Introduction
介绍
Recall from the example in the previous lesson that Keras will keep a history of the training and validation loss over the epochs that it is training the model. In this lesson, we're going to learn how to interpret these learning curves and how we can use them to guide model development. In particular, we'll examine at the learning curves for evidence of underfitting and overfitting and look at a couple of strategies for correcting it.
回想一下上一课中的示例,Keras 将保留训练模型期间训练和验证损失的历史记录。 在本课程中,我们将学习如何解释这些学习曲线以及如何使用它们来指导模型开发。 特别是,我们将检查学习曲线中欠拟合和过拟合的证据,并研究一些纠正它的策略。
Interpreting the Learning Curves
解读学习曲线
You might think about the information in the training data as being of two kinds: signal and noise. The signal is the part that generalizes, the part that can help our model make predictions from new data. The noise is that part that is only true of the training data; the noise is all of the random fluctuation that comes from data in the real-world or all of the incidental, non-informative patterns that can't actually help the model make predictions. The noise is the part might look useful but really isn't.
您可能会认为训练数据中的信息有两种:信号和噪声。 信号是用于生成信息的部分,可以帮助我们的模型根据新数据进行预测。 噪声是训练数据中才有的真实部分; 噪声是来自现实世界中的数据的所有随机波动,或者是所有偶然的、非信息性的模式,这些模式实际上不能帮助模型进行预测。 噪音是看起来可能有用但实际上没有用的部分。
We train a model by choosing weights or parameters that minimize the loss on a training set. You might know, however, that to accurately assess a model's performance, we need to evaluate it on a new set of data, the validation data. (You could see our lesson on model validation in Introduction to Machine Learning for a review.)
我们通过选择能够使训练集损失最小化的权重或参数来训练模型。 但是,您可能知道,为了准确评估模型的性能,我们需要在一组新数据(验证数据)上对其进行评估。 (您可以在机器学习简介中查看我们关于模型验证的课程进行回顾。)
When we train a model we've been plotting the loss on the training set epoch by epoch. To this we'll add a plot the validation data too. These plots we call the learning curves. To train deep learning models effectively, we need to be able to interpret them.
当我们训练模型时,我们会逐个纪元绘制训练集上的损失。 为此,我们还将添加验证数据图。 这些图我们称之为学习曲线。 为了有效地训练深度学习模型,我们需要能够解释它们。
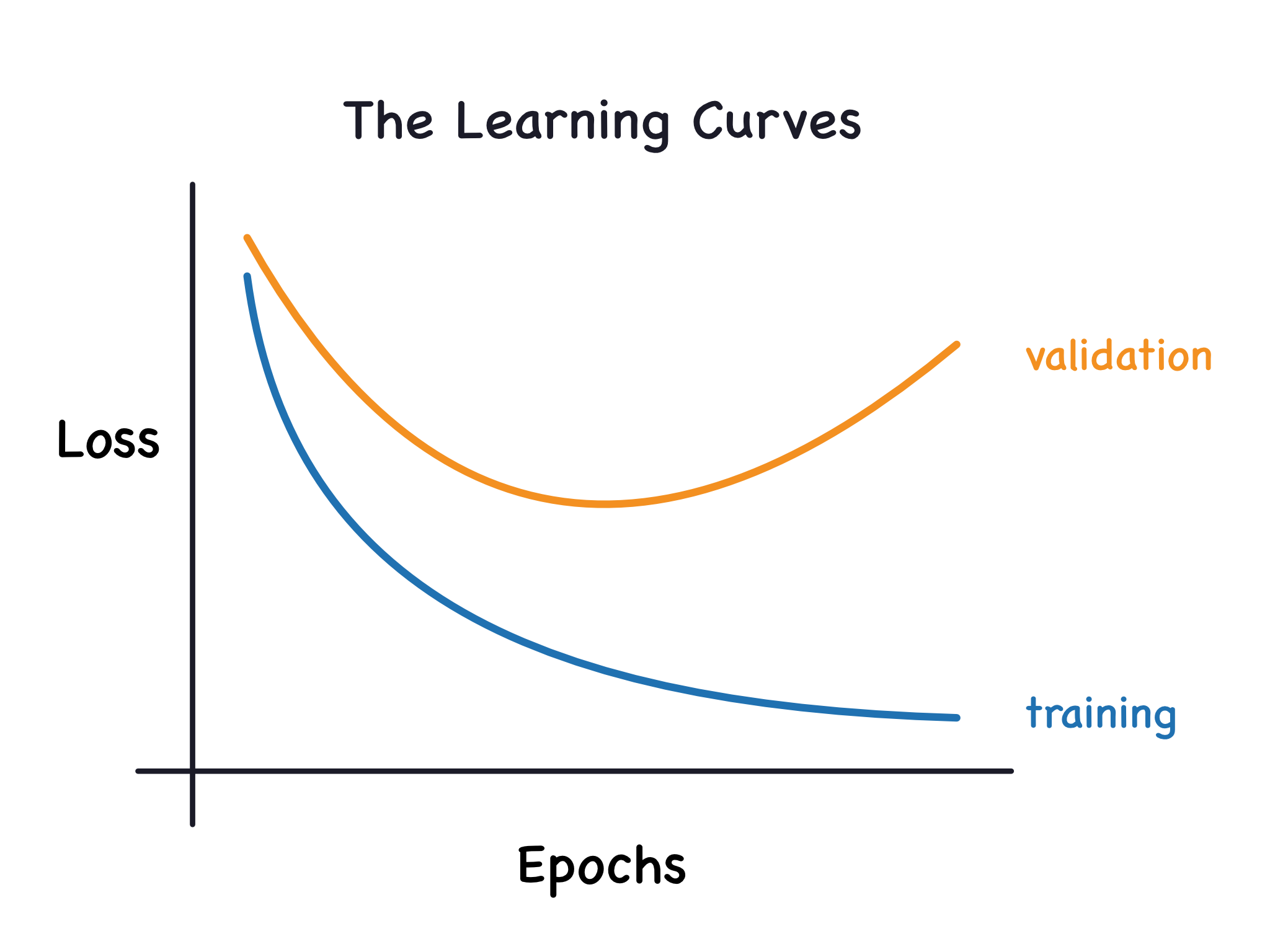
Now, the training loss will go down either when the model learns signal or when it learns noise. But the validation loss will go down only when the model learns signal. (Whatever noise the model learned from the training set won't generalize to new data.) So, when a model learns signal both curves go down, but when it learns noise a gap is created in the curves. The size of the gap tells you how much noise the model has learned.
现在,当模型学习信号或学习噪声时,训练损失都会下降。 但只有当模型学习到信号时,验证损失才会下降。 (无论模型从训练集中学习到什么噪声,都不会推广到新数据。)因此,当模型学习信号时,两条曲线都会下降,但当它学习噪声时,曲线中会产生一个间隙。 间隙的大小告诉您模型学到了多少噪声。
Ideally, we would create models that learn all of the signal and none of the noise. This will practically never happen. Instead we make a trade. We can get the model to learn more signal at the cost of learning more noise. So long as the trade is in our favor, the validation loss will continue to decrease. After a certain point, however, the trade can turn against us, the cost exceeds the benefit, and the validation loss begins to rise.
理想情况下,我们将创建能够学习所有信号而不学习任何噪声的模型。 这实际上永远不会发生。 相反,我们进行权衡。 我们可以让模型以学习更多噪声为代价来学习更多信号。 只要对我们有利,验证损失就会继续减少。 然而,在某一点之后,交易可能会对我们不利,成本超过收益,验证损失开始上升。
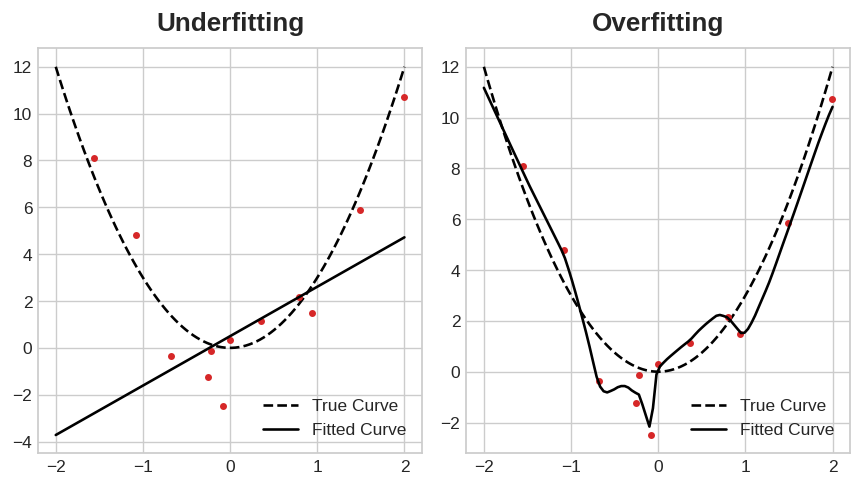
This trade-off indicates that there can be two problems that occur when training a model: not enough signal or too much noise. Underfitting the training set is when the loss is not as low as it could be because the model hasn't learned enough signal. Overfitting the training set is when the loss is not as low as it could be because the model learned too much noise. The trick to training deep learning models is finding the best balance between the two.
这种权衡表明,训练模型时可能会出现两个问题:信号不足或噪声太多。 欠拟合训练集是指损失没有尽可能低,因为模型没有学习到足够的信号。 过度拟合训练集是指损失没有尽可能低,因为模型学习了太多噪声。 训练深度学习模型的技巧是找到两者之间的最佳平衡。
We'll look at a couple ways of getting more signal out of the training data while reducing the amount of noise.
我们将研究几种从训练数据中获取更多信号同时减少噪声量的方法。
Capacity
容量
A model's capacity refers to the size and complexity of the patterns it is able to learn. For neural networks, this will largely be determined by how many neurons it has and how they are connected together. If it appears that your network is underfitting the data, you should try increasing its capacity.
模型的容量是指它能够学习的模式的大小和复杂性。 对于神经网络来说,这很大程度上取决于它有多少个神经元以及它们如何连接在一起。 如果您的神经网络似乎不能拟合数据,您应该尝试增加其容量。
You can increase the capacity of a network either by making it wider (more units to existing layers) or by making it deeper (adding more layers). Wider networks have an easier time learning more linear relationships, while deeper networks prefer more nonlinear ones. Which is better just depends on the dataset.
您可以通过使其更宽(向现有层添加更多单元)或使其更深(添加更多层)来增加网络的容量。 更宽的网络更容易学习更多的线性关系,而更深的网络能够处理更多的非线性关系。 哪个更好只取决于数据集。
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
])You'll explore how the capacity of a network can affect its performance in the exercise.
您将在练习中探索网络容量如何影响其性能。
Early Stopping
提前停止
We mentioned that when a model is too eagerly learning noise, the validation loss may start to increase during training. To prevent this, we can simply stop the training whenever it seems the validation loss isn't decreasing anymore. Interrupting the training this way is called early stopping.
我们提到,当模型过于急切地学习噪声时,验证损失可能会在训练期间开始增加。 为了防止这种情况,只要验证损失似乎不再减少,我们就可以停止训练。 以这种方式中断训练称为提前停止。
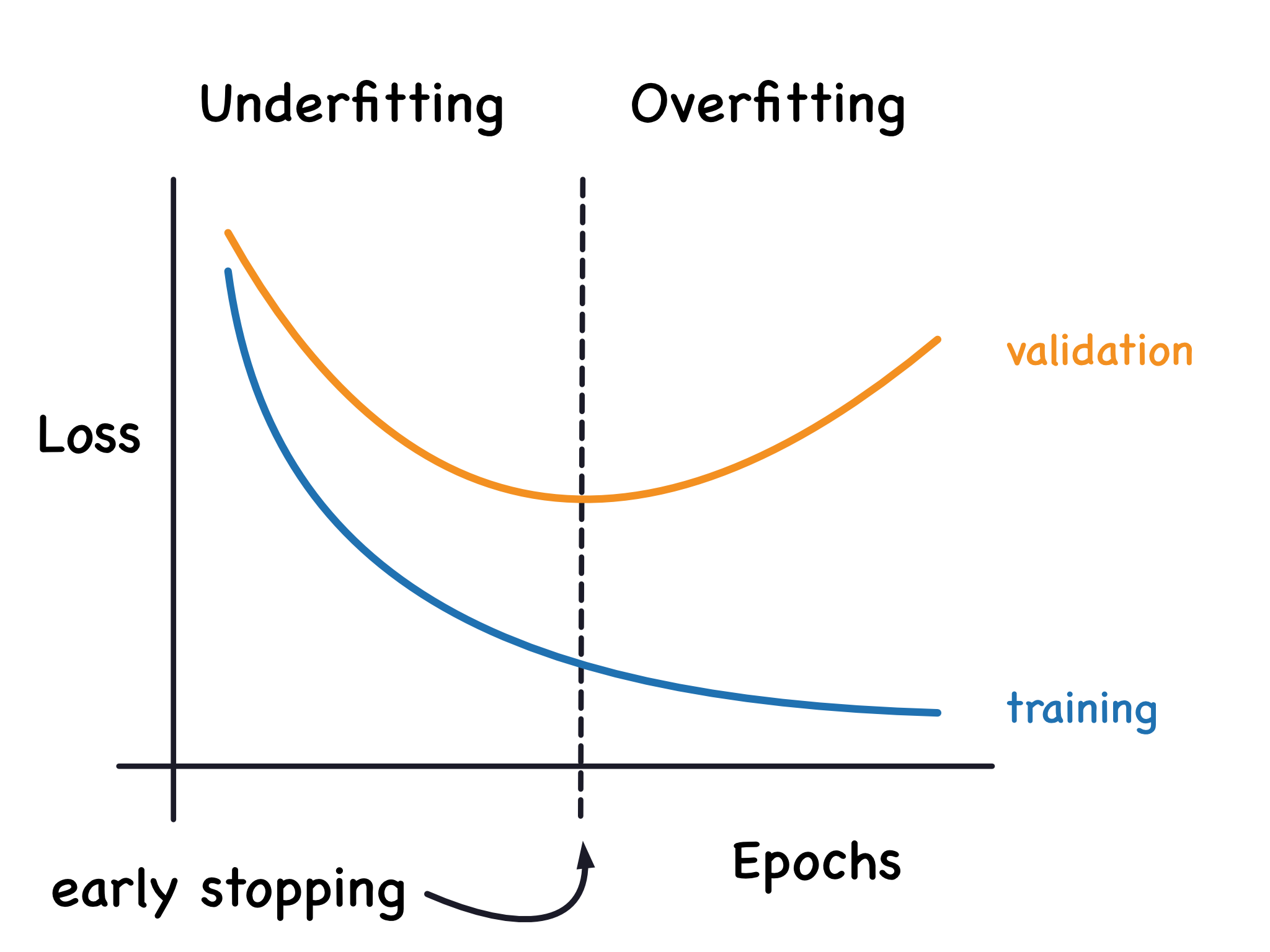
Once we detect that the validation loss is starting to rise again, we can reset the weights back to where the minimum occured. This ensures that the model won't continue to learn noise and overfit the data.
一旦我们检测到验证损失开始再次上升,我们就可以将权重重置回最小值发生的位置。 这确保了模型不会继续学习噪声并过度拟合数据。
Training with early stopping also means we're in less danger of stopping the training too early, before the network has finished learning signal. So besides preventing overfitting from training too long, early stopping can also prevent underfitting from not training long enough. Just set your training epochs to some large number (more than you'll need), and early stopping will take care of the rest.
提前停止训练还意味着我们在网络完成信号学习之前过早停止训练的危险较小。 因此,除了防止训练时间过长而导致过度拟合之外,提前停止还可以防止训练时间不够长而导致欠拟合。 只需将您的训练周期设置为某个较大的数字(超出您的需要),然后提前停止即可完成其余的工作。
Adding Early Stopping
添加提前停止
In Keras, we include early stopping in our training through a callback. A callback is just a function you want run every so often while the network trains. The early stopping callback will run after every epoch. (Keras has a variety of useful callbacks pre-defined, but you can define your own, too.)
在 Keras 中,我们通过回调在训练中加入提前停止。 回调只是您希望在网络训练时经常运行的函数。 提前停止回调将在每个纪元后运行。 (Keras 预定义了各种有用的回调,但您也可以[自己定义回调](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/LambdaCallback))
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)2024-04-13 17:30:24.109454: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-13 17:30:24.862380: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-04-13 17:30:24.862494: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-04-13 17:30:25.032180: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-04-13 17:30:25.444181: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-13 17:30:25.448154: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-04-13 17:30:29.109574: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRTThese parameters say: "If there hasn't been at least an improvement of 0.001 in the validation loss over the previous 20 epochs, then stop the training and keep the best model you found." It can sometimes be hard to tell if the validation loss is rising due to overfitting or just due to random batch variation. The parameters allow us to set some allowances around when to stop.
这些参数表示:“如果在过去 20 个 epoch 中验证损失没有至少改善 0.001,则停止训练并保留您找到的最佳模型。” 有时很难判断验证损失的增加是由于过度拟合还是仅仅由于随机批次变化。 这些参数允许我们设置一些关于何时停止的容限。
As we'll see in our example, we'll pass this callback to the fit method along with the loss and optimizer.
正如我们将在示例中看到的,我们将将此回调与损失和优化器一起传递给fit方法。
Example - Train a Model with Early Stopping
示例 - 训练提前停止的模型
Let's continue developing the model from the example in the last tutorial. We'll increase the capacity of that network but also add an early-stopping callback to prevent overfitting.
让我们继续上一个教程中的示例开发模型。 我们将增加该网络的容量,同时添加提前停止回调以防止过度拟合。
Here's the data prep again.
这里再次准备数据。
import pandas as pd
from IPython.display import display
red_wine = pd.read_csv('../00 datasets/ryanholbrook/dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))
# Scale to [0, 1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1109 | 10.8 | 0.470 | 0.43 | 2.10 | 0.171 | 27.0 | 66.0 | 0.99820 | 3.17 | 0.76 | 10.8 | 6 |
| 1032 | 8.1 | 0.820 | 0.00 | 4.10 | 0.095 | 5.0 | 14.0 | 0.99854 | 3.36 | 0.53 | 9.6 | 5 |
| 1002 | 9.1 | 0.290 | 0.33 | 2.05 | 0.063 | 13.0 | 27.0 | 0.99516 | 3.26 | 0.84 | 11.7 | 7 |
| 487 | 10.2 | 0.645 | 0.36 | 1.80 | 0.053 | 5.0 | 14.0 | 0.99820 | 3.17 | 0.42 | 10.0 | 6 |
Now let's increase the capacity of the network. We'll go for a fairly large network, but rely on the callback to halt the training once the validation loss shows signs of increasing.
现在让我们增加网络的容量。 我们将选择一个相当大的网络,但一旦验证损失显示出增加的迹象,就依靠回调来停止训练。
from tensorflow import keras
from tensorflow.keras import layers, callbacks
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)After defining the callback, add it as an argument in fit (you can have several, so put it in a list). Choose a large number of epochs when using early stopping, more than you'll need.
定义回调后,将其添加为fit中的参数(您可以有多个,因此将其放入列表中)。 使用提前停止时选择大量的纪元,超出您的需要。
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping], # put your callbacks in a list
verbose=0, # turn off training log
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("Minimum validation loss: {}".format(history_df['val_loss'].min()))Minimum validation loss: 0.09174752980470657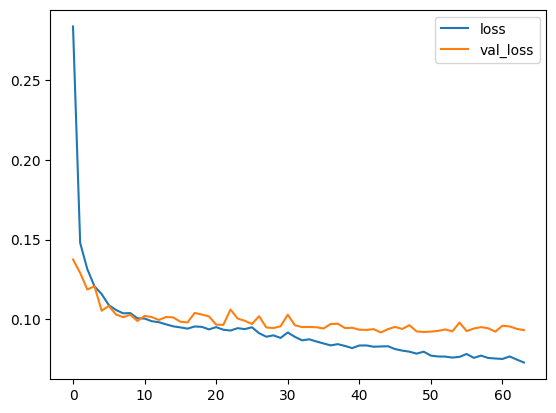
And sure enough, Keras stopped the training well before the full 500 epochs!
果然,Keras 在未满 500 个纪元前就停止了训练!
Your Turn
到你了
Now predict how popular a song is with the Spotify dataset.
现在使用 Spotify 数据集预测歌曲的流行程度。