Introduction
介绍
There's more to the world of deep learning than just dense layers. There are dozens of kinds of layers you might add to a model. (Try browsing through the Keras docs for a sample!) Some are like dense layers and define connections between neurons, and others can do preprocessing or transformations of other sorts.
深度学习的世界不仅仅是密集层。 您可以向模型添加数十种层。 (尝试浏览 Keras 文档 获取示例!)有些就像密集层并定义神经元之间的连接,而其他可以 进行其他类型的预处理或转换。
In this lesson, we'll learn about a two kinds of special layers, not containing any neurons themselves, but that add some functionality that can sometimes benefit a model in various ways. Both are commonly used in modern architectures.
在本课中,我们将学习两种特殊层,它们本身不包含任何神经元,但添加了一些有时可以以多种方式使模型受益的功能。 两者都常用于现代模型架构中。
Dropout
暂退层
The first of these is the "dropout layer", which can help correct overfitting.
第一个是dropout层,它可以帮助纠正过度拟合。
In the last lesson we talked about how overfitting is caused by the network learning spurious patterns in the training data. To recognize these spurious patterns a network will often rely on very a specific combinations of weight, a kind of "conspiracy" of weights. Being so specific, they tend to be fragile: remove one and the conspiracy falls apart.
在上一课中,我们讨论了网络学习训练数据中的虚假模式是如何导致过拟合的。 为了识别这些虚假模式,网络通常依赖于非常特定的权重组合,这是一种权重的阴谋。 由于它们如此具体,因此往往很脆弱:删除其中一个,阴谋就会崩溃。
This is the idea behind dropout. To break up these conspiracies, we randomly drop out some fraction of a layer's input units every step of training, making it much harder for the network to learn those spurious patterns in the training data. Instead, it has to search for broad, general patterns, whose weight patterns tend to be more robust.
这就是dropout背后的想法。 为了打破这些阴谋,我们在训练的每一步中随机丢弃某层输入单元的一部分,从而使网络更难学习训练数据中的那些虚假模式。 相反,它必须寻找广泛、通用的模式,其权重模式往往更稳健。
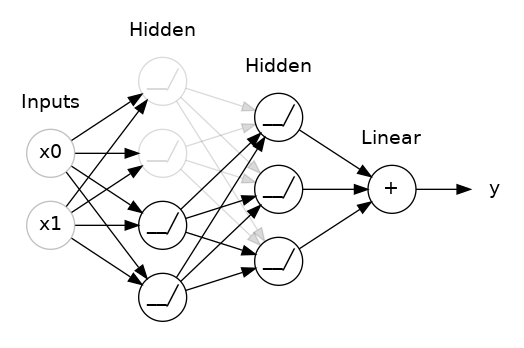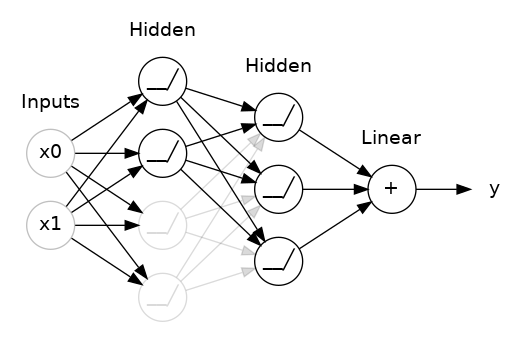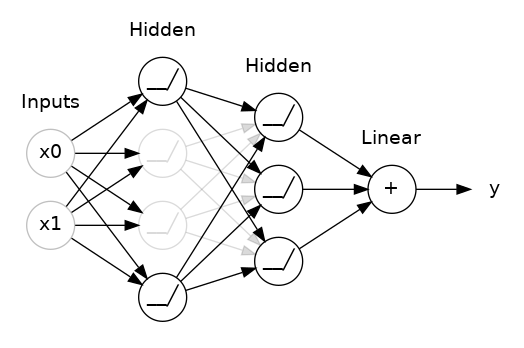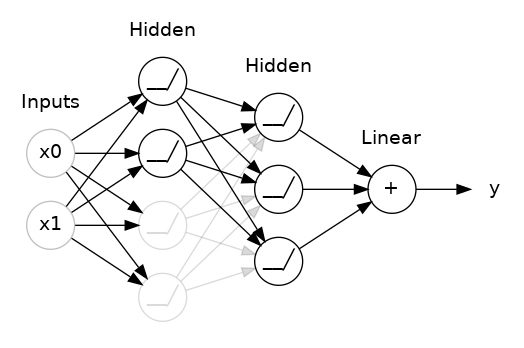
You could also think about dropout as creating a kind of ensemble of networks. The predictions will no longer be made by one big network, but instead by a committee of smaller networks. Individuals in the committee tend to make different kinds of mistakes, but be right at the same time, making the committee as a whole better than any individual. (If you're familiar with random forests as an ensemble of decision trees, it's the same idea.)
您还可以将 dropout 视为创建一种网络集成。 预测将不再由一个大网络做出,而是由较小网络组成的委员会做出。 委员会中的个人往往会犯不同类型的错误,但同时又是正确的,这使得委员会作为一个整体比任何个人都更好。 (如果您熟悉随机森林作为决策树的集合,那么这是相同的想法。)
Adding Dropout
添加 Dropout
In Keras, the dropout rate argument rate defines what percentage of the input units to shut off. Put the Dropout layer just before the layer you want the dropout applied to:
在 Keras 中,丢失率参数rate定义了要关闭的输入单元的百分比。 将Dropout层放在您想要应用 dropout 的图层之前:
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])Batch Normalization
批量归一化
The next special layer we'll look at performs "batch normalization" (or "batchnorm"), which can help correct training that is slow or unstable.
我们将看到的下一个特殊层执行批量归一化(或batchnorm),这可以帮助纠正缓慢或不稳定的训练。
With neural networks, it's generally a good idea to put all of your data on a common scale, perhaps with something like scikit-learn's StandardScaler or MinMaxScaler. The reason is that SGD will shift the network weights in proportion to how large an activation the data produces. Features that tend to produce activations of very different sizes can make for unstable training behavior.
对于神经网络,通常最好将所有数据放在一个通用的比例上,也许可以使用 scikit-learn 的 StandardScaler 或 MinMaxScaler。 原因是 SGD 会根据数据产生的激活大小按比例改变网络权重。 倾向于产生不同大小的激活特征可能会导致训练行为不稳定。
Now, if it's good to normalize the data before it goes into the network, maybe also normalizing inside the network would be better! In fact, we have a special kind of layer that can do this, the batch normalization layer. A batch normalization layer looks at each batch as it comes in, first normalizing the batch with its own mean and standard deviation, and then also putting the data on a new scale with two trainable rescaling parameters. Batchnorm, in effect, performs a kind of coordinated rescaling of its inputs.
现在,如果在数据进入网络之前对数据进行归一化是件好事,也许在网络内部进行归一化会更好! 事实上,我们有一种特殊的层可以做到这一点,批量归一化层。 批次归一化层会查看每个批次的数据,首先使用批次自身的均值和标准差对批次进行归一化,然后使用两个可训练的缩放参数将数据置于新的尺度上。 实际上,Batchnorm 对其输入执行了一种协调的重新调整。
Most often, batchnorm is added as an aid to the optimization process (though it can sometimes also help prediction performance). Models with batchnorm tend to need fewer epochs to complete training. Moreover, batchnorm can also fix various problems that can cause the training to get "stuck". Consider adding batch normalization to your models, especially if you're having trouble during training.
大多数情况下,batchnorm 被添加作为优化过程的辅助(尽管它有时也有助于预测性能)。 具有批量归一化的模型往往需要更少的时期来完成训练。 此外,batchnorm 还可以修复各种可能导致训练卡住的问题。 考虑向您的模型添加批量归一化,特别是当您在训练期间遇到问题时。
Adding Batch Normalization
添加批量归一化
It seems that batch normalization can be used at almost any point in a network. You can put it after a layer...
看来批量归一化几乎可以在网络中的任何位置使用。 你可以把它放在某一层之后...
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),... or between a layer and its activation function:
...或在层及其激活函数之间:
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),And if you add it as the first layer of your network it can act as a kind of adaptive preprocessor, standing in for something like Sci-Kit Learn's StandardScaler.
如果将其添加为网络的第一层,它可以充当一种自适应预处理器,替代 Sci-Kit Learn 的StandardScaler之类的东西。
Example - Using Dropout and Batch Normalization
示例 - 使用 Dropout 和批量归一化
Let's continue developing the Red Wine model. Now we'll increase the capacity even more, but add dropout to control overfitting and batch normalization to speed up optimization. This time, we'll also leave off standardizing the data, to demonstrate how batch normalization can stabalize the training.
让我们继续开发红酒模型。 现在我们将进一步增加容量,但添加 dropout 来控制过度拟合和批量归一化以加快优化速度。 这次,我们也将不再对数据进行归一化,以演示批量归一化如何稳定训练。
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
import pandas as pd
red_wine = pd.read_csv('../00 datasets/ryanholbrook/dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']When adding dropout, you may need to increase the number of units in your Dense layers.
添加 dropout 时,您可能需要增加Dense层中的单元数量。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])2024-04-25 11:26:26.151638: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-25 11:26:26.186763: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-04-25 11:26:26.186792: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-04-25 11:26:26.187649: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-04-25 11:26:26.192813: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-25 11:26:26.193897: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-04-25 11:26:27.137859: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRTThere's nothing to change this time in how we set up the training.
这次我们的训练设置方式没有任何改变。
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();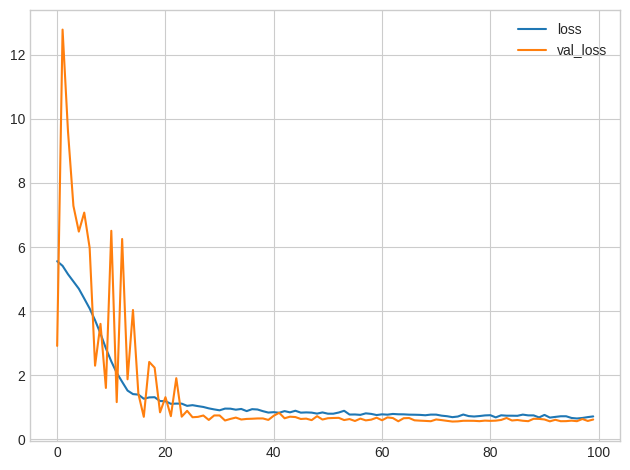
You'll typically get better performance if you standardize your data before using it for training. That we were able to use the raw data at all, however, shows how effective batch normalization can be on more difficult datasets.
如果在使用数据进行训练之前对数据进行归一化,通常会获得更好的性能。 然而,我们能够使用原始数据,这表明批量归一化在更困难的数据集上是多么有效。
Your Turn
到你了
Move on to improve predictions on the Spotify dataset with dropout and see how batch normalization can help with difficult datasets.
继续在带有 dropout 的 Spotify 数据集上改进预测,看看批量归一化如何帮助处理困难的数据集。