This notebook is an exercise in the Pandas course. You can reference the tutorial at this link.
Introduction
In this set of exercises we will work with the Wine Reviews dataset.
介绍
在这组练习中,我们将使用葡萄酒评论数据集。
Run the following cell to load your data and some utility functions (including code to check your answers).
运行以下单元格来加载您的数据和一些实用函数(包括用于检查答案的代码)。
import pandas as pd
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
from learntools.core import binder; binder.bind(globals())
from learntools.pandas.indexing_selecting_and_assigning import *
print("Setup complete.")Setup complete.Look at an overview of your data by running the following line.
通过运行以下行来查看数据的概况。
reviews.head()| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Italy | Aromas include tropical fruit, broom, brimston... | Vulkà Bianco | 87 | NaN | Sicily & Sardinia | Etna | NaN | Kerin O’Keefe | @kerinokeefe | Nicosia 2013 Vulkà Bianco (Etna) | White Blend | Nicosia |
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red | Quinta dos Avidagos |
| 2 | US | Tart and snappy, the flavors of lime flesh and... | NaN | 87 | 14.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Rainstorm 2013 Pinot Gris (Willamette Valley) | Pinot Gris | Rainstorm |
| 3 | US | Pineapple rind, lemon pith and orange blossom ... | Reserve Late Harvest | 87 | 13.0 | Michigan | Lake Michigan Shore | NaN | Alexander Peartree | NaN | St. Julian 2013 Reserve Late Harvest Riesling ... | Riesling | St. Julian |
| 4 | US | Much like the regular bottling from 2012, this... | Vintner's Reserve Wild Child Block | 87 | 65.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Sweet Cheeks 2012 Vintner's Reserve Wild Child... | Pinot Noir | Sweet Cheeks |
Exercises
练习
1.
Select the description column from reviews and assign the result to the variable desc.
从reviews中选择description列,并将结果分配给变量desc。
# Your code here
#desc = ____
desc = reviews['description']
desc
# Check your answer
q1.check()Correct
Follow-up question: what type of object is desc? If you're not sure, you can check by calling Python's type function: type(desc).
后续问题:desc是什么类型的对象? 如果你不确定,你可以通过调用Python的type函数来检查:type(desc)。
type(desc)pandas.core.series.Series#q1.hint()
q1.solution()Solution:
desc = reviews.descriptionor
desc = reviews["description"]desc is a pandas Series object, with an index matching the reviews DataFrame.
In general, when we select a single column from a DataFrame, we'll get a Series.
2.
Select the first value from the description column of reviews, assigning it to variable first_description.
从reviews的描述列中选择第一个值,将其分配给变量first_description。
#first_description = ____
first_description = reviews['description'][0]
# Check your answer
q2.check()
first_descriptionCorrect:
first_description = reviews.description.iloc[0]Note that while this is the preferred way to obtain the entry in the DataFrame, many other options will return a valid result, such as reviews.description.loc[0], reviews.description[0], and more!
"Aromas include tropical fruit, broom, brimstone and dried herb. The palate isn't overly expressive, offering unripened apple, citrus and dried sage alongside brisk acidity."#q2.hint()
q2.solution()Solution:
first_description = reviews.description.iloc[0]Note that while this is the preferred way to obtain the entry in the DataFrame, many other options will return a valid result, such as reviews.description.loc[0], reviews.description[0], and more!
3.
Select the first row of data (the first record) from reviews, assigning it to the variable first_row.
从reviews中选择第一行数据(第一条记录),并将其分配给变量first_row。
#first_row = ____
first_row = reviews.iloc[0]
# Check your answer
q3.check()
first_rowCorrect
country Italy
description Aromas include tropical fruit, broom, brimston...
...
variety White Blend
winery Nicosia
Name: 0, Length: 13, dtype: object#q3.hint()
q3.solution()Solution:
first_row = reviews.iloc[0]4.
Select the first 10 values from the description column in reviews, assigning the result to variable first_descriptions.
从reviews的description列中选择前 10 个值,将结果分配给变量first_descriptions。
Hint: format your output as a pandas Series.
提示:将输出格式化为 pandas 系列。
#first_descriptions = ____
first_descriptions = reviews.loc[:9, 'description']
# Check your answer
q4.check()
first_descriptionsCorrect:
first_descriptions = reviews.description.iloc[:10]Note that many other options will return a valid result, such as desc.head(10) and reviews.loc[:9, "description"].
0 Aromas include tropical fruit, broom, brimston...
1 This is ripe and fruity, a wine that is smooth...
...
8 Savory dried thyme notes accent sunnier flavor...
9 This has great depth of flavor with its fresh ...
Name: description, Length: 10, dtype: object#q4.hint()
q4.solution()Solution:
first_descriptions = reviews.description.iloc[:10]Note that many other options will return a valid result, such as desc.head(10) and reviews.loc[:9, "description"].
5.
Select the records with index labels 1, 2, 3, 5, and 8, assigning the result to the variable sample_reviews.
选择索引标签为1、2、3、5和8的记录,并将结果分配给变量sample_reviews。
In other words, generate the following DataFrame:
换句话说,生成以下 DataFrame:
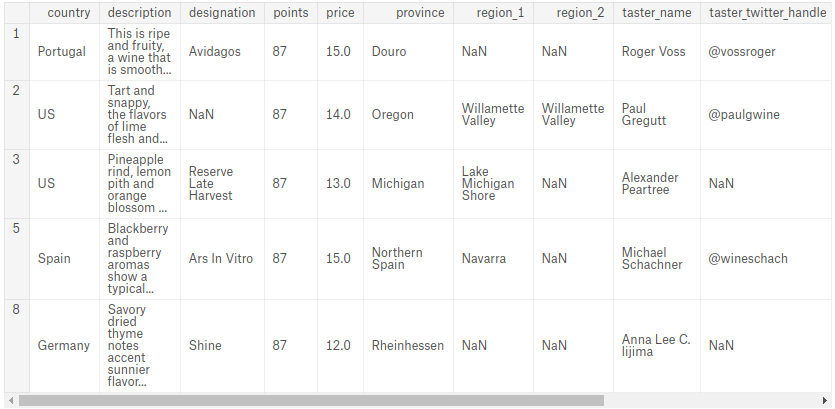
#sample_reviews = ____
sample_reviews = reviews.loc[[1,2,3,5,8,]]
# Check your answer
q5.check()
sample_reviewsCorrect
| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red | Quinta dos Avidagos |
| 2 | US | Tart and snappy, the flavors of lime flesh and... | NaN | 87 | 14.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Rainstorm 2013 Pinot Gris (Willamette Valley) | Pinot Gris | Rainstorm |
| 3 | US | Pineapple rind, lemon pith and orange blossom ... | Reserve Late Harvest | 87 | 13.0 | Michigan | Lake Michigan Shore | NaN | Alexander Peartree | NaN | St. Julian 2013 Reserve Late Harvest Riesling ... | Riesling | St. Julian |
| 5 | Spain | Blackberry and raspberry aromas show a typical... | Ars In Vitro | 87 | 15.0 | Northern Spain | Navarra | NaN | Michael Schachner | @wineschach | Tandem 2011 Ars In Vitro Tempranillo-Merlot (N... | Tempranillo-Merlot | Tandem |
| 8 | Germany | Savory dried thyme notes accent sunnier flavor... | Shine | 87 | 12.0 | Rheinhessen | NaN | NaN | Anna Lee C. Iijima | NaN | Heinz Eifel 2013 Shine Gewürztraminer (Rheinhe... | Gewürztraminer | Heinz Eifel |
#q5.hint()
q5.solution()Solution:
indices = [1, 2, 3, 5, 8]
sample_reviews = reviews.loc[indices]6.
Create a variable df containing the country, province, region_1, and region_2 columns of the records with the index labels 0, 1, 10, and 100. In other words, generate the following DataFrame:
创建一个变量df,其中包含索引标签为0、1、10和100的记录的country、province、region_1和region_2列。 换句话说,生成以下 DataFrame:
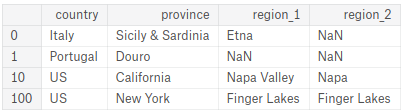
#df = ____
df = reviews.loc[[0,1,10,100],['country', 'province', 'region_1', 'region_2']]
# Check your answer
q6.check()
dfCorrect
| country | province | region_1 | region_2 | |
|---|---|---|---|---|
| 0 | Italy | Sicily & Sardinia | Etna | NaN |
| 1 | Portugal | Douro | NaN | NaN |
| 10 | US | California | Napa Valley | Napa |
| 100 | US | New York | Finger Lakes | Finger Lakes |
#q6.hint()
q6.solution()Solution:
cols = ['country', 'province', 'region_1', 'region_2']
indices = [0, 1, 10, 100]
df = reviews.loc[indices, cols]7.
Create a variable df containing the country and variety columns of the first 100 records.
创建一个变量df,其中包含前 100 条记录的country和variety列。
Hint: you may use loc or iloc. When working on the answer this question and the several of the ones that follow, keep the following "gotcha" described in the tutorial:
提示:您可以使用loc或iloc。 在回答这个问题以及接下来的几个问题时,请记住教程中描述的以下要点:
ilocuses the Python stdlib indexing scheme, where the first element of the range is included and the last one excluded.
loc, meanwhile, indexes inclusively.
iloc使用 Python stdlib 索引方案,其中包含范围的第一个元素,排除最后一个元素。
同时,loc包含索引。This is particularly confusing when the DataFrame index is a simple numerical list, e.g.
0,...,1000. In this casedf.iloc[0:1000]will return 1000 entries, whiledf.loc[0:1000]return 1001 of them! To get 1000 elements usingloc, you will need to go one lower and ask fordf.iloc[0:999].当 DataFrame 索引是一个简单的数字列表时,例如
0,...,1000。 在这种情况下,df.iloc[0:1000]将返回 1000 个条目,而df.loc[0:1000]则返回其中的 1001 个! 要使用loc获取 1000 个元素,您需要向下一级并请求df.iloc[0:999]。
#df = ____
df = reviews.loc[:99, ['country', 'variety']]
# Check your answer
q7.check()
dfCorrect:
cols = ['country', 'variety']
df = reviews.loc[:99, cols]or
cols_idx = [0, 11]
df = reviews.iloc[:100, cols_idx]| country | variety | |
|---|---|---|
| 0 | Italy | White Blend |
| 1 | Portugal | Portuguese Red |
| ... | ... | ... |
| 98 | Italy | Sangiovese |
| 99 | US | Bordeaux-style Red Blend |
100 rows × 2 columns
#q7.hint()
q7.solution()Solution:
cols = ['country', 'variety']
df = reviews.loc[:99, cols]or
cols_idx = [0, 11]
df = reviews.iloc[:100, cols_idx]8.
Create a DataFrame italian_wines containing reviews of wines made in Italy. Hint: reviews.country equals what?
创建一个DataFrameitalian_wines,其中包含意大利生产的葡萄酒的评论。 提示:reviews.country等于什么?
#italian_wines = ____
italian_wines = reviews[reviews['country'] == 'Italy']
# Check your answer
q8.check()Correct
#q8.hint()
q8.solution()Solution:
italian_wines = reviews[reviews.country == 'Italy']9.
Create a DataFrame top_oceania_wines containing all reviews with at least 95 points (out of 100) for wines from Australia or New Zealand.
创建一个DataFrame top_oceania_wines,其中包含来自澳大利亚或新西兰的葡萄酒的至少 95 分(满分 100 分)的所有评论。
#top_oceania_wines = ____
top_oceania_wines = reviews[(reviews['points'] >= 95) & (reviews['country'].isin(['Australia', 'New Zealand']))]
# Check your answer
q9.check()
top_oceania_winesCorrect
| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 345 | Australia | This wine contains some material over 100 year... | Rare | 100 | 350.0 | Victoria | Rutherglen | NaN | Joe Czerwinski | @JoeCz | Chambers Rosewood Vineyards NV Rare Muscat (Ru... | Muscat | Chambers Rosewood Vineyards |
| 346 | Australia | This deep brown wine smells like a damp, mossy... | Rare | 98 | 350.0 | Victoria | Rutherglen | NaN | Joe Czerwinski | @JoeCz | Chambers Rosewood Vineyards NV Rare Muscadelle... | Muscadelle | Chambers Rosewood Vineyards |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 122507 | New Zealand | This blend of Cabernet Sauvignon (62.5%), Merl... | SQM Gimblett Gravels Cabernets/Merlot | 95 | 79.0 | Hawke's Bay | NaN | NaN | Joe Czerwinski | @JoeCz | Squawking Magpie 2014 SQM Gimblett Gravels Cab... | Bordeaux-style Red Blend | Squawking Magpie |
| 122939 | Australia | Full-bodied and plush yet vibrant and imbued w... | The Factor | 98 | 125.0 | South Australia | Barossa Valley | NaN | Joe Czerwinski | @JoeCz | Torbreck 2013 The Factor Shiraz (Barossa Valley) | Shiraz | Torbreck |
49 rows × 13 columns
#q9.hint()
q9.solution()Solution:
top_oceania_wines = reviews.loc[
(reviews.country.isin(['Australia', 'New Zealand']))
& (reviews.points >= 95)
]Keep going
继续
Move on to learn about summary functions and maps.
继续了解摘要函数和映射。