Introduction
介绍
So far in this course, we've learned about how neural networks can solve regression problems. Now we're going to apply neural networks to another common machine learning problem: classification. Most everything we've learned up until now still applies. The main difference is in the loss function we use and in what kind of outputs we want the final layer to produce.
到目前为止,在本课程中,我们已经了解了神经网络如何解决回归问题。 现在我们将把神经网络应用于另一个常见的机器学习问题:分类。 到目前为止我们学到的大部分内容仍然适用。 主要区别在于我们使用的损失函数以及我们希望最终层产生什么样的输出。
Binary Classification
二元分类
Classification into one of two classes is a common machine learning problem. You might want to predict whether or not a customer is likely to make a purchase, whether or not a credit card transaction was fraudulent, whether deep space signals show evidence of a new planet, or a medical test evidence of a disease. These are all binary classification problems.
分类是常见的两类机器学习问题之一。 您可能想要预测客户是否有可能进行购买、信用卡交易是否存在欺诈、深空信号是否显示新行星的证据或疾病的医学测试证据。 这些都是二元分类问题。
In your raw data, the classes might be represented by strings like "Yes" and "No", or "Dog" and "Cat". Before using this data we'll assign a class label: one class will be 0 and the other will be 1. Assigning numeric labels puts the data in a form a neural network can use.
在原始数据中,类可能由Yes和No或Dog和Cat等字符串表示。 在使用这些数据之前,我们将分配一个类标签:一个类是0,另一个类是1。 分配数字标签将数据置于神经网络可以使用的形式中。
Accuracy and Cross-Entropy
准确率和交叉熵
Accuracy is one of the many metrics in use for measuring success on a classification problem. Accuracy is the ratio of correct predictions to total predictions: accuracy = number_correct / total. A model that always predicted correctly would have an accuracy score of 1.0. All else being equal, accuracy is a reasonable metric to use whenever the classes in the dataset occur with about the same frequency.
准确性是用于衡量分类问题成功与否的众多指标之一。 准确率是正确预测与总预测的比率:准确率=正确数/总计。 始终正确预测的模型的准确度得分为1.0。 在其他条件相同的情况下,只要数据集中的类以大致相同的频率出现,准确性就是一个合理的指标。
The problem with accuracy (and most other classification metrics) is that it can't be used as a loss function. SGD needs a loss function that changes smoothly, but accuracy, being a ratio of counts, changes in "jumps". So, we have to choose a substitute to act as the loss function. This substitute is the cross-entropy function.
准确性(以及大多数其他分类指标)的问题在于它不能用作损失函数。 SGD 需要一个平滑变化的损失函数,但准确度(作为计数的比率)会跳跃变化。 因此,我们必须选择一个替代函数来充当损失函数。 这个替代品是交叉熵函数。
Now, recall that the loss function defines the objective of the network during training. With regression, our goal was to minimize the distance between the expected outcome and the predicted outcome. We chose MAE to measure this distance.
现在,回想一下损失函数定义了训练期间网络的目标。 通过回归,我们的目标是最小化预期结果和预测结果之间的距离。 我们选择 MAE 来测量这个距离。
For classification, what we want instead is a distance between probabilities, and this is what cross-entropy provides. Cross-entropy is a sort of measure for the distance from one probability distribution to another.
对于分类,我们想要的是概率之间的距离,这就是交叉熵所提供的。 交叉熵是一种衡量从一个概率分布到另一个概率分布的距离的度量。
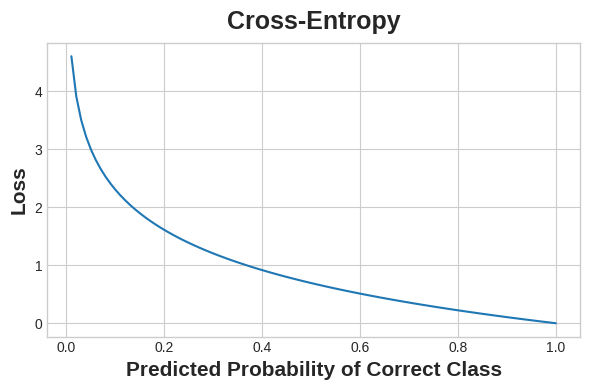
The idea is that we want our network to predict the correct class with probability 1.0. The further away the predicted probability is from 1.0, the greater will be the cross-entropy loss.
我们的想法是,我们希望我们的网络以概率1.0预测正确的类别。 预测概率离1.0越远,交叉熵损失就越大。
The technical reasons we use cross-entropy are a bit subtle, but the main thing to take away from this section is just this: use cross-entropy for a classification loss; other metrics you might care about (like accuracy) will tend to improve along with it.
我们使用交叉熵的技术原因有点微妙,但是本节的主要内容就是:使用交叉熵衡量分类损失; 您可能关心的其他指标(例如准确性)往往会随之提高。
Making Probabilities with the Sigmoid Function
使用 Sigmoid 函数计算概率
The cross-entropy and accuracy functions both require probabilities as inputs, meaning, numbers from 0 to 1. To covert the real-valued outputs produced by a dense layer into probabilities, we attach a new kind of activation function, the sigmoid activation.
交叉熵和准确度函数都需要概率作为输入,即从 0 到 1 的数字。为了将密集层产生的实值输出转换为概率,我们附加了一种新的激活函数,sigmoid 激活。
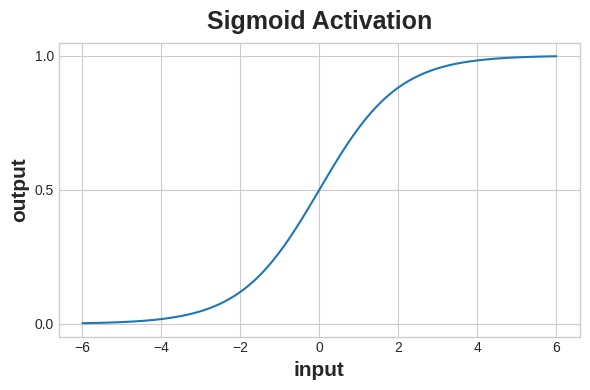
To get the final class prediction, we define a threshold probability. Typically this will be 0.5, so that rounding will give us the correct class: below 0.5 means the class with label 0 and 0.5 or above means the class with label 1. A 0.5 threshold is what Keras uses by default with its accuracy metric.
为了获得最终的类别预测,我们定义一个阈值概率。 通常情况下,该值为 0.5,因此四舍五入将为我们提供正确的类别:低于 0.5 表示具有标签 0 的类别,0.5 或以上表示具有标签 1 的类别。阈值 0.5 是 Keras 默认使用的[准确度指标] (https://www.tensorflow.org/api_docs/python/tf/keras/metrics/BinaryAccuracy)。
Example - Binary Classification
示例 - 二元分类
Now let's try it out!
现在我们来尝试一下吧!
The Ionosphere dataset contains features obtained from radar signals focused on the ionosphere layer of the Earth's atmosphere. The task is to determine whether the signal shows the presence of some object, or just empty air.
电离层 数据集包含从聚焦于地球大气层电离层的雷达信号中获得的特征。 任务是确定信号是否表明存在某种物体,或者只是空气。
import pandas as pd
from IPython.display import display
ion = pd.read_csv('../00 datasets/ryanholbrook/dl-course-data/ion.csv', index_col=0)
display(ion.head())
df = ion.copy()
df['Class'] = df['Class'].map({'good': 0, 'bad': 1})
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
df_train.dropna(axis=1, inplace=True) # drop the empty feature in column 2
df_valid.dropna(axis=1, inplace=True)
X_train = df_train.drop('Class', axis=1)
X_valid = df_valid.drop('Class', axis=1)
y_train = df_train['Class']
y_valid = df_valid['Class']| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V26 | V27 | V28 | V29 | V30 | V31 | V32 | V33 | V34 | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0.99539 | -0.05889 | 0.85243 | 0.02306 | 0.83398 | -0.37708 | 1.00000 | 0.03760 | ... | -0.51171 | 0.41078 | -0.46168 | 0.21266 | -0.34090 | 0.42267 | -0.54487 | 0.18641 | -0.45300 | good |
| 2 | 1 | 0 | 1.00000 | -0.18829 | 0.93035 | -0.36156 | -0.10868 | -0.93597 | 1.00000 | -0.04549 | ... | -0.26569 | -0.20468 | -0.18401 | -0.19040 | -0.11593 | -0.16626 | -0.06288 | -0.13738 | -0.02447 | bad |
| 3 | 1 | 0 | 1.00000 | -0.03365 | 1.00000 | 0.00485 | 1.00000 | -0.12062 | 0.88965 | 0.01198 | ... | -0.40220 | 0.58984 | -0.22145 | 0.43100 | -0.17365 | 0.60436 | -0.24180 | 0.56045 | -0.38238 | good |
| 4 | 1 | 0 | 1.00000 | -0.45161 | 1.00000 | 1.00000 | 0.71216 | -1.00000 | 0.00000 | 0.00000 | ... | 0.90695 | 0.51613 | 1.00000 | 1.00000 | -0.20099 | 0.25682 | 1.00000 | -0.32382 | 1.00000 | bad |
| 5 | 1 | 0 | 1.00000 | -0.02401 | 0.94140 | 0.06531 | 0.92106 | -0.23255 | 0.77152 | -0.16399 | ... | -0.65158 | 0.13290 | -0.53206 | 0.02431 | -0.62197 | -0.05707 | -0.59573 | -0.04608 | -0.65697 | good |
5 rows × 35 columns
We'll define our model just like we did for the regression tasks, with one exception. In the final layer include a 'sigmoid' activation so that the model will produce class probabilities.
我们将像回归任务一样定义我们的模型,但有一个例外。 在最后一层包含sigmoid激活,以便模型产生类别概率。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[33]),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])2024-04-25 17:58:54.104399: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-25 17:58:54.138629: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-04-25 17:58:54.138663: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-04-25 17:58:54.139573: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-04-25 17:58:54.145511: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
2024-04-25 17:58:54.146751: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-04-25 17:58:55.038743: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRTAdd the cross-entropy loss and accuracy metric to the model with its compile method. For two-class problems, be sure to use 'binary' versions. (Problems with more classes will be slightly different.) The Adam optimizer works great for classification too, so we'll stick with it.
使用compile方法将交叉熵损失和准确性度量添加到模型中。 对于二类问题,请务必使用二进制版本。 (更多类的问题会略有不同。)Adam 优化器也非常适合分类,因此我们将坚持使用它。
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)The model in this particular problem can take quite a few epochs to complete training, so we'll include an early stopping callback for convenience.
这个特定问题中的模型可能需要相当多的纪元才能完成训练,因此为了方便起见,我们将包含一个提前停止的回调。
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
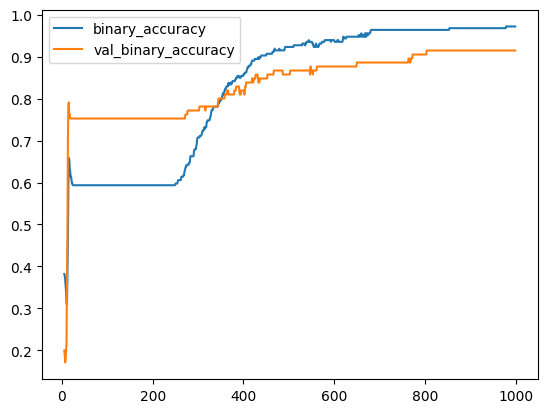
)We'll take a look at the learning curves as always, and also inspect the best values for the loss and accuracy we got on the validation set. (Remember that early stopping will restore the weights to those that got these values.)
我们将一如既往地查看学习曲线,并检查我们在验证集上获得的损失和准确性的最佳值。 (请记住,提前停止会将权重恢复到获得这些值的权重。)
history_df = pd.DataFrame(history.history)
# Start the plot at epoch 5
history_df.loc[5:, ['loss', 'val_loss']].plot()
history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()
print(("Best Validation Loss: {:0.4f}" +\
"\nBest Validation Accuracy: {:0.4f}")\
.format(history_df['val_loss'].min(),
history_df['val_binary_accuracy'].max()))Best Validation Loss: 0.3468
Best Validation Accuracy: 0.9143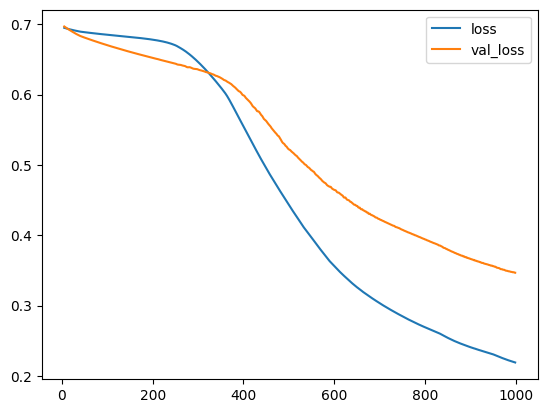
Your Turn
到你了
Use a neural network to predict cancellations in hotel reservations with the Hotel Cancellations dataset.
使用神经网络通过酒店取消数据集预测酒店预订取消行为。