Introduction
简介
Machine learning (ML) has the potential to improve lives, but it can also be a source of harm. ML applications have discriminated against individuals on the basis of race, sex, religion, socioeconomic status, and other categories.
机器学习 (ML) 有可能改善生活,但也可能造成伤害。ML 应用程序会根据种族、性别、宗教、社会经济地位和其他类别歧视个人。
In this tutorial, you’ll learn about bias, which refers to negative, unwanted consequences of ML applications, especially if the consequences disproportionately affect certain groups.
在本教程中,您将了解偏见,它指的是 ML 应用程序的负面、不良后果,尤其是当这些后果对某些群体产生不成比例的影响时。
We’ll cover six different types of bias that can affect any ML application. Then you’ll put your new knowledge to work in a hands-on exercise, where you will identify bias in a real-world scenario.
我们将介绍可能影响任何 ML 应用程序的六种不同类型的偏见。然后,您将在动手练习 中运用新知识,在实际场景中识别偏见。
Bias is complex
偏见很复杂
Many ML practitioners are familiar with “biased data” and the concept of “garbage in, garbage out”. For example, if you’re training a chatbot using a dataset containing anti-Semitic online conversations (“garbage in”), the chatbot will likely make anti-Semitic remarks (“garbage out”). This example details an important type of bias (called historial bias, as you’ll see below) that should be recognized and addressed.
许多 ML 从业者都熟悉“有偏见的数据”和“垃圾进,垃圾出”的概念。例如,如果您使用包含反犹太主义在线对话(“垃圾输入”)的数据集训练聊天机器人,聊天机器人很可能会发表反犹太主义言论(“垃圾输出”)。此示例详细说明了一种重要的偏见类型(称为 历史偏见 ,如下所示),应该予以认识和解决。
This is not the only way that bias can ruin ML applications.
这不是偏见破坏 ML 应用程序的唯一方式。
Bias in data is complex. Flawed data can also result in representation bias (covered later in this tutorial), if a group is underrepresented in the training data. For instance, when training a facial detection system, if the training data contains mostly individuals with lighter skin tones, it will fail to perform well for users with darker skin tones. A third type of bias that can arise from the training data is called measurement bias, which you’ll learn about below.
数据中的偏见很复杂。如果某个群体在训练数据中的代表性不足,有缺陷的数据还会导致 代表性偏见 (本教程后面将介绍)。例如,在训练面部检测系统时,如果训练数据主要包含肤色较浅的个体,则它将无法为肤色较深的用户提供良好的效果。训练数据中可能产生的第三种偏见称为 测量偏见 ,您将在下面了解。
And it’s not just biased data that can lead to unfair ML applications: as you’ll learn, bias can also result from the way in which the ML model is defined, from the way the model is compared to other models, and from the way that everyday users interpret the final results of the model. Harm can come from anywhere in the ML process.
而且,不仅仅是有偏见的数据会导致不公平的机器学习应用:正如您将了解到的,偏见还可能来自机器学习模型的定义方式、模型与其他模型的比较方式以及日常用户对模型最终结果的解释方式。损害可能来自机器学习过程的任何地方。
Six types of bias
六种偏见
Once we’re aware of the different types of bias, we are more likely to detect them in ML projects. Furthermore, with a common vocabulary, we can have fruitful conversations about how to mitigate (or reduce) the bias.
一旦我们意识到了不同类型的偏见,我们就更有可能在 ML 项目中发现它们。此外,有了共同的词汇,我们就可以就如何减轻(或减少)偏见进行富有成效的对话。
We will closely follow a research paper from early 2020 that characterizes six different types of bias.
我们将密切关注 2020 年初的一篇 研究论文,该论文描述了六种不同类型的偏见。
Historical bias
历史偏见
Historical bias occurs when the state of the world in which the data was generated is flawed.
历史偏见 发生在数据生成的世界状态存在缺陷时。
As of 2020, only 7.4% of Fortune 500 CEOs are women. Research has shown that companies with female CEOs or CFOs are generally more profitable than companies with men in the same position, suggesting that women are held to higher hiring standards than men. In order to fix this, we might consider removing human input and using AI to make the hiring process more equitable. But this can prove unproductive if data from past hiring decisions is used to train a model, because the model will likely learn to demonstrate the same biases that are present in the data.
截至 2020 年,财富 500 强 CEO 中只有 7.4% 是女性。研究表明,拥有女性 CEO 或 CFO 的公司通常比拥有男性担任相同职位的公司 利润更高,这表明女性的招聘标准高于男性。为了解决这个问题,我们可能会考虑消除人工输入,使用人工智能使招聘流程更加公平。但如果使用过去招聘决策的数据来训练模型,这可能会毫无成效,因为模型很可能会学会展示数据中存在的相同偏见。
Representation bias
代表性偏差
Representation bias occurs when building datasets for training a model, if those datasets poorly represent the people that the model will serve.
代表性偏差 发生在构建用于训练模型的数据集时,如果这些数据集不能很好地代表模型将服务的人。
Data collected through smartphone apps will under-represent groups that are less likely to own smartphones. For instance, if collecting data in the USA, individuals over the age of 65 will be under-represented. If the data is used to inform design of a city transportation system, this will be disastrous, since older people have important needs to ensure that the system is accessible.
通过智能手机应用程序收集的数据将无法充分代表不太可能拥有智能手机的群体。例如,如果在美国收集 数据,65 岁以上的个人将无法得到充分代表。如果将这些数据用于城市交通系统的设计,这将是灾难性的,因为老年人有重要的 需求 来确保该系统的可访问性。
Measurement bias
测量偏差
Measurement bias occurs when the accuracy of the data varies across groups. This can happen when working with proxy variables (variables that take the place of a variable that cannot be directly measured), if the quality of the proxy varies in different groups.
测量偏差 是指数据准确性在不同群体之间存在差异。如果代理变量的质量在不同群体之间存在差异,则在使用代理变量(替代无法直接测量的变量的变量)时可能会发生这种情况。
Your local hospital uses a model to identify high-risk patients before they develop serious conditions, based on information like past diagnoses, medications, and demographic data. The model uses this information to predict health care costs, the idea being that patients with higher costs likely correspond to high-risk patients. Despite the fact that the model specifically excludes race, it seems to demonstrate racial discrimination: the algorithm is less likely to select eligible Black patients. How can this be the case? It is because cost was used as a proxy for risk, and the relationship between these variables varies with race: Black patients experience increased barriers to care, have less trust in the health care system, and therefore have lower medical costs, on average, when compared to non-Black patients with the same health conditions.
当地医院使用模型根据过去的诊断、药物和人口统计数据等信息,在高风险患者出现严重疾病之前识别他们。该模型使用这些信息来预测医疗保健费用,其理念是费用较高的患者可能对应于高风险患者。尽管该模型明确排除了种族,但它似乎表现出种族歧视:该算法不太可能选择符合条件的黑人患者。怎么会这样呢?这是因为成本被用作风险的代理,并且这些变量之间的关系因种族而异:与具有相同健康状况的非黑人患者相比,黑人患者在接受护理时遇到的障碍更多,对医疗保健系统的信任度更低,因此平均医疗成本更低。
Aggregation bias
聚合偏差
Aggregation bias occurs when groups are inappropriately combined, resulting in a model that does not perform well for any group or only performs well for the majority group. (This is often not an issue, but most commonly arises in medical applications.)
聚合偏差 发生在群体组合不当的情况下,导致模型对任何群体都表现不佳或仅对多数群体表现良好。(这通常不是问题,但最常出现在医疗应用中。)
Hispanics have higher rates of diabetes and diabetes-related complications than non-Hispanic whites. If building AI to diagnose or monitor diabetes, it is important to make the system sensitive to these ethnic differences, by either including ethnicity as a feature in the data, or building separate models for different ethnic groups.
与非西班牙裔白人相比,西班牙裔糖尿病和糖尿病相关并发症的发病率更高。如果要构建用于诊断或监测糖尿病的 AI,则必须使系统对这些种族差异敏感,方法是将种族作为数据中的一个特征,或者为不同种族群体构建单独的模型。
Evaluation bias
评估偏差
Evaluation bias occurs when evaluating a model, if the benchmark data (used to compare the model to other models that perform similar tasks) does not represent the population that the model will serve.
如果基准数据(用于将模型与执行类似任务的其他模型进行比较)不代表模型将服务的人群,则在评估模型时会发生评估偏差。
The Gender Shades paper discovered that two widely used facial analysis benchmark datasets (IJB-A and Adience) were primarily composed of lighter-skinned subjects (79.6% and 86.2%, respectively). Commercial gender classification AI showed state-of-the-art performance on these benchmarks, but experienced disproportionately high error rates with people of color.
Gender Shades 论文发现,两个广泛使用的面部分析基准数据集(IJB-A 和 Adience)主要由肤色较浅的受试者组成(分别为 79.6% 和 86.2%)。商业性别分类 AI 在这些基准上表现出最先进的性能,但在有色人种方面经历了不成比例的高错误率。
Deployment bias
部署偏差
Deployment bias occurs when the problem the model is intended to solve is different from the way it is actually used. If the end users don’t use the model in the way it is intended, there is no guarantee that the model will perform well.
部署偏差发生在模型旨在解决的问题与实际使用方式不同的时候。如果最终用户没有按照预期的方式使用模型,那么就无法保证模型会表现良好。
The criminal justice system uses tools to predict the likelihood that a convicted criminal will relapse into criminal behavior. The predictions are not designed for judges when deciding appropriate punishments at the time of sentencing.
We can visually represent these different types of bias, which occur at different stages in the ML workflow:
我们可以直观地表示这些不同类型的偏差,它们发生在 ML 工作流程的不同阶段:
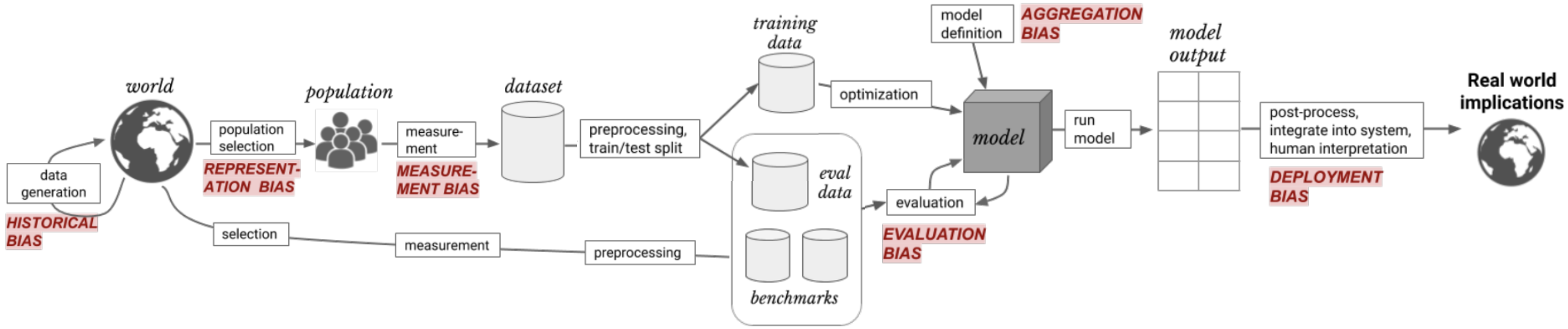
Note that these are not mutually exclusive: that is, an ML application can easily suffer from more than one type of bias. For example, as Rachel Thomas describes in a recent research talk, ML applications in wearable fitness devices can suffer from:
请注意,这些 并不相互排斥 :也就是说,ML 应用程序很容易受到多种类型的偏差的影响。例如,正如 Rachel Thomas 在 最近的研究演讲 中所描述的那样,可穿戴健身设备中的 ML 应用可能会受到以下影响:
- Representation bias (if the dataset used to train the models exclude darker skin tones),
- 表征偏差(如果用于训练模型的数据集不包括较深的肤色),
- Measurement bias (if the measurement apparatus shows reduced performance with dark skin tones), and
- 测量偏差(如果测量设备在深色肤色下性能下降),以及
- Evaluation bias (if the dataset used to benchmark the model excludes darker skin tones).
- 评估偏差(如果用于对模型进行基准测试的数据集不包括较深的肤色)。
Your turn
轮到你了
In the exercise, you will work directly with a model trained on real-world, biased data.
在练习中,你将 直接使用在现实世界中有偏差的数据上训练的模型 。