Introduction
简介
In Lesson 2 we began our discussion of how the base in a convnet performs feature extraction. We learned about how the first two operations in this process occur in a Conv2D layer with relu activation.
在第 2 课中,我们开始讨论卷积网络中的基础如何执行特征提取。我们了解了此过程中的前两个操作如何在具有 relu 激活的 Conv2D 层中发生。
In this lesson, we'll look at the third (and final) operation in this sequence: condense with maximum pooling, which in Keras is done by a MaxPool2D layer.
在本课中,我们将查看此序列中的第三个(也是最后一个)操作:使用 最大池化 进行 压缩,在 Keras 中由 MaxPool2D 层完成。
Condense with Maximum Pooling
使用最大池化进行压缩
Adding condensing step to the model we had before, will give us this:
将压缩步骤添加到我们之前的模型中,将得到以下结果:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
layers.MaxPool2D(pool_size=2),
# More layers follow
])2024-05-30 10:10:01.706220: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-05-30 10:10:01.706291: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-05-30 10:10:01.707991: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registeredA MaxPool2D layer is much like a Conv2D layer, except that it uses a simple maximum function instead of a kernel, with the pool_size parameter analogous to kernel_size. A MaxPool2D layer doesn't have any trainable weights like a convolutional layer does in its kernel, however.
MaxPool2D 层与 Conv2D 层非常相似,不同之处在于它使用简单的最大值函数而不是内核,其中 pool_size 参数类似于 kernel_size。但是,MaxPool2D 层在其内核中没有任何可训练的权重,就像卷积层一样。
Let's take another look at the extraction figure from the last lesson. Remember that MaxPool2D is the Condense step.
让我们再看一下上一课的提取图。请记住,MaxPool2D 是 压缩 步骤。

Notice that after applying the ReLU function (Detect) the feature map ends up with a lot of "dead space," that is, large areas containing only 0's (the black areas in the image). Having to carry these 0 activations through the entire network would increase the size of the model without adding much useful information. Instead, we would like to condense the feature map to retain only the most useful part -- the feature itself.
请注意,在应用 ReLU 函数(检测)后,特征图会留下大量死区,即大片仅包含 0 的区域(图像中的黑色区域)。必须将这些 0 激活值传送到整个网络,这会增加模型的大小,而不会增加太多有用的信息。相反,我们希望压缩特征图以仅保留最有用的部分——特征本身。
This in fact is what maximum pooling does. Max pooling takes a patch of activations in the original feature map and replaces them with the maximum activation in that patch.
这实际上是最大池化所做的。最大池化会从原始特征图中获取激活值块,并将其替换为该块中的最大激活值。
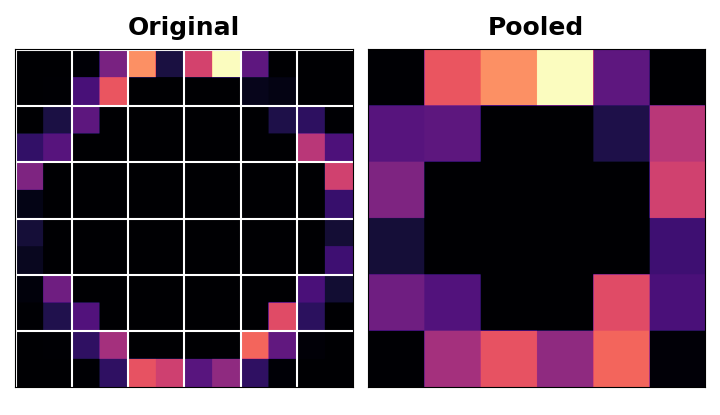
When applied after the ReLU activation, it has the effect of "intensifying" features. The pooling step increases the proportion of active pixels to zero pixels.
在 ReLU 激活之后应用时,它具有强化特征的效果。池化步骤将活动像素的比例增加到零像素。
Example - Apply Maximum Pooling
示例 - 应用最大池化
Let's add the "condense" step to the feature extraction we did in the example in Lesson 2. This next hidden cell will take us back to where we left off.
让我们将压缩步骤添加到我们在第 2 课的示例中执行的特征提取中。下一个隐藏单元将带我们回到我们离开的地方。
import tensorflow as tf
import matplotlib.pyplot as plt
import warnings
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# Read image
image_path = '../input/computer-vision-resources/car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
# Define kernel
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
], dtype=tf.float32)
# Reformat for batch compatibility.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
# Filter step
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
# we'll talk about these two in the next lesson!
strides=1,
padding='SAME'
)
# Detect step
image_detect = tf.nn.relu(image_filter)
# Show what we have so far
plt.figure(figsize=(12, 6))
plt.subplot(131)
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.title('Input')
plt.subplot(132)
plt.imshow(tf.squeeze(image_filter))
plt.axis('off')
plt.title('Filter')
plt.subplot(133)
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.title('Detect')
plt.show();
We'll use another one of the functions in tf.nn to apply the pooling step, tf.nn.pool. This is a Python function that does the same thing as the MaxPool2D layer you use when model building, but, being a simple function, is easier to use directly.
我们将使用 tf.nn 中的另一个函数 tf.nn.pool 来应用池化步骤。这是一个 Python 函数,其功能与模型构建时使用的 MaxPool2D 层相同,但由于它是一个简单的函数,因此更容易直接使用。
import tensorflow as tf
image_condense = tf.nn.pool(
input=image_detect, # image in the Detect step above
window_shape=(2, 2),
pooling_type='MAX',
# we'll see what these do in the next lesson!
strides=(2, 2),
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.show();
Pretty cool! Hopefully you can see how the pooling step was able to intensify the feature by condensing the image around the most active pixels.
很酷!希望您能看到池化步骤如何通过将图像压缩在最活跃的像素周围来强化特征。
Translation Invariance
平移不变性
We called the zero-pixels "unimportant". Does this mean they carry no information at all? In fact, the zero-pixels carry positional information. The blank space still positions the feature within the image. When MaxPool2D removes some of these pixels, it removes some of the positional information in the feature map. This gives a convnet a property called translation invariance. This means that a convnet with maximum pooling will tend not to distinguish features by their location in the image. ("Translation" is the mathematical word for changing the position of something without rotating it or changing its shape or size.)
我们将零像素称为不重要。这是否意味着它们根本不携带任何信息?事实上,零像素携带位置信息。空白处仍然将特征定位在图像中。当MaxPool2D删除其中一些像素时,它会删除特征图中的一些位置信息。这为卷积网络提供了一种称为平移不变性的属性。这意味着具有最大池化的卷积网络倾向于不根据特征在图像中的位置来区分特征。(平移是数学词,表示在不旋转或改变形状或大小的情况下改变某物的位置。)
Watch what happens when we repeatedly apply maximum pooling to the following feature map.
观察当我们反复将最大池化应用于以下特征图时会发生什么。
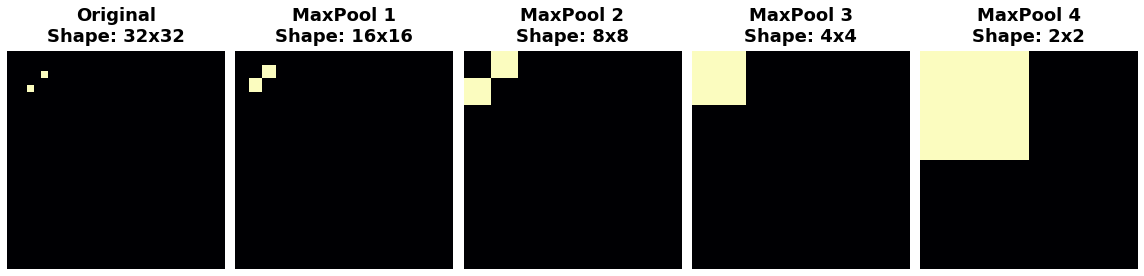
The two dots in the original image became indistinguishable after repeated pooling. In other words, pooling destroyed some of their positional information. Since the network can no longer distinguish between them in the feature maps, it can't distinguish them in the original image either: it has become invariant to that difference in position.
经过多次池化后,原始图像中的两个点变得难以区分。换句话说,池化破坏了它们的部分位置信息。由于网络无法再在特征图中区分它们,因此也无法在原始图像中区分它们:它已变得对位置差异不变。
In fact, pooling only creates translation invariance in a network over small distances, as with the two dots in the image. Features that begin far apart will remain distinct after pooling; only some of the positional information was lost, but not all of it.
事实上,池化只会在网络中在小距离上产生平移不变性,就像图像中的两个点一样。池化后,相距很远的特征将保持不同;只有部分位置信息丢失,但不是全部。
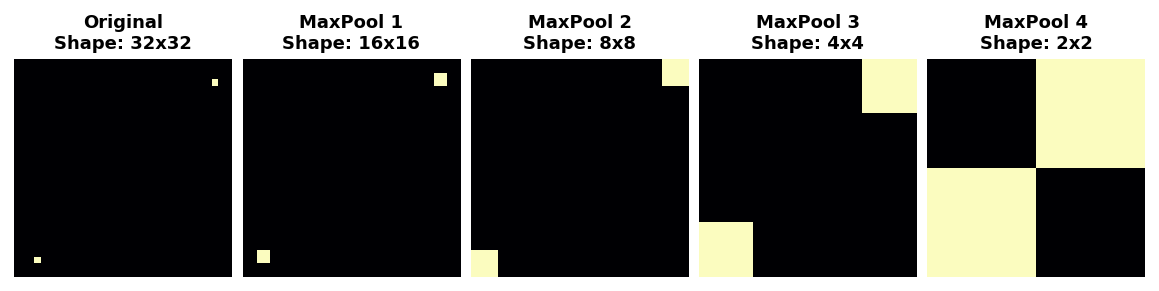
This invariance to small differences in the positions of features is a nice property for an image classifier to have. Just because of differences in perspective or framing, the same kind of feature might be positioned in various parts of the original image, but we would still like for the classifier to recognize that they are the same. Because this invariance is built into the network, we can get away with using much less data for training: we no longer have to teach it to ignore that difference. This gives convolutional networks a big efficiency advantage over a network with only dense layers. (You'll see another way to get invariance for free in Lesson 6 with Data Augmentation!)
这种对特征位置细微差异的不变性是图像分类器所具有的一个很好的特性。仅仅因为视角或取景的差异,同一种特征可能位于原始图像的不同部分,但我们仍然希望分类器能够识别出它们是相同的。由于这种不变性是内置于网络中的,因此我们可以使用更少的数据进行训练:我们不再需要教它忽略这种差异。这使得卷积网络比只有密集层的网络具有很大的效率优势。(您将在第 6 课中看到另一种免费获得不变性的方法,即数据增强!)
Conclusion
结论
In this lesson, we learned the about the last step of feature extraction: condense with MaxPool2D. In Lesson 4, we'll finish up our discussion of convolution and pooling with sliding windows.
在本课中,我们学习了特征提取的最后一步:使用 MaxPool2D 进行压缩。在第 4 课中,我们将完成对使用滑动窗口进行卷积和池化的讨论。
Your Turn
轮到你了
Now, start the Exercise to finish the extraction you started in Lesson 2, see this invariance property in action, and also learn about another kind of pooling: average pooling!
现在,开始 练习,完成你在第 2 课中开始的提取,看看这个不变性属性的实际作用,并了解另一种池化:平均池化!