Introduction
介绍
You have the tools to obtain data from a single table in whatever format you want it. But what if the data you want is spread across multiple tables?
您可以使用工具以您想要的任何格式从单个表中获取数据。 但是,如果您想要的数据分布在多个表中怎么办?
That's where JOIN comes in! JOIN is incredibly important in practical SQL workflows. So let's get started.
这就是 JOIN 发挥作用的地方! JOIN 在实际 SQL 工作流程中非常重要。 那么让我们开始吧。
Example
例子
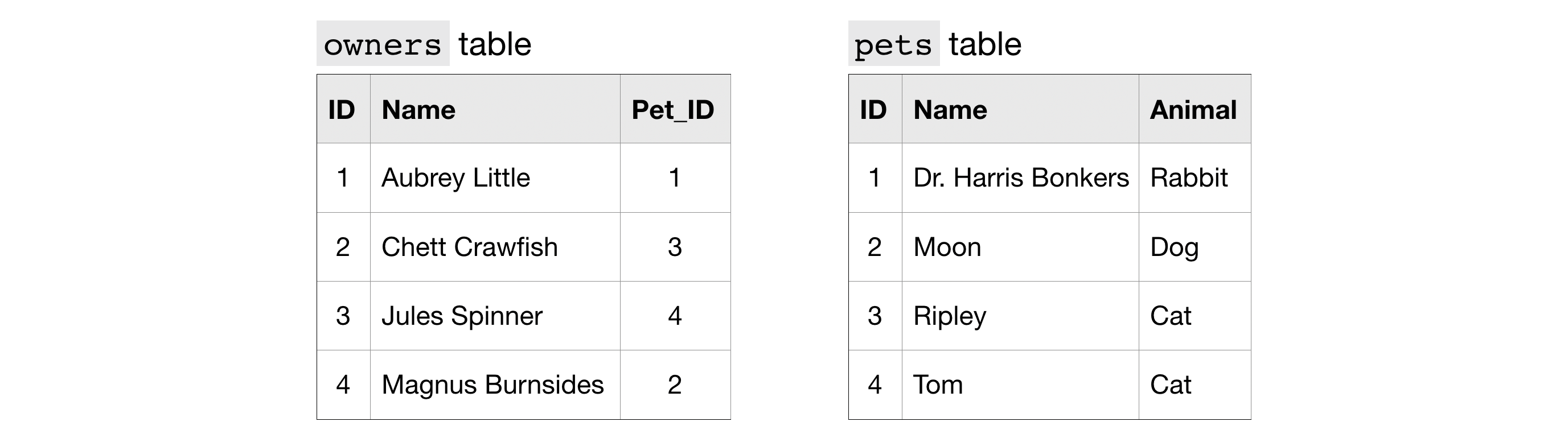
We'll use our imaginary pets table, which has three columns:
我们将使用假想的pets表,该表包含三列:
ID- ID number for the petID- 宠物的 ID 号Name- name of the petName- 宠物的名字Animal- type of animalAnimal- 动物类型
We'll also add another table, called owners. This table also has three columns:
我们还将添加另一个表,称为owners。 该表也有三列:
ID- ID number for the owner (different from the ID number for the pet)ID- 主人的身份证号码(与宠物的身份证号码不同)Name- name of the ownerName- 所有者的姓名Pet_ID- ID number for the pet that belongs to the owner (which matches the ID number for the pet in thepetstable)Pet_ID- 属于主人的宠物的 ID 号(与pets表中宠物的 ID 号匹配)
To get information that applies to a certain pet, we match the ID column in the pets table to the Pet_ID column in the owners table.
为了获取适用于特定宠物的信息,我们将pets表中的ID列与owners表中的Pet_ID列进行匹配。
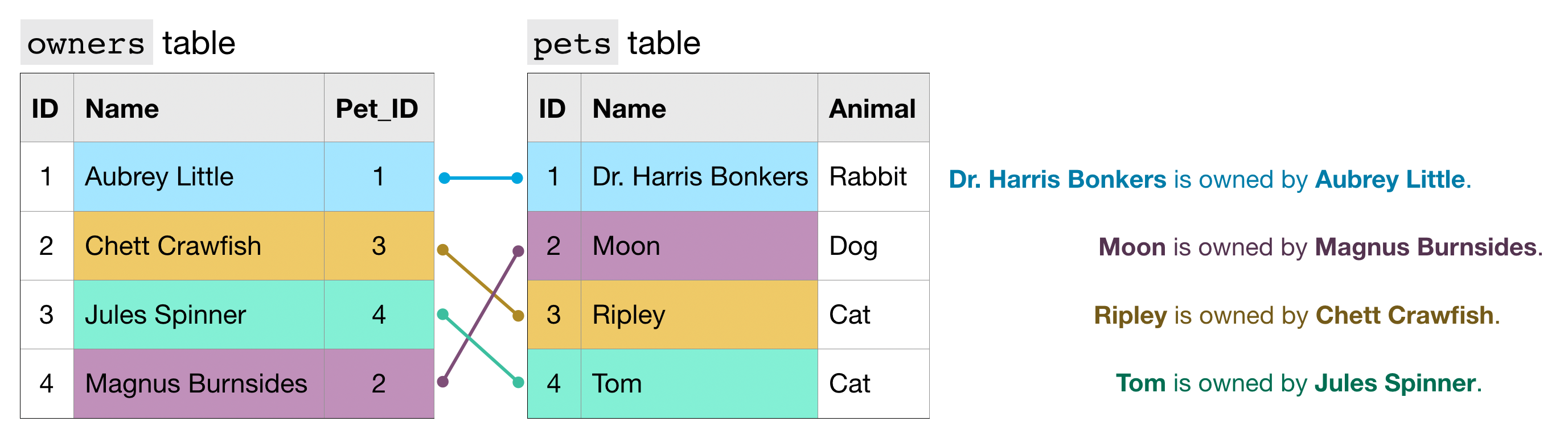
For example,
例如,
- the
petstable shows that Dr. Harris Bonkers is the pet with ID 1. pets表显示 Dr. Harris Bonkers 是 ID 为 1 的宠物。- The
ownerstable shows that Aubrey Little is the owner of the pet with ID 1. owners表显示 Aubrey Little 是 ID 为 1 的宠物的主人。
Putting these two facts together, Dr. Harris Bonkers is owned by Aubrey Little.
将这两个事实放在一起,Dr. Harris Bonkers 的所有者是 Aubrey Little。
Fortunately, we don't have to do this by hand to figure out which owner goes with which pet. In the next section, you'll learn how to use JOIN to create a new table combining information from the pets and owners tables.
幸运的是,我们不必手动确定哪个主人与哪个宠物在一起。 在下一节中,您将学习如何使用 JOIN 来创建一个关联pets和owners表信息的新表。
JOIN
Using JOIN, we can write a query to create a table with just two columns: the name of the pet and the name of the owner.
使用 JOIN,我们可以编写一个查询来创建一个只有两列的表:宠物的名字和主人的名字。

We combine information from both tables by matching rows where the ID column in the pets table matches the Pet_ID column in the owners table.
我们通过匹配pets表中的ID列与owners表中的Pet_ID列有相同数据的行来组合两个表中的信息。
In the query, ON determines which column in each table to use to combine the tables. Notice that since the ID column exists in both tables, we have to clarify which one to use. We use p.ID to refer to the ID column from the pets table, and o.Pet_ID refers to the Pet_ID column from the owners table.
在查询中,ON 确定使用每个表中的哪一列来组合表。 请注意,由于两个表中都存在ID列,因此我们必须明确要使用哪一个。 我们使用p.ID来引用pets表中的ID列,o.Pet_ID引用owners表中的Pet_ID列。
In general, when you're joining tables, it's a good habit to specify which table each of your columns comes from. That way, you don't have to pull up the schema every time you go back to read the query.
一般来说,当您连接表时,指定每个列来自哪个表是一个好习惯。 这样,您就不必每次返回读取查询时都提取架构。
The type of JOIN we're using today is called an INNER JOIN. That means that a row will only be put in the final output table if the value in the columns you're using to combine them shows up in both the tables you're joining. For example, if Tom's ID number of 4 didn't exist in the pets table, we would only get 3 rows back from this query. There are other types of JOIN, but an INNER JOIN is very widely used, so it's a good one to start with.
我们今天使用的 JOIN 类型称为 INNER JOIN。 这意味着,只有当您用于组合它们的列中的值都显示在您要连接的两个表中时,才会将一行放入最终输出表中。 例如,如果 Tom 的 ID 号 4 不存在于pets表中,那么我们从该查询中只能得到 3 行。 还有其他类型的 JOIN,但 INNER JOIN 使用非常广泛,因此这是一个很好的开始。
Example: How many files are covered by each type of software license?
示例:每种类型的软件许可证涵盖多少个文件?
GitHub is the most popular place to collaborate on software projects. A GitHub repository (or repo) is a collection of files associated with a specific project.
GitHub 是最受欢迎的软件项目协作场所。 GitHub 存储库(或 repo)是与特定项目关联的文件的集合。
Most repos on GitHub are shared under a specific legal license, which determines the legal restrictions on how they are used. For our example, we're going to look at how many different files have been released under each license.
GitHub 上的大多数存储库都是在特定的法律许可下共享的,这决定了对其使用方式的法律限制。 对于我们的示例,我们将查看每个许可证下发布了多少个不同的文件。
We'll work with two tables in the database. The first table is the licenses table, which provides the name of each GitHub repo (in the repo_name column) and its corresponding license. Here's a view of the first five rows.
我们将使用数据库中的两个表。 第一个表是licenses表,它提供每个 GitHub 存储库的名称(在repo_name列中)及其相应的许可证。 这是前五行的视图。
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "github_repos" dataset
dataset_ref = client.dataset("github_repos", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "licenses" table
licenses_ref = dataset_ref.table("licenses")
# API request - fetch the table
licenses_table = client.get_table(licenses_ref)
# Preview the first five lines of the "licenses" table
client.list_rows(licenses_table, max_results=5).to_dataframe()/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)| repo_name | license | |
|---|---|---|
| 0 | autarch/Dist-Zilla-Plugin-Test-TidyAll | artistic-2.0 |
| 1 | thundergnat/Prime-Factor | artistic-2.0 |
| 2 | kusha-b-k/Turabian_Engin_Fan | artistic-2.0 |
| 3 | onlinepremiumoutlet/onlinepremiumoutlet.github.io | artistic-2.0 |
| 4 | huangyuanlove/LiaoBa_Service | artistic-2.0 |
The second table is the sample_files table, which provides, among other information, the GitHub repo that each file belongs to (in the repo_name column). The first several rows of this table are printed below.
第二个表是sample_files表,除其他信息外,它还提供每个文件所属的 GitHub 存储库(在repo_name列中)。 该表的前几行打印如下。
# Construct a reference to the "sample_files" table
files_ref = dataset_ref.table("sample_files")
# API request - fetch the table
files_table = client.get_table(files_ref)
# Preview the first five lines of the "sample_files" table
client.list_rows(files_table, max_results=5).to_dataframe()| repo_name | ref | path | mode | id | symlink_target | |
|---|---|---|---|---|---|---|
| 0 | EOL/eol | refs/heads/master | generate/vendor/railties | 40960 | 0338c33fb3fda57db9e812ac7de969317cad4959 | /usr/share/rails-ruby1.8/railties |
| 1 | np/ling | refs/heads/master | tests/success/merger_seq_inferred.t/merger_seq... | 40960 | dd4bb3d5ecabe5044d3fa5a36e0a9bf7ca878209 | ../../../fixtures/all/merger_seq_inferred.ll |
| 2 | np/ling | refs/heads/master | fixtures/sequence/lettype.ll | 40960 | 8fdf536def2633116d65b92b3b9257bcf06e3e45 | ../all/lettype.ll |
| 3 | np/ling | refs/heads/master | fixtures/failure/wrong_order_seq3.ll | 40960 | c2509ae1196c4bb79d7e60a3d679488ca4a753e9 | ../all/wrong_order_seq3.ll |
| 4 | np/ling | refs/heads/master | issues/sequence/keep.t | 40960 | 5721de3488fb32745dfc11ec482e5dd0331fecaf | ../keep.t |
Next, we write a query that uses information in both tables to determine how many files are released in each license.
接下来,我们编写一个查询,使用两个表中的信息来确定每个许可证中发布了多少个文件。
# Query to determine the number of files per license, sorted by number of files
query = """
SELECT L.license, COUNT(1) AS number_of_files
FROM `bigquery-public-data.github_repos.sample_files` AS sf
INNER JOIN `bigquery-public-data.github_repos.licenses` AS L
ON sf.repo_name = L.repo_name
GROUP BY L.license
ORDER BY number_of_files DESC
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
file_count_by_license = query_job.to_dataframe()It's a big query, and so we'll investigate each piece separately.
这是一个很大的查询,因此我们将分别研究每个部分。

We'll begin with the JOIN (highlighted in blue above). This specifies the sources of data and how to join them. We use ON to specify that we combine the tables by matching the values in the repo_name columns in the tables.
我们将从 JOIN 开始(上面以蓝色突出显示)。 这指定了数据源以及如何连接它们。 我们使用 ON 来指定通过匹配表中repo_name列中的值来组合表。
Next, we'll talk about SELECT and GROUP BY (highlighted in yellow). The GROUP BY breaks the data into a different group for each license, before we COUNT the number of rows in the sample_files table that corresponds to each license. (Remember that you can count the number of rows with COUNT(1).)
接下来,我们将讨论 SELECT 和 GROUP BY(以黄色突出显示)。 在我们计算sample_files表中与每个许可证对应的行数之前,GROUP BY 将每个许可证的数据分为不同的组。 (请记住,您可以使用COUNT(1)来计算行数。)
Finally, the ORDER BY (highlighted in purple) sorts the results so that licenses with more files appear first.
最后,ORDER BY(以紫色突出显示)对结果进行排序,以便包含更多文件的许可证首先出现。
It was a big query, but it gave us a nice table summarizing how many files have been committed under each license:
这是一个很大的查询,但它给了我们一个很好的表格,总结了每个许可证下提交的文件数量:
# Print the DataFrame
file_count_by_license| license | number_of_files | |
|---|---|---|
| 0 | mit | 20560894 |
| 1 | gpl-2.0 | 16608922 |
| 2 | apache-2.0 | 7201141 |
| 3 | gpl-3.0 | 5107676 |
| 4 | bsd-3-clause | 3465437 |
| 5 | agpl-3.0 | 1372100 |
| 6 | lgpl-2.1 | 799664 |
| 7 | bsd-2-clause | 692357 |
| 8 | lgpl-3.0 | 582277 |
| 9 | mpl-2.0 | 457000 |
| 10 | cc0-1.0 | 449149 |
| 11 | epl-1.0 | 322255 |
| 12 | unlicense | 208602 |
| 13 | artistic-2.0 | 147391 |
| 14 | isc | 118332 |
You'll use JOIN clauses a lot and get very efficient with them as you get some practice.
您将大量使用 JOIN 子句,并在进行一些练习后会变得非常高效。
Your turn
到你了
You are on the last step. Finish it by solving these exercises.
你已经到了最后一步了。 通过解决这些练习来完成它。