This notebook is an exercise in the Machine Learning Explainability course. You can reference the tutorial at this link.
Intro
简介
You will think about and calculate permutation importance with a sample of data from the Taxi Fare Prediction competition.
您将使用来自 出租车费预测 竞赛的数据样本来思考和计算排列重要性。
We won't focus on data exploration or model building for now. You can just run the cell below to
我们暂时不会专注于数据探索或模型构建。您只需运行下面的单元格即可
- Load the data
- 加载数据
- Divide the data into training and validation
- 将数据分为训练和验证
- Build a model that predicts taxi fares
- 构建预测出租车费的模型
- Print a few rows for you to review
- 打印几行供您查看
# Loading data, dividing, modeling and EDA below
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
data = pd.read_csv('../input/new-york-city-taxi-fare-prediction/train.csv', nrows=50000)
# Remove data with extreme outlier coordinates or negative fares
data = data.query('pickup_latitude > 40.7 and pickup_latitude < 40.8 and ' +
'dropoff_latitude > 40.7 and dropoff_latitude < 40.8 and ' +
'pickup_longitude > -74 and pickup_longitude < -73.9 and ' +
'dropoff_longitude > -74 and dropoff_longitude < -73.9 and ' +
'fare_amount > 0'
)
y = data.fare_amount
base_features = ['pickup_longitude',
'pickup_latitude',
'dropoff_longitude',
'dropoff_latitude',
'passenger_count']
X = data[base_features]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
first_model = RandomForestRegressor(n_estimators=50, random_state=1).fit(train_X, train_y)
# Environment Set-Up for feedback system.
from learntools.core import binder
binder.bind(globals())
from learntools.ml_explainability.ex2 import *
print("Setup Complete")
# show data
print("Data sample:")
data.head()Setup Complete
Data sample:| key | fare_amount | pickup_datetime | pickup_longitude | pickup_latitude | dropoff_longitude | dropoff_latitude | passenger_count | |
|---|---|---|---|---|---|---|---|---|
| 2 | 2011-08-18 00:35:00.00000049 | 5.7 | 2011-08-18 00:35:00 UTC | -73.982738 | 40.761270 | -73.991242 | 40.750562 | 2 |
| 3 | 2012-04-21 04:30:42.0000001 | 7.7 | 2012-04-21 04:30:42 UTC | -73.987130 | 40.733143 | -73.991567 | 40.758092 | 1 |
| 4 | 2010-03-09 07:51:00.000000135 | 5.3 | 2010-03-09 07:51:00 UTC | -73.968095 | 40.768008 | -73.956655 | 40.783762 | 1 |
| 6 | 2012-11-20 20:35:00.0000001 | 7.5 | 2012-11-20 20:35:00 UTC | -73.980002 | 40.751662 | -73.973802 | 40.764842 | 1 |
| 7 | 2012-01-04 17:22:00.00000081 | 16.5 | 2012-01-04 17:22:00 UTC | -73.951300 | 40.774138 | -73.990095 | 40.751048 | 1 |
The following two cells may also be useful to understand the values in the training data:
以下两个单元格可能也有助于理解训练数据中的值:
train_X.describe()| pickup_longitude | pickup_latitude | dropoff_longitude | dropoff_latitude | passenger_count | |
|---|---|---|---|---|---|
| count | 23466.000000 | 23466.000000 | 23466.000000 | 23466.000000 | 23466.000000 |
| mean | -73.976827 | 40.756931 | -73.975359 | 40.757434 | 1.662320 |
| std | 0.014625 | 0.018206 | 0.015930 | 0.018659 | 1.290729 |
| min | -73.999999 | 40.700013 | -73.999999 | 40.700020 | 0.000000 |
| 25% | -73.987964 | 40.744901 | -73.987143 | 40.745756 | 1.000000 |
| 50% | -73.979629 | 40.758076 | -73.978588 | 40.758542 | 1.000000 |
| 75% | -73.967797 | 40.769602 | -73.966459 | 40.770406 | 2.000000 |
| max | -73.900062 | 40.799952 | -73.900062 | 40.799999 | 6.000000 |
train_y.describe()count 23466.000000
mean 8.472539
std 4.609747
min 0.010000
25% 5.500000
50% 7.500000
75% 10.100000
max 165.000000
Name: fare_amount, dtype: float64Question 1
问题 1
The first model uses the following features
第一个模型使用以下特征
- pickup_longitude
- pickup_latitude
- dropoff_longitude
- dropoff_latitude
- passenger_count
Before running any code... which variables seem potentially useful for predicting taxi fares? Do you think permutation importance will necessarily identify these features as important?
在运行任何代码之前...哪些变量似乎可能对预测出租车费有用?您认为排列重要性必然会将这些特征确定为重要的吗?
Once you've thought about it, run q_1.solution() below to see how you might think about this before running the code.
考虑完之后,运行下面的 q_1.solution(),看看在运行代码之前您会如何考虑这个问题。
# Check your answer (Run this code cell to receive credit!)
q_1.solution()Solution: It would be helpful to know whether New York City taxis
vary prices based on how many passengers they have. Most places do not
change fares based on numbers of passengers.
If you assume New York City is the same, then only the top 4 features listed should matter. At first glance, it seems all of those should matter equally.
了解纽约市出租车是否根据乘客人数调整价格会很有帮助。大多数地方不会根据乘客人数调整票价。如果你假设纽约市也是如此,那么只有列出的前 4 个特点才重要。乍一看,似乎所有这些都应该同样重要。
Question 2
问题 2
Create a PermutationImportance object called perm to show the importances from first_model. Fit it with the appropriate data and show the weights.
创建一个名为perm的PermutationImportance对象,以显示first_model的重要性。使用适当的数据对其进行拟合并显示权重。
For your convenience, the code from the tutorial has been copied into a comment in this code cell.
为了方便起见,教程中的代码已复制到此代码单元的注释中。
import eli5
from eli5.sklearn import PermutationImportance
# Make a small change to the code below to use in this problem.
# perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
perm = PermutationImportance(first_model, random_state=1).fit(val_X, val_y)
# Check your answer
q_2.check()
# uncomment the following line to visualize your results
# eli5.show_weights(perm, feature_names = val_X.columns.tolist())
eli5.show_weights(perm, feature_names = val_X.columns.tolist())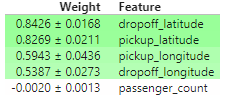
请注意,这些分数在每次运行中可能会略有不同。但总体结果每次都保持不变。
Uncomment the lines below for a hint or to see the solution.
取消注释以下几行以获得提示或查看解决方案。
# q_2.hint()
# q_2.solution()Question 3
问题 3
Before seeing these results, we might have expected each of the 4 directional features to be equally important.
在看到这些结果之前,我们可能认为 4 个方向特征都同样重要。
But, on average, the latitude features matter more than the longititude features. Can you come up with any hypotheses for this?
但平均而言,纬度特征比经度特征更重要。你能对此提出任何假设吗?
After you've thought about it, check here for some possible explanations:
考虑过后,请在此处查看一些可能的解释:
# Check your answer (Run this code cell to receive credit!)
q_3.solution()Solution:
- Travel might tend to have greater latitude distances than longitude distances. If the longitudes values were generally closer together, shuffling them wouldn't matter as much.
- Different parts of the city might have different pricing rules (e.g. price per mile), and pricing rules could vary more by latitude than longitude.
- Tolls might be greater on roads going North<->South (changing latitude) than on roads going East <-> West (changing longitude). Thus latitude would have a larger effect on the prediction because it captures the amount of the tolls.
- 旅行可能倾向于具有比经度距离更大的纬度距离。如果经度值通常更接近,则对它们进行打乱就不那么重要了。
- 城市的不同地区可能有不同的定价规则(例如每英里的价格),定价规则可能因纬度而不是经度而有所不同。
- 北向<->南(纬度变化)的道路的通行费可能比东向<->西(经度变化)的道路的通行费更高。因此,纬度对预测的影响更大,因为它捕获了通行费的金额。
Question 4
问题 4
Without detailed knowledge of New York City, it's difficult to rule out most hypotheses about why latitude features matter more than longitude.
如果不了解纽约市的详细情况,很难排除大多数关于纬度特征为何比经度更重要的假设。
A good next step is to disentangle the effect of being in certain parts of the city from the effect of total distance traveled.
下一步是将位于城市某些部分的影响与总行驶距离的影响区分开来。
The code below creates new features for longitudinal and latitudinal distance. It then builds a model that adds these new features to those you already had.
以下代码为经度和纬度距离创建了新特征。然后,它构建了一个模型,将这些新特征添加到您已有的特征中。
Fill in two lines of code to calculate and show the importance weights with this new set of features. As usual, you can uncomment lines below to check your code, see a hint or get the solution.
填写两行代码以计算并显示这组新特征的重要性权重。与往常一样,您可以取消注释以下几行以检查您的代码、查看提示或获取解决方案。
# create new features
data['abs_lon_change'] = abs(data.dropoff_longitude - data.pickup_longitude)
data['abs_lat_change'] = abs(data.dropoff_latitude - data.pickup_latitude)
features_2 = ['pickup_longitude',
'pickup_latitude',
'dropoff_longitude',
'dropoff_latitude',
'abs_lat_change',
'abs_lon_change']
X = data[features_2]
new_train_X, new_val_X, new_train_y, new_val_y = train_test_split(X, y, random_state=1)
second_model = RandomForestRegressor(n_estimators=30, random_state=1).fit(new_train_X, new_train_y)
# Create a PermutationImportance object on second_model and fit it to new_val_X and new_val_y
# Use a random_state of 1 for reproducible results that match the expected solution.
# perm2 = ____
perm2 = PermutationImportance(second_model).fit(new_val_X, new_val_y)
# show the weights for the permutation importance you just calculated
# ____
eli5.show_weights(perm2, feature_names = new_val_X.columns.tolist())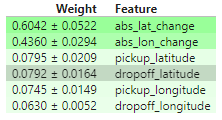
# Check your answer
q_4.check()Correct
How would you interpret these importance scores? Distance traveled seems far more important than any location effects.
您如何解释这些重要性分数?行驶距离似乎比任何位置效应都重要得多。
But the location still affects model predictions, and dropoff location now matters slightly more than pickup location. Do you have any hypotheses for why this might be? The techniques in the next lessons will help you dive into this more.
但位置仍然会影响模型预测,下车地点现在比上车地点更重要。您对这可能是什么原因有什么假设吗?下一课中的技巧将帮助您更深入地研究这一点。
# Check your answer (Run this code cell to receive credit!)
# q_4.solution()Question 5
问题 5
A colleague observes that the values for abs_lon_change and abs_lat_change are pretty small (all values are between -0.1 and 0.1), whereas other variables have larger values. Do you think this could explain why those coordinates had larger permutation importance values in this case?
一位同事观察到 abs_lon_change 和 abs_lat_change 的值非常小(所有值都在 -0.1 和 0.1 之间),而其他变量的值则较大。您认为这可以解释为什么这些坐标在这种情况下具有更大的排列重要性值吗?
Consider an alternative where you created and used a feature that was 100X as large for these features, and used that larger feature for training and importance calculations. Would this change the outputted permutaiton importance values?
考虑一种替代方案,您创建并使用了这些特征 100 倍大的特征,并使用了该较大的特征进行训练和重要性计算。这会改变输出的排列重要性值吗?
Why or why not?
为什么或为什么不?
After you have thought about your answer, either try this experiment or look up the answer in the cell below.
在您考虑好答案后,请尝试这个实验或在下面的单元格中查找答案。
# Check your answer (Run this code cell to receive credit!)
q_5.solution()Solution:
The scale of features does not affect permutation importance per se. The only reason that rescaling a feature would affect PI is indirectly, if rescaling helped or hurt the ability of the particular learning method we're using to make use of that feature.
That won't happen with tree based models, like the Random Forest used here.
If you are familiar with Ridge Regression, you might be able to think of how that would be affected.
That said, the absolute change features are have high importance because they capture total distance traveled, which is the primary determinant of taxi fares...It is not an artifact of the feature magnitude.
特征的尺度本身并不影响排列重要性。重新缩放特征会影响 PI 的唯一原因是间接的,即重新缩放是否有助于或损害了我们用于利用该特征的特定学习方法的能力。这不会发生在基于树的模型上,比如这里使用的随机森林。如果你熟悉岭回归,你可能会想到这会受到怎样的影响。也就是说,绝对变化特征具有很高的重要性,因为它们捕获了总行驶距离,这是出租车费的主要决定因素……它不是特征量级的产物。
Question 6
问题 6
You've seen that the feature importance for latitudinal distance is greater than the importance of longitudinal distance. From this, can we conclude whether travelling a fixed latitudinal distance tends to be more expensive than traveling the same longitudinal distance?
您已经看到,纬度距离的特征重要性大于经度距离的重要性。由此,我们能否得出结论,行驶固定的纬度距离是否比行驶相同的经度距离更昂贵?
Why or why not? Check your answer below.
为什么或为什么不?请在下方查看您的答案。
# Check your answer (Run this code cell to receive credit!)
q_6.solution()Solution:
We cannot tell from the permutation importance results whether traveling a fixed latitudinal distance is more or less expensive than traveling the same longitudinal distance.
Possible reasons latitude feature are more important than longitude features
- latitudinal distances in the dataset tend to be larger
- it is more expensive to travel a fixed latitudinal distance
- Both of the above
If abs_lon_change values were very small, longitues could be less important to the model even if the cost per mile of travel in that direction were high.
我们无法从排列重要性结果中判断行驶固定纬度距离是否比行驶相同经度距离更昂贵或更便宜。纬度特征比经度特征更重要的可能原因是
- 数据集中的纬度距离往往更大
- 行驶固定纬度距离更昂贵
- 以上两者如果
abs_lon_change值非常小,即使该方向每英里的旅行成本很高,经度对模型来说可能不那么重要。
Keep Going
继续
Permutation importance is useful useful for debugging, understanding your model, and communicating a high-level overview from your model.
排列重要性对于调试、理解模型以及传达模型的高级概述非常有用。
Next, learn about partial dependence plots to see how each feature affects predictions.
接下来,了解 部分依赖图 ,了解每个特征 如何 影响预测。