In this tutorial, you will learn what a categorical variable is, along with three approaches for handling this type of data.
在本教程中,您将了解什么是分类变量,以及处理此类数据的三种方法。
Introduction
介绍
A categorical variable takes only a limited number of values.
分类变量仅采用有限数量的值。
- Consider a survey that asks how often you eat breakfast and provides four options: "Never", "Rarely", "Most days", or "Every day". In this case, the data is categorical, because responses fall into a fixed set of categories.
- 考虑一项调查,询问您吃早餐的频率,并提供四个选项:
从不、很少、大多数天或每天。 在这种情况下,数据是分类的,因为响应属于一组固定的类别。 - If people responded to a survey about which what brand of car they owned, the responses would fall into categories like "Honda", "Toyota", and "Ford". In this case, the data is also categorical.
- 如果人们回答关于他们拥有什么品牌汽车的调查,则回答将分为
本田、丰田和福特等类别。 在这种情况下,数据也是分类的。
You will get an error if you try to plug these variables into most machine learning models in Python without preprocessing them first. In this tutorial, we'll compare three approaches that you can use to prepare your categorical data.
如果您尝试将这些变量插入到 Python 中的大多数机器学习模型中而不首先对其进行预处理,则会出现错误。 在本教程中,我们将比较可用于准备分类数据的三种方法。
Three Approaches
三种方法
1) Drop Categorical Variables
1) 删除分类变量
The easiest approach to dealing with categorical variables is to simply remove them from the dataset. This approach will only work well if the columns did not contain useful information.
处理分类变量的最简单方法是将它们从数据集中删除。 仅当列不包含有用信息时,此方法才有效。
2) Ordinal Encoding
2) 序数编码
Ordinal encoding assigns each unique value to a different integer.
序数编码 将每个唯一值分配给不同的整数。
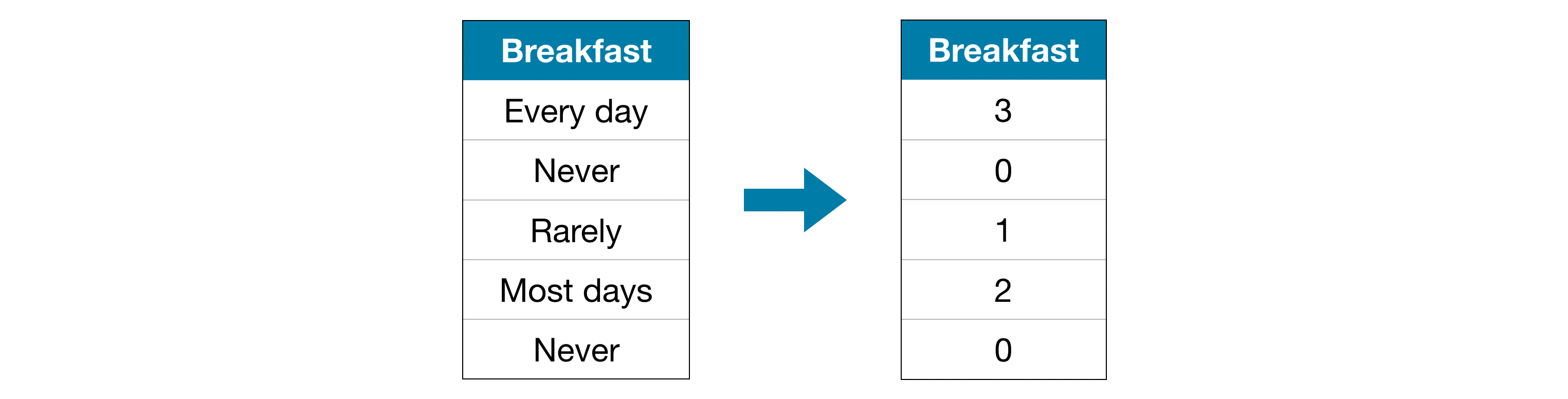
This approach assumes an ordering of the categories: "Never" (0) < "Rarely" (1) < "Most days" (2) < "Every day" (3).
此方法假设类别的顺序为:从不(0) <很少(1) <大多数天(2) <每天(3)。
This assumption makes sense in this example, because there is an indisputable ranking to the categories. Not all categorical variables have a clear ordering in the values, but we refer to those that do as ordinal variables. For tree-based models (like decision trees and random forests), you can expect ordinal encoding to work well with ordinal variables.
这个假设在这个例子中是有意义的,因为类别有无可争议的排名。 并非所有分类变量的值都有明确的顺序,但我们将那些具有明确顺序的变量称为序数变量。 对于基于树的模型(例如决策树和随机森林),您可以期望序数编码能够很好地处理序数变量。
3) One-Hot Encoding
3) One-Hot 编码
One-hot encoding creates new columns indicating the presence (or absence) of each possible value in the original data. To understand this, we'll work through an example.
One-hot 编码 创建新列,指示原始数据中每个可能值的存在(或不存在)。 为了理解这一点,我们将通过一个示例来进行操作。
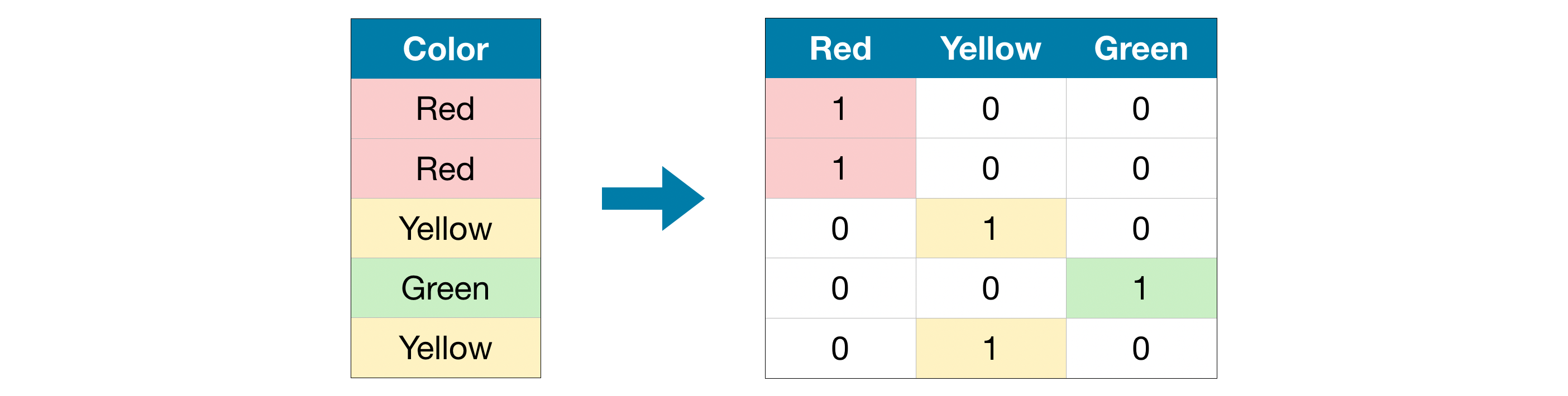
In the original dataset, "Color" is a categorical variable with three categories: "Red", "Yellow", and "Green". The corresponding one-hot encoding contains one column for each possible value, and one row for each row in the original dataset. Wherever the original value was "Red", we put a 1 in the "Red" column; if the original value was "Yellow", we put a 1 in the "Yellow" column, and so on.
在原始数据集中,颜色是一个分类变量,具有三个类别:红色、黄色和绿色。 相应的 one-hot 编码包含原始数据集中每个可能值的一列和每一行的一行。 只要原始值为Red,我们就在Red列中输入 1; 如果原始值为黄色,我们在黄色列中输入 1,依此类推。
In contrast to ordinal encoding, one-hot encoding does not assume an ordering of the categories. Thus, you can expect this approach to work particularly well if there is no clear ordering in the categorical data (e.g., "Red" is neither more nor less than "Yellow"). We refer to categorical variables without an intrinsic ranking as nominal variables.
与序数编码相反,one-hot 编码不假设类别的顺序。 因此,如果分类数据中没有明确的排序(例如,红色既不比黄色多也不少),您可以预期这种方法会特别有效。 我们将没有内在排名的分类变量称为名义变量。
One-hot encoding generally does not perform well if the categorical variable takes on a large number of values (i.e., you generally won't use it for variables taking more than 15 different values).
如果分类变量有大量不同的值(即,您通常不会将其用于采用超过 15 个不同值的变量),One-hot 编码通常表现不佳。
Example
例子
As in the previous tutorial, we will work with the Melbourne Housing dataset.
与上一个教程一样,我们将使用墨尔本住房数据集。
We won't focus on the data loading step. Instead, you can imagine you are at a point where you already have the training and validation data in X_train, X_valid, y_train, and y_valid.
我们不会关注数据加载步骤。 相反,您可以想象您已经在X_train、X_valid、y_train和y_valid中拥有训练和验证数据。
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
# 读取数据
data = pd.read_csv('../00 datasets/dansbecker/melbourne-housing-snapshot/melb_data.csv')
# Separate target from predictors
# 分离目标
y = data.Price
X = data.drop(['Price'], axis=1)
# Divide data into training and validation subsets
# 拆分训练集和验证集
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)
# Drop columns with missing values (simplest approach)
# 删除有缺失值的列
cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()]
X_train_full.drop(cols_with_missing, axis=1, inplace=True)
X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# "Cardinality" means the number of unique values in a column
# “基数”表示列中唯一值的数量
# Select categorical columns with relatively low cardinality (convenient but arbitrary)
# 选择基数相对较低的分类列(方便但随意)
low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
# Select numerical columns
# 选择数值型的列
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# Keep selected columns only
# 仅保留选择的列
my_cols = low_cardinality_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()We take a peek at the training data with the head() method below.
我们使用下面的head()方法查看训练数据。
X_train.head()| Type | Method | Regionname | Rooms | Distance | Postcode | Bedroom2 | Bathroom | Landsize | Lattitude | Longtitude | Propertycount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 12167 | u | S | Southern Metropolitan | 1 | 5.0 | 3182.0 | 1.0 | 1.0 | 0.0 | -37.85984 | 144.9867 | 13240.0 |
| 6524 | h | SA | Western Metropolitan | 2 | 8.0 | 3016.0 | 2.0 | 2.0 | 193.0 | -37.85800 | 144.9005 | 6380.0 |
| 8413 | h | S | Western Metropolitan | 3 | 12.6 | 3020.0 | 3.0 | 1.0 | 555.0 | -37.79880 | 144.8220 | 3755.0 |
| 2919 | u | SP | Northern Metropolitan | 3 | 13.0 | 3046.0 | 3.0 | 1.0 | 265.0 | -37.70830 | 144.9158 | 8870.0 |
| 6043 | h | S | Western Metropolitan | 3 | 13.3 | 3020.0 | 3.0 | 1.0 | 673.0 | -37.76230 | 144.8272 | 4217.0 |
Next, we obtain a list of all of the categorical variables in the training data.
接下来,我们获得训练数据中所有分类变量的列表。
We do this by checking the data type (or dtype) of each column. The object dtype indicates a column has text (there are other things it could theoretically be, but that's unimportant for our purposes). For this dataset, the columns with text indicate categorical variables.
我们通过检查每列的数据类型(或 dtype)来做到这一点。 object dtype 表示列包含文本(理论上它还可以是其他内容,但这对我们的目的来说并不重要)。 对于此数据集,带有文本的列表示分类变量。
# Get list of categorical variables
# 获取分类变量的列表
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)Categorical variables:
['Type', 'Method', 'Regionname']Define Function to Measure Quality of Each Approach
定义函数来衡量每种方法的质量
We define a function score_dataset() to compare the three different approaches to dealing with categorical variables. This function reports the mean absolute error (MAE) from a random forest model. In general, we want the MAE to be as low as possible!
我们定义一个函数score_dataset()来比较处理分类变量的三种不同方法。 此函数报告随机森林模型的平均绝对误差 (MAE)。 一般来说,我们希望 MAE 尽可能低!
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches
# 用于比较不同方式的函数
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)Score from Approach 1 (Drop Categorical Variables)
方法 1 的得分(删除类别变量)
We drop the object columns with the select_dtypes() method.
我们使用 select_dtypes() 方法删除 object 列。
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))MAE from Approach 1 (Drop categorical variables):
175703.48185157913Score from Approach 2 (Ordinal Encoding)
方法 2 的得分(序数编码)
Scikit-learn has a OrdinalEncoder class that can be used to get ordinal encodings. We loop over the categorical variables and apply the ordinal encoder separately to each column.
Scikit-learn 有一个 OrdinalEncoder 类,可用于获取序数编码。 我们循环分类变量并将序数编码器分别应用于每一列。
from sklearn.preprocessing import OrdinalEncoder
# Make copy to avoid changing original data
# 进行复制以避免更改原始数据
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# Apply ordinal encoder to each column with categorical data
# 将序数编码器应用到具有分类数据的每一列
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))MAE from Approach 2 (Ordinal Encoding):
165936.40548390493In the code cell above, for each column, we randomly assign each unique value to a different integer. This is a common approach that is simpler than providing custom labels; however, we can expect an additional boost in performance if we provide better-informed labels for all ordinal variables.
在上面的代码单元中,对于每一列,我们将每个唯一值随机分配给不同的整数。 这是一种常见的方法,比提供自定义标签更简单; 然而,如果我们为所有序数变量提供更明智的标签,我们可以期待性能的进一步提升。
Score from Approach 3 (One-Hot Encoding)
方法 3 的得分(One-Hot 编码)
We use the OneHotEncoder class from scikit-learn to get one-hot encodings. There are a number of parameters that can be used to customize its behavior.
我们使用 scikit-learn 中的 OneHotEncoder 类来获取 one-hot 编码。 有许多参数可用于自定义其行为。
- We set
handle_unknown='ignore'to avoid errors when the validation data contains classes that aren't represented in the training data, and - 我们设置
handle_unknown='ignore'以避免当验证数据包含训练数据中未表示的类时出现错误,并且 - setting
sparse_output=Falseensures that the encoded columns are returned as a numpy array (instead of a sparse matrix). - 设置
sparse_output=False可确保编码列作为 numpy 数组(而不是稀疏矩阵)返回。
To use the encoder, we supply only the categorical columns that we want to be one-hot encoded. For instance, to encode the training data, we supply X_train[object_cols]. (object_cols in the code cell below is a list of the column names with categorical data, and so X_train[object_cols] contains all of the categorical data in the training set.)
为了使用编码器,我们只提供我们想要进行 one-hot 编码的分类列。 例如,为了对训练数据进行编码,我们提供X_train[object_cols]。 (下面代码单元中的object_cols是包含分类数据的列名称列表,因此X_train[object_cols]包含训练集中的所有分类数据。)
from sklearn.preprocessing import OneHotEncoder
# Apply one-hot encoder to each column with categorical data
# 将 one-hot 编码器应用于具有分类数据的每一列
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding removed index; put it back
# One-hot 编码删除索引; 把它放回去
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# Remove categorical columns (will replace with one-hot encoding)
# 删除分类列(将替换为 one-hot 编码)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# Add one-hot encoded columns to numerical features
# 将 one-hot 编码列添加到数值特征中
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
# Ensure all columns have string type
# 确保所有列都是字符串类型
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))MAE from Approach 3 (One-Hot Encoding):
166089.4893009678Which approach is best?
哪种方法最好?
In this case, dropping the categorical columns (Approach 1) performed worst, since it had the highest MAE score. As for the other two approaches, since the returned MAE scores are so close in value, there doesn't appear to be any meaningful benefit to one over the other.
在这种情况下,删除分类列(方法 1)效果最差,因为它的 MAE 得分最高。 至于其他两种方法,由于返回的 MAE 分数的值非常接近,因此其中一种方法似乎没有比另一种方法有任何有意义的好处。
In general, one-hot encoding (Approach 3) will typically perform best, and dropping the categorical columns (Approach 1) typically performs worst, but it varies on a case-by-case basis.
一般来说,one-hot 编码(方法 3)通常会表现最佳,而删除分类列(方法 1)通常表现最差,但具体情况会有所不同。
Conclusion
结论
The world is filled with categorical data. You will be a much more effective data scientist if you know how to use this common data type!
世界充满了分类数据。 如果您知道如何使用这种常见数据类型,您将成为一名更高效的数据科学家!
Your Turn
到你了
Put your new skills to work in the next exercise!
在 下一个练习 中运用您的新技能!