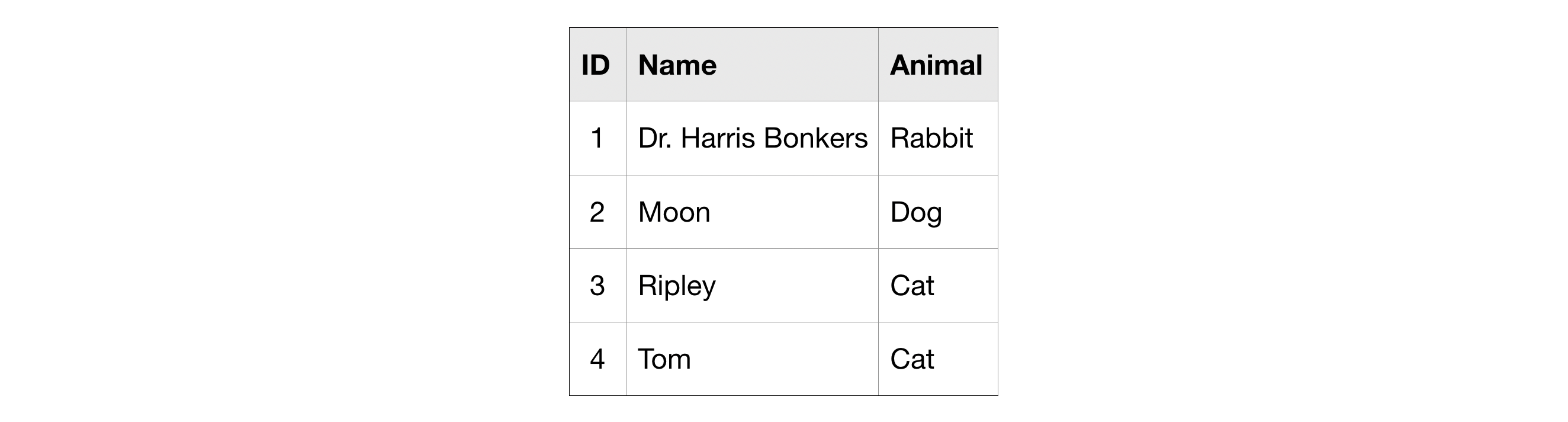
To do this, you'll learn about three new techniques: GROUP BY, HAVING and COUNT(). Once again, we'll use this made-up table of information on pets.
为此,您将了解三种新技术:GROUP BY、HAVING 和 COUNT()。 我们将再次使用这张虚构的宠物信息表。
COUNT()
COUNT(), as you may have guessed from the name, returns a count of things. If you pass it the name of a column, it will return the number of entries in that column.
COUNT(),正如您可能从名称中猜到的那样,它返回事物的计数。 如果您向其传递列名,它将返回该列中的条目数。
For instance, if we SELECT the COUNT() of the ID column in the pets table, it will return 4, because there are 4 ID's in the table.
例如,如果我们SELECTpets表中ID列的COUNT(),它将返回4,因为表中有4个ID。

COUNT() is an example of an aggregate function, which takes many values and returns one. (Other examples of aggregate functions include SUM(), AVG(), MIN(), and MAX().) As you'll notice in the picture above, aggregate functions introduce strange column names (like f0__). Later in this tutorial, you'll learn how to change the name to something more descriptive.
COUNT() 是 聚合函数 的一个示例,它接受多个值并返回一个值。 (聚合函数的其他示例包括 SUM()、AVG()、MIN() 和 MAX()。)正如您在上图中注意到的那样 ,聚合函数引入了新的列名称(如f0__)。 在本教程的后面部分,您将学习如何将名称更改为更具描述性的名称。
GROUP BY
GROUP BY takes the name of one or more columns, and treats all rows with the same value in that column as a single group when you apply aggregate functions like COUNT().
GROUP BY 采用一个或多个列的名称,并在应用 COUNT() 等聚合函数时将该列中具有相同值的所有行视为单个组。
For example, say we want to know how many of each type of animal we have in the pets table. We can use GROUP BY to group together rows that have the same value in the Animal column, while using COUNT() to find out how many ID's we have in each group.
例如,假设我们想知道pets表中每种动物的数量。 我们可以使用 GROUP BY 将Animal列中具有相同值的行分组在一起,同时使用 COUNT() 找出每个组中有多少个 ID。

It returns a table with three rows (one for each distinct animal). We can see that the pets table contains 1 rabbit, 1 dog, and 2 cats.
它返回一个包含三行的表(每行代表一种不同的动物)。 我们可以看到pets表包含 1 只兔子、1 只狗和 2 只猫。
GROUP BY ... HAVING
HAVING is used in combination with GROUP BY to ignore groups that don't meet certain criteria.
HAVING 与 GROUP BY 结合使用,以忽略不满足特定条件的组。
So this query, for example, will only include groups that have more than one ID in them.
例如,此查询将仅包含其中包含多个 ID 的组。

Since only one group meets the specified criterion, the query will return a table with only one row.
由于只有一组满足指定条件,因此查询将返回一张只有一行的表。
Example: Which Hacker News comments generated the most discussion?
示例:哪些黑客新闻评论引起了最多的讨论?
Ready to see an example on a real dataset? The Hacker News dataset contains information on stories and comments from the Hacker News social networking site.
准备好查看真实数据集的示例了吗? 黑客新闻数据集包含有关黑客新闻社交网站的故事和评论的信息。
We'll work with the full table and begin by printing the first few rows. (We have hidden the corresponding code. To take a peek, click on the "Code" button below.)
我们将使用完整表并从打印前几行开始。 (_我们已经隐藏了相应的代码。要查看,请点击下面的MARKDOWN_HASH06e004ef21414c06d3e4ff2cefaf6a04MARKDOWNHASH按钮。)
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "full" table
table_ref = dataset_ref.table("full")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)| title | url | text | dead | by | score | time | timestamp | type | id | parent | descendants | ranking | deleted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | None | If the crocodile looked him up on Google, we b... | <NA> | raxxorrax | <NA> | 1633421535 | 2021-10-05 08:12:15+00:00 | comment | 28756662 | 28750122 | <NA> | <NA> | <NA> |
| 1 | None | None | What exactly are you looking for? I think Pyto... | <NA> | abiro | <NA> | 1569141387 | 2019-09-22 08:36:27+00:00 | comment | 21040311 | 21040141 | <NA> | <NA> | <NA> |
| 2 | None | None | Ironically, this very project might help out w... | <NA> | mjevans | <NA> | 1505769703 | 2017-09-18 21:21:43+00:00 | comment | 15279716 | 15276626 | <NA> | <NA> | <NA> |
| 3 | None | None | As you start to gain some experience it can be... | <NA> | every_other | <NA> | 1538575027 | 2018-10-03 13:57:07+00:00 | comment | 18130207 | 18128477 | <NA> | <NA> | <NA> |
| 4 | None | None | That’s what I was referring to, yes. I heard o... | <NA> | manmal | <NA> | 1615664155 | 2021-03-13 19:35:55+00:00 | comment | 26449260 | 26449237 | <NA> | <NA> | <NA> |
Let's use the table to see which comments generated the most replies. Since:
让我们使用该表来查看哪些评论产生了最多的回复。 自从:
- the
parentcolumn indicates the comment that was replied to, and parent列表示已回复的评论,并且- the
idcolumn has the unique ID used to identify each comment, id列具有用于识别每个评论的唯一 ID,
we can GROUP BY the parent column and COUNT() the id column in order to figure out the number of comments that were made as responses to a specific comment. (This might not make sense immediately -- take your time here to ensure that everything is clear!)
我们可以对parent 列 GROUP BY 之后获取id 列的 COUNT() ,以便计算出作为对特定评论的响应而做出的评论数量。 (这可能不会立即有意义 - 请花点时间确保能弄明白一切!)
Furthermore, since we're only interested in popular comments, we'll look at comments with more than ten replies. So, we'll only return groups HAVING more than ten ID's.
此外,由于我们只对热门评论感兴趣,因此我们将查看回复数超过 10 条的评论。 因此,我们只会返回具有超过 10 个 ID 的组。
# Query to select comments that received more than 10 replies
query_popular = """
SELECT parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.full`
GROUP BY parent
HAVING COUNT(id) > 10
"""Now that our query is ready, let's run it and store the results in a pandas DataFrame:
现在我们的查询已准备就绪,让我们运行它并将结果存储在 pandas DataFrame 中:
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_popular, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
popular_comments = query_job.to_dataframe()
# Print the first five rows of the DataFrame
popular_comments.head()| parent | f0_ | |
|---|---|---|
| 0 | 33548134 | 108 |
| 1 | 29176416 | 40 |
| 2 | 13571847 | 80 |
| 3 | 24160473 | 53 |
| 4 | 24038520 | 605 |
Each row in the popular_comments DataFrame corresponds to a comment that received more than ten replies. For instance, the comment with ID 801208 received 56 replies.
popular_comments DataFrame 中的每一行对应于收到十多个回复的评论。 例如,ID 为801208的评论收到56条回复。
Aliasing and other improvements
别名和其他改进
A couple hints to make your queries even better:
有一些小技巧可以让您的查询变得更好:
- The column resulting from
COUNT(id)was calledf0__. That's not a very descriptive name. You can change the name by addingAS NumPostsafter you specify the aggregation. This is called aliasing, and it will be covered in more detail in an upcoming lesson. - 由
COUNT(id)生成的列称为f0__。 这不是一个非常具有描述性的名字。 您可以在指定聚合后通过添加AS NumPosts来更改名称。 这称为别名,将在接下来的课程中更详细地介绍它。 - If you are ever unsure what to put inside the COUNT() function, you can do
COUNT(1)to count the rows in each group. Most people find it especially readable, because we know it's not focusing on other columns. It also scans less data than if supplied column names (making it faster and using less of your data access quota). - 如果您不确定要在 COUNT() 函数中放入什么,您可以执行
COUNT(1)来计算每个组中的行数。 大多数人发现它特别可读,因为我们知道它不关注其他专栏。 它还扫描比提供的列名称更少的数据(使其更快并使用更少的数据访问配额)。
Using these tricks, we can rewrite our query:
使用这些技巧,我们可以重写我们的查询:
# Improved version of earlier query, now with aliasing & improved readability
query_improved = """
SELECT parent, COUNT(1) AS NumPosts
FROM `bigquery-public-data.hacker_news.full`
GROUP BY parent
HAVING COUNT(1) > 10
"""
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_improved, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
improved_df = query_job.to_dataframe()
# Print the first five rows of the DataFrame
improved_df.head()| parent | NumPosts | |
|---|---|---|
| 0 | 33078596 | 117 |
| 1 | 33422129 | 512 |
| 2 | 25143926 | 48 |
| 3 | 25950351 | 55 |
| 4 | 30430041 | 138 |
Now you have the data you want, and it has descriptive names. That's good style.
现在您已经有了所需的数据,并且它具有描述性名称。 这是很好的风格。
Note on using GROUP BY
使用 GROUP BY 的注意事项
Note that because it tells SQL how to apply aggregate functions (like COUNT()), it doesn't make sense to use GROUP BY without an aggregate function. Similarly, if you have any GROUP BY clause, then all variables must be passed to either a
请注意,因为它告诉 SQL 如何应用聚合函数(如 COUNT()),所以在没有聚合函数的情况下使用 GROUP BY 是没有意义的。 类似地,如果您有任何 GROUP BY 子句,则所有变量都必须传递给
- GROUP BY command, or
- GROUP BY 命令,或
- an aggregation function.
- 聚合函数。
Consider the query below:
考虑下面的查询:
query_good = """
SELECT parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.full`
GROUP BY parent
"""query_job = client.query(query_good, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
improved_df = query_job.to_dataframe()
# Print the first five rows of the DataFrame
improved_df.head()| parent | f0_ | |
|---|---|---|
| 0 | 19083886 | 27 |
| 1 | 6071496 | 11 |
| 2 | 10149019 | 11 |
| 3 | 10077005 | 12 |
| 4 | 4381165 | 9 |
Note that there are two variables: parent and id.
请注意,有两个变量:parent和id。
parentwas passed to a GROUP BY command (inGROUP BY parent), andparent被传递给 GROUP BY 命令(在GROUP BY parent中),并且idwas passed to an aggregate function (inCOUNT(id)).id被传递给聚合函数(在COUNT(id)中)。
And this query won't work, because the author column isn't passed to an aggregate function or a GROUP BY clause:
此查询将不起作用,因为author列未传递给聚合函数或 GROUP BY 子句:
query_bad = """
SELECT `by` AS author, parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.full`
GROUP BY parent
"""query_job = client.query(query_bad, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
improved_df = query_job.to_dataframe()
# Print the first five rows of the DataFrame
improved_df.head()---------------------------------------------------------------------------
BadRequest Traceback (most recent call last)
Cell In[8], line 4
1 query_job = client.query(query_bad, job_config=safe_config)
3 # API request - run the query, and convert the results to a pandas DataFrame
----> 4 improved_df = query_job.to_dataframe()
6 # Print the first five rows of the DataFrame
7 improved_df.head()
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1887, in QueryJob.to_dataframe(self, bqstorage_client, dtypes, progress_bar_type, create_bqstorage_client, max_results, geography_as_object, bool_dtype, int_dtype, float_dtype, string_dtype, date_dtype, datetime_dtype, time_dtype, timestamp_dtype)
1721 def to_dataframe(
1722 self,
1723 bqstorage_client: Optional["bigquery_storage.BigQueryReadClient"] = None,
(...)
1736 timestamp_dtype: Union[Any, None] = None,
1737 ) -> "pandas.DataFrame":
1738 """Return a pandas DataFrame from a QueryJob
1739
1740 Args:
(...)
1885 :mod:shapely library cannot be imported.
1886 """
-> 1887 query_result = wait_for_query(self, progress_bar_type, max_results=max_results)
1888 return query_result.to_dataframe(
1889 bqstorage_client=bqstorage_client,
1890 dtypes=dtypes,
(...)
1901 timestamp_dtype=timestamp_dtype,
1902 )
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/_tqdm_helpers.py:107, in wait_for_query(query_job, progress_bar_type, max_results)
103 progress_bar = get_progress_bar(
104 progress_bar_type, "Query is running", default_total, "query"
105 )
106 if progress_bar is None:
--> 107 return query_job.result(max_results=max_results)
109 i = 0
110 while True:
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1590, in QueryJob.result(self, page_size, max_results, retry, timeout, start_index, job_retry)
1587 if retry_do_query is not None and job_retry is not None:
1588 do_get_result = job_retry(do_get_result)
-> 1590 do_get_result()
1592 except exceptions.GoogleAPICallError as exc:
1593 exc.message = _EXCEPTION_FOOTER_TEMPLATE.format(
1594 message=exc.message, location=self.location, job_id=self.job_id
1595 )
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:293, in Retry.__call__..retry_wrapped_func(*args, **kwargs)
289 target = functools.partial(func, *args, **kwargs)
290 sleep_generator = exponential_sleep_generator(
291 self._initial, self._maximum, multiplier=self._multiplier
292 )
--> 293 return retry_target(
294 target,
295 self._predicate,
296 sleep_generator,
297 timeout=self._timeout,
298 on_error=on_error,
299 )
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:153, in retry_target(target, predicate, sleep_generator, timeout, on_error, exception_factory, **kwargs)
149 # pylint: disable=broad-except
150 # This function explicitly must deal with broad exceptions.
151 except Exception as exc:
152 # defer to shared logic for handling errors
--> 153 _retry_error_helper(
154 exc,
155 deadline,
156 sleep,
157 error_list,
158 predicate,
159 on_error,
160 exception_factory,
161 timeout,
162 )
163 # if exception not raised, sleep before next attempt
164 time.sleep(sleep)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_base.py:212, in _retry_error_helper(exc, deadline, next_sleep, error_list, predicate_fn, on_error_fn, exc_factory_fn, original_timeout)
206 if not predicate_fn(exc):
207 final_exc, source_exc = exc_factory_fn(
208 error_list,
209 RetryFailureReason.NON_RETRYABLE_ERROR,
210 original_timeout,
211 )
--> 212 raise final_exc from source_exc
213 if on_error_fn is not None:
214 on_error_fn(exc)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/retry/retry_unary.py:144, in retry_target(target, predicate, sleep_generator, timeout, on_error, exception_factory, **kwargs)
142 for sleep in sleep_generator:
143 try:
--> 144 result = target()
145 if inspect.isawaitable(result):
146 warnings.warn(_ASYNC_RETRY_WARNING)
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/query.py:1579, in QueryJob.result..do_get_result()
1576 self._retry_do_query = retry_do_query
1577 self._job_retry = job_retry
-> 1579 super(QueryJob, self).result(retry=retry, timeout=timeout)
1581 # Since the job could already be "done" (e.g. got a finished job
1582 # via client.get_job), the superclass call to done() might not
1583 # set the self._query_results cache.
1584 if self._query_results is None or not self._query_results.complete:
File ~/.python/current/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:971, in _AsyncJob.result(self, retry, timeout)
968 self._begin(retry=retry, timeout=timeout)
970 kwargs = {} if retry is DEFAULT_RETRY else {"retry": retry}
--> 971 return super(_AsyncJob, self).result(timeout=timeout, **kwargs)
File ~/.python/current/lib/python3.10/site-packages/google/api_core/future/polling.py:261, in PollingFuture.result(self, timeout, retry, polling)
256 self._blocking_poll(timeout=timeout, retry=retry, polling=polling)
258 if self._exception is not None:
259 # pylint: disable=raising-bad-type
260 # Pylint doesn't recognize that this is valid in this case.
--> 261 raise self._exception
263 return self._result
BadRequest: 400 SELECT list expression references column by which is neither grouped nor aggregated at [2:20]; reason: invalidQuery, location: query, message: SELECT list expression references column by which is neither grouped nor aggregated at [2:20]
Location: US
Job ID: 5e37b215-f0da-4bdd-9c45-401441776a8d If make this error, you'll get the error message SELECT list expression references column (column's name) which is neither grouped nor aggregated at.
如果发生此错误,您将收到错误消息SELECT 列表表达式引用的列(列名)既不分组也不聚合。
You may notice the by column in this query is surrounded by backticks. This is because **BY** is a reserved keyword used in clauses including **GROUP BY**. In BigQuery reserved keywords used as identifiers must be quoted in backticks to avoid an error. We also make subsequent references to this column more readable by adding an alias to rename it to author
您可能会注意到此查询中的 by 列被反引号包围。 这是因为 **BY** 是在包括 **GROUP BY** 在内的子句中使用的保留关键字。 在 BigQuery 中,用作标识符的保留关键字必须用反引号引起来,以避免错误。 我们还通过添加别名将其重命名为author`,使后续对该专栏的引用更具可读性。
Your turn
到你了
These aggregations let you write much more interesting queries. Try it yourself with these coding exercises.
这些聚合让您可以编写更有趣的查询。 自己尝试一下这些编码练习。