This notebook is an exercise in the Data Cleaning course. You can reference the tutorial at this link.
In this exercise, you'll apply what you learned in the Parsing dates tutorial.
在本练习中,您将应用在 解析日期 教程中学到的知识。
Setup
设置
The questions below will give you feedback on your work. Run the following cell to set up the feedback system.
以下问题将为您提供有关您工作的反馈。 运行以下单元格来设置反馈系统。
from learntools.core import binder
binder.bind(globals())
from learntools.data_cleaning.ex3 import *
print("Setup Complete")Setup CompleteGet our environment set up
设置我们的环境
The first thing we'll need to do is load in the libraries and dataset we'll be using. We'll be working with a dataset containing information on earthquakes that occured between 1965 and 2016.
我们需要做的第一件事是加载我们将使用的库和数据集。 我们将使用包含 1965 年至 2016 年间发生的地震信息的数据集。
# modules we'll use
import pandas as pd
import numpy as np
import seaborn as sns
import datetime
# read in our data
earthquakes = pd.read_csv("../input/earthquake-database/database.csv")
# set seed for reproducibility
np.random.seed(0)1) Check the data type of our date column
1) 检查日期列的数据类型
You'll be working with the "Date" column from the earthquakes dataframe. Investigate this column now: does it look like it contains dates? What is the dtype of the column?
您将使用earthquakes数据框中的Date列。 现在调查此列:它看起来包含日期吗? 该列的数据类型是什么?
# TODO: Your code here!
earthquakes.head()| Date | Time | Latitude | Longitude | Type | Depth | Depth Error | Depth Seismic Stations | Magnitude | Magnitude Type | ... | Magnitude Seismic Stations | Azimuthal Gap | Horizontal Distance | Horizontal Error | Root Mean Square | ID | Source | Location Source | Magnitude Source | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01/02/1965 | 13:44:18 | 19.246 | 145.616 | Earthquake | 131.6 | NaN | NaN | 6.0 | MW | ... | NaN | NaN | NaN | NaN | NaN | ISCGEM860706 | ISCGEM | ISCGEM | ISCGEM | Automatic |
| 1 | 01/04/1965 | 11:29:49 | 1.863 | 127.352 | Earthquake | 80.0 | NaN | NaN | 5.8 | MW | ... | NaN | NaN | NaN | NaN | NaN | ISCGEM860737 | ISCGEM | ISCGEM | ISCGEM | Automatic |
| 2 | 01/05/1965 | 18:05:58 | -20.579 | -173.972 | Earthquake | 20.0 | NaN | NaN | 6.2 | MW | ... | NaN | NaN | NaN | NaN | NaN | ISCGEM860762 | ISCGEM | ISCGEM | ISCGEM | Automatic |
| 3 | 01/08/1965 | 18:49:43 | -59.076 | -23.557 | Earthquake | 15.0 | NaN | NaN | 5.8 | MW | ... | NaN | NaN | NaN | NaN | NaN | ISCGEM860856 | ISCGEM | ISCGEM | ISCGEM | Automatic |
| 4 | 01/09/1965 | 13:32:50 | 11.938 | 126.427 | Earthquake | 15.0 | NaN | NaN | 5.8 | MW | ... | NaN | NaN | NaN | NaN | NaN | ISCGEM860890 | ISCGEM | ISCGEM | ISCGEM | Automatic |
5 rows × 21 columns
earthquakes.Date.dtypedtype('O')Once you have answered the question above, run the code cell below to get credit for your work.
回答完上述问题后,请运行下面的代码单元格以获得您的工作成果。
# Check your answer (Run this code cell to receive credit!)
q1.check()Correct:
The "Date" column in the earthquakes DataFrame does have dates. The dtype is "object".
# Line below will give you a hint
# q1.hint()2) Convert our date columns to datetime
2) 将日期列转换为日期时间
Most of the entries in the "Date" column follow the same format: "month/day/four-digit year". However, the entry at index 3378 follows a completely different pattern. Run the code cell below to see this.
Date列中的大多数条目都遵循相同的格式:月/日/四位数年份。 然而,索引 3378 处的条目遵循完全不同的模式。 运行下面的代码单元格可以看到这一点。
earthquakes[3376:3381]| Date | Time | Latitude | Longitude | Type | Depth | Depth Error | Depth Seismic Stations | Magnitude | Magnitude Type | ... | Magnitude Seismic Stations | Azimuthal Gap | Horizontal Distance | Horizontal Error | Root Mean Square | ID | Source | Location Source | Magnitude Source | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3376 | 02/22/1975 | 08:36:07 | 51.377 | -179.419 | Earthquake | 48.0 | NaN | NaN | 6.5 | MS | ... | NaN | NaN | NaN | NaN | NaN | USP00009ZR | US | US | US | Reviewed |
| 3377 | 02/22/1975 | 22:04:38 | -24.886 | -179.061 | Earthquake | 375.0 | NaN | NaN | 6.2 | MB | ... | NaN | NaN | NaN | NaN | NaN | USP0000A05 | US | US | US | Reviewed |
| 3378 | 1975-02-23T02:58:41.000Z | 1975-02-23T02:58:41.000Z | 8.017 | 124.075 | Earthquake | 623.0 | NaN | NaN | 5.6 | MB | ... | NaN | NaN | NaN | NaN | NaN | USP0000A09 | US | US | US | Reviewed |
| 3379 | 02/23/1975 | 03:53:36 | -21.727 | -71.356 | Earthquake | 33.0 | NaN | NaN | 5.6 | MB | ... | NaN | NaN | NaN | NaN | NaN | USP0000A0A | US | US | US | Reviewed |
| 3380 | 02/23/1975 | 07:34:11 | -10.879 | 166.667 | Earthquake | 33.0 | NaN | NaN | 5.5 | MS | ... | NaN | NaN | NaN | NaN | NaN | USP0000A0C | US | US | US | Reviewed |
5 rows × 21 columns
This does appear to be an issue with data entry: ideally, all entries in the column have the same format. We can get an idea of how widespread this issue is by checking the length of each entry in the "Date" column.
这似乎确实是数据输入的问题:理想情况下,列中的所有条目都具有相同的格式。 我们可以通过检查Date列中每个条目的长度来了解此问题的普遍程度。
date_lengths = earthquakes.Date.str.len()
date_lengths.value_counts()Date
10 23409
24 3
Name: count, dtype: int64Looks like there are two more rows that has a date in a different format. Run the code cell below to obtain the indices corresponding to those rows and print the data.
看起来还有两行的日期格式不同。 运行下面的代码单元格以获取与这些行对应的索引并打印数据。
indices = np.where([date_lengths == 24])[1]
print('Indices with corrupted data:', indices)
earthquakes.loc[indices]Indices with corrupted data: [ 3378 7512 20650]| Date | Time | Latitude | Longitude | Type | Depth | Depth Error | Depth Seismic Stations | Magnitude | Magnitude Type | ... | Magnitude Seismic Stations | Azimuthal Gap | Horizontal Distance | Horizontal Error | Root Mean Square | ID | Source | Location Source | Magnitude Source | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3378 | 1975-02-23T02:58:41.000Z | 1975-02-23T02:58:41.000Z | 8.017 | 124.075 | Earthquake | 623.0 | NaN | NaN | 5.6 | MB | ... | NaN | NaN | NaN | NaN | NaN | USP0000A09 | US | US | US | Reviewed |
| 7512 | 1985-04-28T02:53:41.530Z | 1985-04-28T02:53:41.530Z | -32.998 | -71.766 | Earthquake | 33.0 | NaN | NaN | 5.6 | MW | ... | NaN | NaN | NaN | NaN | 1.30 | USP0002E81 | US | US | HRV | Reviewed |
| 20650 | 2011-03-13T02:23:34.520Z | 2011-03-13T02:23:34.520Z | 36.344 | 142.344 | Earthquake | 10.1 | 13.9 | 289.0 | 5.8 | MWC | ... | NaN | 32.3 | NaN | NaN | 1.06 | USP000HWQP | US | US | GCMT | Reviewed |
3 rows × 21 columns
pd.to_datetime(earthquakes.Date, format="%m/%d/%Y", errors="coerce")0 1965-01-02
1 1965-01-04
2 1965-01-05
3 1965-01-08
4 1965-01-09
...
23407 2016-12-28
23408 2016-12-28
23409 2016-12-28
23410 2016-12-29
23411 2016-12-30
Name: Date, Length: 23412, dtype: datetime64[ns]Given all of this information, it's your turn to create a new column "date_parsed" in the earthquakes dataset that has correctly parsed dates in it.
有了所有这些信息,就轮到您在earthquakes数据集中创建一个新列date_parsed,该列已正确解析其中的日期。
Note: When completing this problem, you are allowed to (but are not required to) amend the entries in the "Date" and "Time" columns. Do not remove any rows from the dataset.
注意:完成此题时,您可以(但不要求)修改日期和时间列中的条目。 不要从数据集中删除任何行。
earthquakes['Date'].str[:10]0 01/02/1965
1 01/04/1965
2 01/05/1965
3 01/08/1965
4 01/09/1965
...
23407 12/28/2016
23408 12/28/2016
23409 12/28/2016
23410 12/29/2016
23411 12/30/2016
Name: Date, Length: 23412, dtype: object# TODO: Your code here
# earthquakes.loc[3378, "Date"] = "02/23/1975"
# earthquakes.loc[7512, "Date"] = "04/28/1985"
# earthquakes.loc[20650, "Date"] = "03/13/2011"
# earthquakes["date_parsed"] = pd.to_datetime(earthquakes.Date, format="%m/%d/%Y", errors="coerce")
earthquakes["date_parsed"] = pd.to_datetime(earthquakes['Date'].str[:10], format='mixed')
# Check your answer
q2.check()Correct
# Lines below will give you a hint or solution code
# q2.hint()
q2.solution()Solution:
earthquakes.loc[3378, "Date"] = "02/23/1975"
earthquakes.loc[7512, "Date"] = "04/28/1985"
earthquakes.loc[20650, "Date"] = "03/13/2011"
earthquakes['date_parsed'] = pd.to_datetime(earthquakes['Date'], format="%m/%d/%Y")
3) Select the day of the month
3) 选择该月的日期
Create a Pandas Series day_of_month_earthquakes containing the day of the month from the "date_parsed" column.
创建一个 Pandas 系列day_of_month_earthquakes,其中包含date_parsed列中的日期。
# try to get the day of the month from the date column
day_of_month_earthquakes = earthquakes["date_parsed"].dt.day
# Check your answer
q3.check()Correct
# Lines below will give you a hint or solution code
#q3.hint()
q3.solution()Solution:
day_of_month_earthquakes = earthquakes['date_parsed'].dt.day
4) Plot the day of the month to check the date parsing
4) 绘制该月的日期以检查日期解析
Plot the days of the month from your earthquake dataset.
根据地震数据集绘制该月的天数。
# TODO: Your code here!
day_of_month_earthquakes.dropna()
sns.displot(day_of_month_earthquakes, kde=False, bins=31)/opt/conda/lib/python3.10/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
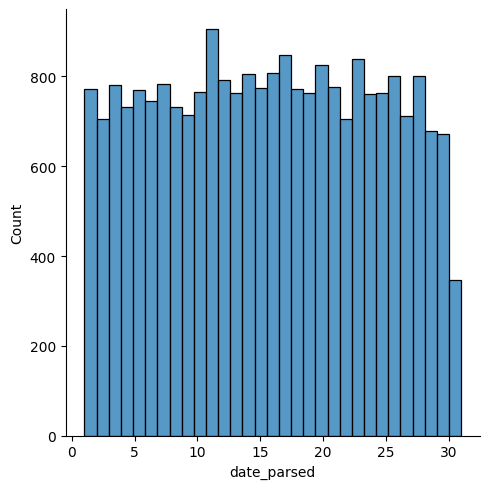
Does the graph make sense to you?
该图表对您有意义吗?
# Check your answer (Run this code cell to receive credit!)
q4.check()Correct:
The graph should make sense: it shows a relatively even distribution in days of the month,which is what we would expect.
该图应该有意义:它显示了该月中几天的相对均匀分布,这正是我们所期望的。
# Line below will give you a hint
q4.hint()Hint:
Remove the missing values, and then use sns.distplot() as follows:
# remove na's
day_of_month_earthquakes = day_of_month_earthquakes.dropna()
# plot the day of the month
sns.distplot(day_of_month_earthquakes, kde=False, bins=31)(Optional) Bonus Challenge
(可选)奖励挑战
For an extra challenge, you'll work with a Smithsonian dataset that documents Earth's volcanoes and their eruptive history over the past 10,000 years
对于额外的挑战,您将使用 Smithsonian 数据集,该数据集记录了地球上的火山及其过去 10,000 年的喷发历史
Run the next code cell to load the data.
运行下一个代码单元以加载数据。
volcanos = pd.read_csv("../input/volcanic-eruptions/database.csv")
volcanos.head()| Number | Name | Country | Region | Type | Activity Evidence | Last Known Eruption | Latitude | Longitude | Elevation (Meters) | Dominant Rock Type | Tectonic Setting | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 210010 | West Eifel Volcanic Field | Germany | Mediterranean and Western Asia | Maar(s) | Eruption Dated | 8300 BCE | 50.170 | 6.85 | 600 | Foidite | Rift Zone / Continental Crust (>25 km) |
| 1 | 210020 | Chaine des Puys | France | Mediterranean and Western Asia | Lava dome(s) | Eruption Dated | 4040 BCE | 45.775 | 2.97 | 1464 | Basalt / Picro-Basalt | Rift Zone / Continental Crust (>25 km) |
| 2 | 210030 | Olot Volcanic Field | Spain | Mediterranean and Western Asia | Pyroclastic cone(s) | Evidence Credible | Unknown | 42.170 | 2.53 | 893 | Trachybasalt / Tephrite Basanite | Intraplate / Continental Crust (>25 km) |
| 3 | 210040 | Calatrava Volcanic Field | Spain | Mediterranean and Western Asia | Pyroclastic cone(s) | Eruption Dated | 3600 BCE | 38.870 | -4.02 | 1117 | Basalt / Picro-Basalt | Intraplate / Continental Crust (>25 km) |
| 4 | 211001 | Larderello | Italy | Mediterranean and Western Asia | Explosion crater(s) | Eruption Observed | 1282 CE | 43.250 | 10.87 | 500 | No Data | Subduction Zone / Continental Crust (>25 km) |
Try parsing the column "Last Known Eruption" from the volcanos dataframe. This column contains a mixture of text ("Unknown") and years both before the common era (BCE, also known as BC) and in the common era (CE, also known as AD).
尝试从 dataframe volcanos 中解析Last Known Eruption列。 此列包含文本(Unknown)以及公元纪元之前(BCE,也称为 BC)和公元纪元(CE,也称为 AD)的年份的混合。
volcanos['Last Known Eruption'].sample(10)764 Unknown
1069 1996 CE
34 1855 CE
489 2016 CE
9 1302 CE
641 Unknown
1115 Unknown
530 3500 BCE
575 Unknown
219 Unknown
Name: Last Known Eruption, dtype: objectvolcanos['Last Known Eruption'] = volcanos['Last Known Eruption'].apply(lambda x: np.nan if x=='Unknown' else x)
volcanos['Last Known Eruption Year'] = (volcanos['Last Known Eruption'].
apply(lambda x: np.nan if pd.isnull(x) else str(x).split(' ')[0] ))
volcanos['Last Known Eruption BCE/CE'] = (volcanos['Last Known Eruption'].
apply(lambda x: np.nan if pd.isnull(x) else str(x).split(' ')[1]))volcanos.head()| Number | Name | Country | Region | Type | Activity Evidence | Last Known Eruption | Latitude | Longitude | Elevation (Meters) | Dominant Rock Type | Tectonic Setting | Last Known Eruption Year | Last Known Eruption BCE/CE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 210010 | West Eifel Volcanic Field | Germany | Mediterranean and Western Asia | Maar(s) | Eruption Dated | 8300 BCE | 50.170 | 6.85 | 600 | Foidite | Rift Zone / Continental Crust (>25 km) | 8300 | BCE |
| 1 | 210020 | Chaine des Puys | France | Mediterranean and Western Asia | Lava dome(s) | Eruption Dated | 4040 BCE | 45.775 | 2.97 | 1464 | Basalt / Picro-Basalt | Rift Zone / Continental Crust (>25 km) | 4040 | BCE |
| 2 | 210030 | Olot Volcanic Field | Spain | Mediterranean and Western Asia | Pyroclastic cone(s) | Evidence Credible | NaN | 42.170 | 2.53 | 893 | Trachybasalt / Tephrite Basanite | Intraplate / Continental Crust (>25 km) | NaN | NaN |
| 3 | 210040 | Calatrava Volcanic Field | Spain | Mediterranean and Western Asia | Pyroclastic cone(s) | Eruption Dated | 3600 BCE | 38.870 | -4.02 | 1117 | Basalt / Picro-Basalt | Intraplate / Continental Crust (>25 km) | 3600 | BCE |
| 4 | 211001 | Larderello | Italy | Mediterranean and Western Asia | Explosion crater(s) | Eruption Observed | 1282 CE | 43.250 | 10.87 | 500 | No Data | Subduction Zone / Continental Crust (>25 km) | 1282 | CE |
(Optional) More practice
(可选)更多练习
If you're interested in graphing time series, check out this tutorial.
如果您对图形化时间序列感兴趣,请查看本教程。
You can also look into passing columns that you know have dates in them the parse_dates argument in read_csv. (The documention is here.) Do note that this method can be very slow, but depending on your needs it may sometimes be handy to use.
您还可以查看将已知包含日期的列传递给read_csv中的parse_dates参数。 (文档在这里。)请注意,此方法可能非常慢,但根据您的需要,有时可能会很方便使用。
Keep going
继续前进
In the next lesson, learn how to work with character encodings.
在下一课中,学习如何使用字符编码。