Introduction
介绍
With all that you've learned, your SQL queries are getting pretty long, which can make them hard understand (and debug).
根据您所学的知识,您的 SQL 查询变得相当长,这可能使它们难以理解(和调试)。
You are about to learn how to use AS and WITH to tidy up your queries and make them easier to read.
您将学习如何使用 AS 和 WITH 来整理您的查询并使它们更易于阅读。
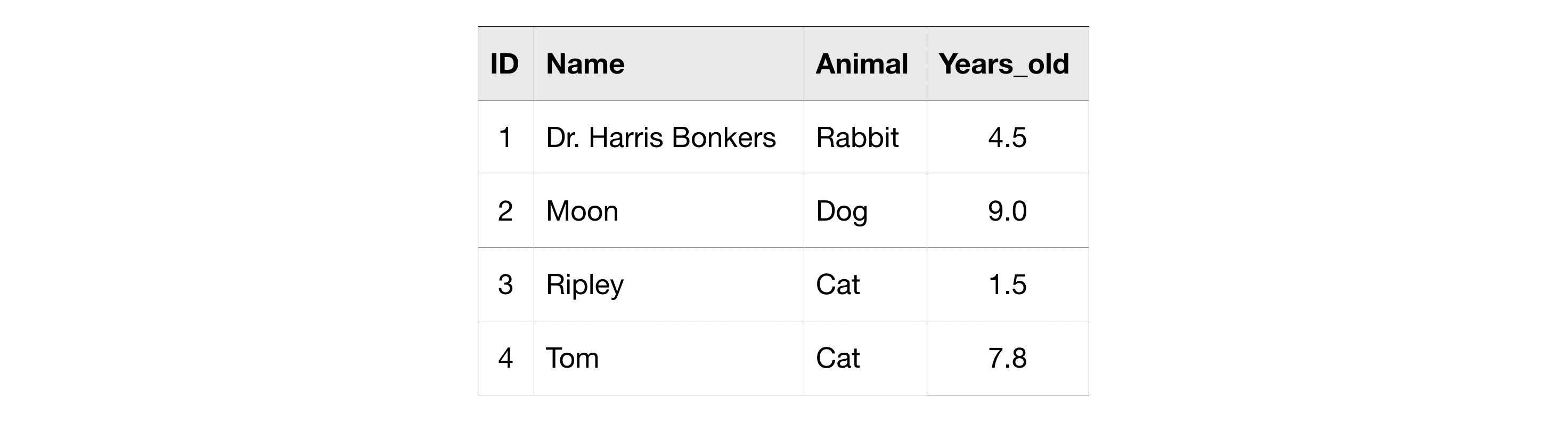
Along the way, we'll use the familiar pets table, but now it includes the ages of the animals.
在此过程中,我们将使用熟悉的pets表,但现在它包括动物的年龄。
AS
You learned in an earlier tutorial how to use AS to rename the columns generated by your queries, which is also known as aliasing. This is similar to how Python uses as for aliasing when doing imports like import pandas as pd or import seaborn as sns.
您在之前的教程中学习了如何使用 AS 重命名查询生成的列,这也称为 别名。 这类似于 Python 在执行import pandas as pd或import seaborn as sns等导入时使用as作为别名的方式。
To use AS in SQL, insert it right after the column you select. Here's an example of a query without an AS clause:
要在 SQL 中使用 AS,请将其插入到您选择的列之后。 以下是不带 AS 子句的查询示例:

And here's an example of the same query, but with AS.
这是相同查询的示例,但 使用 AS。

These queries return the same information, but in the second query the column returned by the COUNT() function will be called Number, rather than the default name of f0__.
这些查询返回相同的信息,但在第二个查询中,COUNT() 函数返回的列将被称为Number,而不是默认名称f0__。
WITH ... AS
On its own, AS is a convenient way to clean up the data returned by your query. It's even more powerful when combined with WITH in what's called a "common table expression".
就其本身而言,AS 是清理查询返回的数据的便捷方法。 当与通用表表达式中的 WITH 结合使用时,它的功能会更加强大。
A common table expression (or CTE) is a temporary table that you return within your query. CTEs are helpful for splitting your queries into readable chunks, and you can write queries against them.
通用表表达式(或 CTE)是您在查询中返回的临时表。 CTE 有助于将查询拆分为可读的块,并且您可以针对它们编写查询。
For instance, you might want to use the pets table to ask questions about older animals in particular. So you can start by creating a CTE which only contains information about animals more than five years old like this:
例如,您可能想使用pets表来查询有关年长动物的问题。 因此,您可以首先创建一个 CTE,其中仅包含有关 5 岁以上动物的信息,如下所示:
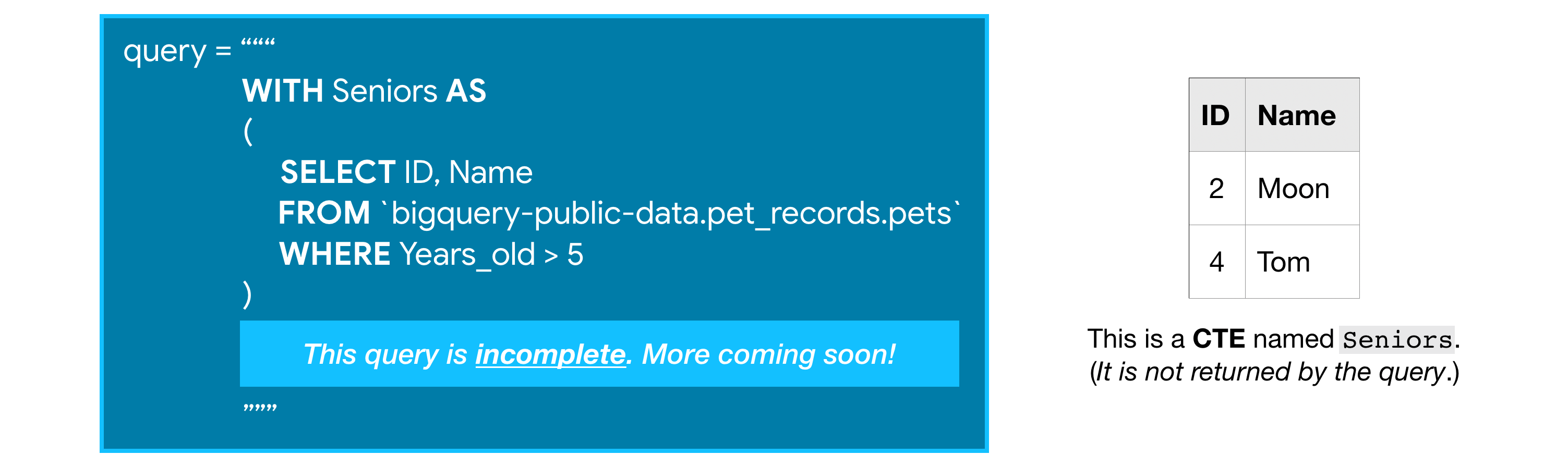
While this incomplete query above won't return anything, it creates a CTE that we can then refer to (as Seniors) while writing the rest of the query.
虽然上面这个不完整的查询不会返回任何内容,但它会创建一个 CTE,我们可以在编写查询的其余部分时引用它(作为Seniors)。
We can finish the query by pulling the information that we want from the CTE. The complete query below first creates the CTE, and then returns all of the IDs from it.
我们可以通过从 CTE 中提取我们想要的信息来完成查询。 下面的完整查询首先创建 CTE,然后返回其中的所有 ID。

You could do this without a CTE, but if this were the first part of a very long query, removing the CTE would make it much harder to follow.
您可以在没有 CTE 的情况下执行此操作,但如果这是很长查询的第一部分,则删除 CTE 会使查询变得更加困难。
Also, it's important to note that CTEs only exist inside the query where you create them, and you can't reference them in later queries. So, any query that uses a CTE is always broken into two parts: (1) first, we create the CTE, and then (2) we write a query that uses the CTE.
另外,需要注意的是,CTE 仅存在于您创建它们的查询中,并且您无法在以后的查询中引用它们。 因此,任何使用 CTE 的查询始终分为两部分:(1) 首先,我们创建 CTE,然后 (2) 我们编写一个使用 CTE 的查询。
Example: How many Bitcoin transactions are made per month?
示例:每月有多少笔比特币交易?
We're going to use a CTE to find out how many Bitcoin transactions were made each day for the entire timespan of a bitcoin transaction dataset.
我们将使用 CTE 来找出比特币交易数据集的所有时间范围内每天进行的比特币交易数量。
We'll investigate the transactions table. Here is a view of the first few rows. (The corresponding code is hidden, but you can un-hide it by clicking on the "Code" button below.)
我们将研究transactions表。 这是前几行的视图。 (_对应的代码已隐藏,但您可以通过点击下面的MARKDOWN_HASH06e004ef21414c06d3e4ff2cefaf6a04MARKDOWNHASH按钮取消隐藏。)
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "crypto_bitcoin" dataset
dataset_ref = client.dataset("crypto_bitcoin", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "transactions" table
table_ref = dataset_ref.table("transactions")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the "transactions" table
client.list_rows(table, max_results=5).to_dataframe()/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)| hash | size | virtual_size | version | lock_time | block_hash | block_number | block_timestamp | block_timestamp_month | input_count | output_count | input_value | output_value | is_coinbase | fee | inputs | outputs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | a16f3ce4dd5deb92d98ef5cf8afeaf0775ebca408f708b... | 275 | 275 | 1 | 0 | 00000000dc55860c8a29c58d45209318fa9e9dc2c1833a... | 181 | 2009-01-12 06:02:13+00:00 | 2009-01-01 | 1 | 2 | 4000000000.000000000 | 4000000000.000000000 | False | 0E-9 | [{'index': 0, 'spent_transaction_hash': 'f4184... | [{'index': 0, 'script_asm': '04b5abd412d4341b4... |
| 1 | 591e91f809d716912ca1d4a9295e70c3e78bab077683f7... | 275 | 275 | 1 | 0 | 0000000054487811fc4ff7a95be738aa5ad9320c394c48... | 182 | 2009-01-12 06:12:16+00:00 | 2009-01-01 | 1 | 2 | 3000000000.000000000 | 3000000000.000000000 | False | 0E-9 | [{'index': 0, 'spent_transaction_hash': 'a16f3... | [{'index': 0, 'script_asm': '0401518fa1d1e1e3e... |
| 2 | 12b5633bad1f9c167d523ad1aa1947b2732a865bf5414e... | 276 | 276 | 1 | 0 | 00000000f46e513f038baf6f2d9a95b2a28d8a6c985bcf... | 183 | 2009-01-12 06:34:22+00:00 | 2009-01-01 | 1 | 2 | 2900000000.000000000 | 2900000000.000000000 | False | 0E-9 | [{'index': 0, 'spent_transaction_hash': '591e9... | [{'index': 0, 'script_asm': '04baa9d3665315562... |
| 3 | 828ef3b079f9c23829c56fe86e85b4a69d9e06e5b54ea5... | 276 | 276 | 1 | 0 | 00000000fb5b44edc7a1aa105075564a179d65506e2bd2... | 248 | 2009-01-12 20:04:20+00:00 | 2009-01-01 | 1 | 2 | 2800000000.000000000 | 2800000000.000000000 | False | 0E-9 | [{'index': 0, 'spent_transaction_hash': '12b56... | [{'index': 0, 'script_asm': '04bed827d37474bef... |
| 4 | 35288d269cee1941eaebb2ea85e32b42cdb2b04284a56d... | 277 | 277 | 1 | 0 | 00000000689051c09ff2cd091cc4c22c10b965eb8db3ad... | 545 | 2009-01-15 05:48:32+00:00 | 2009-01-01 | 1 | 2 | 2500000000.000000000 | 2500000000.000000000 | False | 0E-9 | [{'index': 0, 'spent_transaction_hash': 'd71fd... | [{'index': 0, 'script_asm': '044a656f065871a35... |
Since the block_timestamp column contains the date of each transaction in DATETIME format, we'll convert these into DATE format using the DATE() command.
由于block_timestamp列包含 DATETIME 格式的每笔交易的日期,因此我们将使用 DATE() 命令将它们转换为 DATE 格式。
We do that using a CTE, and then the next part of the query counts the number of transactions for each date and sorts the table so that earlier dates appear first.
我们使用 CTE 来完成此操作,然后查询的下一部分计算每个日期的交易数量并对表进行排序,以便较早的日期首先出现。
# Query to select the number of transactions per date, sorted by date
query_with_CTE = """
WITH time AS
(
SELECT DATE(block_timestamp) AS trans_date
FROM `bigquery-public-data.crypto_bitcoin.transactions`
)
SELECT COUNT(1) AS transactions,
trans_date
FROM time
GROUP BY trans_date
ORDER BY trans_date
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_with_CTE, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
transactions_by_date = query_job.to_dataframe()
# Print the first five rows
transactions_by_date.head()| transactions | trans_date | |
|---|---|---|
| 0 | 1 | 2009-01-03 |
| 1 | 14 | 2009-01-09 |
| 2 | 61 | 2009-01-10 |
| 3 | 93 | 2009-01-11 |
| 4 | 101 | 2009-01-12 |
Since they're returned sorted, we can easily plot the raw results to show us the number of Bitcoin transactions per day over the whole timespan of this dataset.
由于它们是按顺序返回的,因此我们可以轻松绘制原始结果,以向我们展示该数据集整个时间范围内每天的比特币交易数量。
transactions_by_date.set_index('trans_date').plot()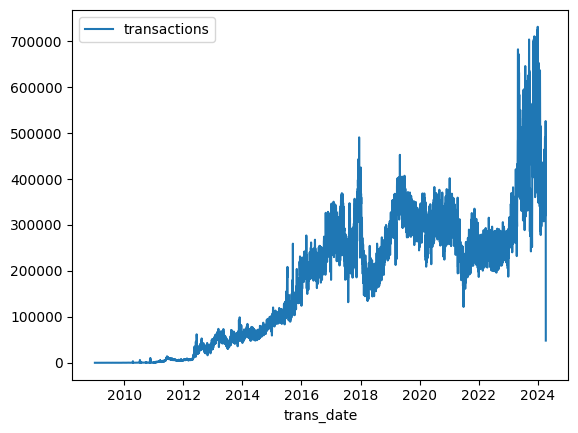
As you can see, common table expressions (CTEs) let you shift a lot of your data cleaning into SQL. That's an especially good thing in the case of BigQuery, because it is vastly faster than doing the work in Pandas.
正如您所看到的,通用表表达式 (CTE) 使您可以将大量数据清理工作转移到 SQL 中。 对于 BigQuery 来说这是一件特别好的事情,因为它比 Pandas 中的工作快得多。
Your turn
到你了
You now have the tools to stay organized even when writing more complex queries. Now use them here.
现在,即使在编写更复杂的查询时,您也可以使用工具来保持井井有条。 现在在这里使用它们。