In this tutorial, you will learn how to build and optimize models with gradient boosting. This method dominates many Kaggle competitions and achieves state-of-the-art results on a variety of datasets.
在本教程中,您将学习如何使用梯度提升构建和优化模型。 该方法在许多 Kaggle 竞赛中占据主导地位,并在各种数据集上取得了最好的结果。
Introduction
介绍
For much of this course, you have made predictions with the random forest method, which achieves better performance than a single decision tree simply by averaging the predictions of many decision trees.
在本课程的大部分时间里,您已经使用随机森林方法进行了预测,该方法通过对许多决策树的预测进行平均来实现比单个决策树更好的性能。
We refer to the random forest method as an "ensemble method". By definition, ensemble methods combine the predictions of several models (e.g., several trees, in the case of random forests).
我们将随机森林方法称为“集成方法”。 根据定义,集成方法结合了多个模型的预测(例如,在随机森林的情况下是多个树)。
Next, we'll learn about another ensemble method called gradient boosting.
接下来,我们将学习另一种称为梯度提升的集成方法。
Gradient Boosting
梯度提升
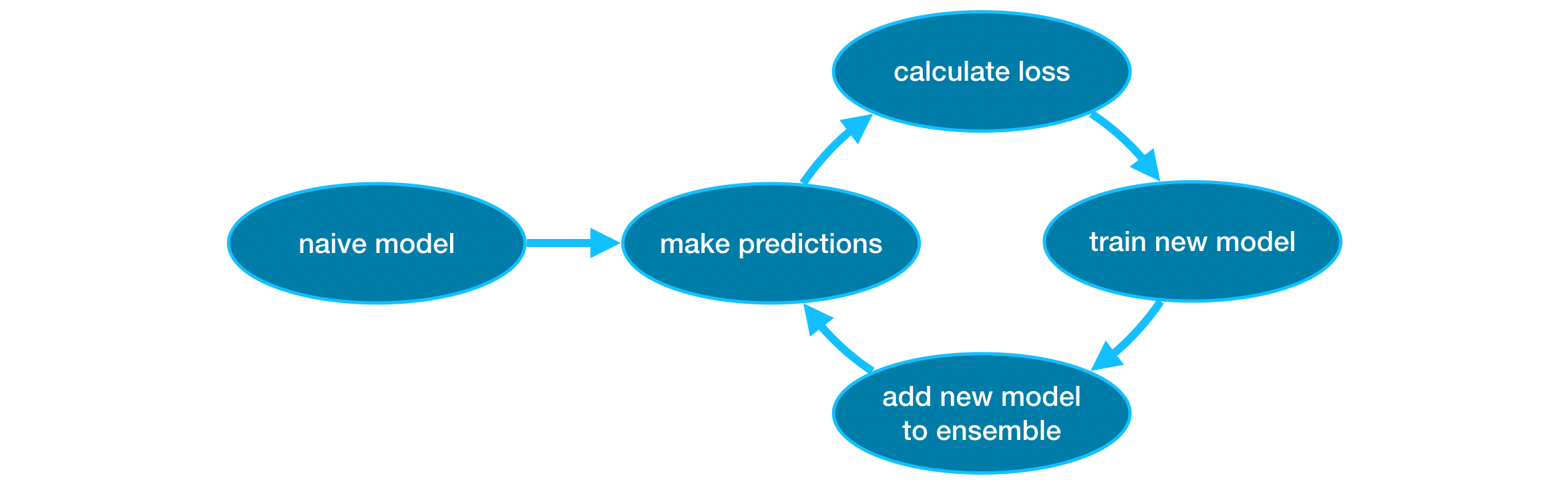
Gradient boosting is a method that goes through cycles to iteratively add models into an ensemble.
梯度提升是一种通过循环迭代将模型添加到集成中的方法。
It begins by initializing the ensemble with a single model, whose predictions can be pretty naive. (Even if its predictions are wildly inaccurate, subsequent additions to the ensemble will address those errors.)
它首先使用单个模型初始化集成,该模型的预测可能非常幼稚。 (即使它的预测非常不准确,随后对集合的添加也将解决这些错误。)
Then, we start the cycle:
然后,我们开始循环:
- First, we use the current ensemble to generate predictions for each observation in the dataset. To make a prediction, we add the predictions from all models in the ensemble.
- 首先,我们使用当前的集合来为数据集中的每个观察生成预测。 为了进行预测,我们将集合中所有模型的预测相加。
- These predictions are used to calculate a loss function (like mean squared error, for instance).
- 这些预测用于计算损失函数(例如均方误差)。
- Then, we use the loss function to fit a new model that will be added to the ensemble. Specifically, we determine model parameters so that adding this new model to the ensemble will reduce the loss. (Side note: The "gradient" in "gradient boosting" refers to the fact that we'll use gradient descent on the loss function to determine the parameters in this new model.)
- 然后,我们使用损失函数来拟合将添加到集成中的新模型。 具体来说,我们确定模型参数,以便将这个新模型添加到集成中将减少损失。 (旁注:“梯度提升”中的“梯度”指的是我们将在损失函数上使用梯度下降来确定在这个新模型中的参数 。)
- Finally, we add the new model to ensemble, and ...
- 最后,我们将新模型添加到集成中,并且......
- ... repeat!
- ... 重复!
Example
例子
We begin by loading the training and validation data in X_train, X_valid, y_train, and y_valid.
我们首先在X_train、X_valid、y_train和y_valid中加载训练和验证数据。
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
data = pd.read_csv('../00 datasets/dansbecker/melbourne-housing-snapshot/melb_data.csv')
# Select subset of predictors
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Select target
y = data.Price
# Separate data into training and validation sets
X_train, X_valid, y_train, y_valid = train_test_split(X, y)In this example, you'll work with the XGBoost library. XGBoost stands for extreme gradient boosting, which is an implementation of gradient boosting with several additional features focused on performance and speed. (Scikit-learn has another version of gradient boosting, but XGBoost has some technical advantages.)
在此示例中,您将使用 XGBoost 库。 XGBoost 代表极端梯度提升,它是梯度提升的一种实现,具有一些专注于性能和速度的附加功能。 (Scikit-learn 有另一个版本的梯度提升,但 XGBoost 有一些技术优势。)
In the next code cell, we import the scikit-learn API for XGBoost (xgboost.XGBRegressor). This allows us to build and fit a model just as we would in scikit-learn. As you'll see in the output, the XGBRegressor class has many tunable parameters -- you'll learn about those soon!
在下一个代码单元中,我们导入 XGBoost 的 scikit-learn API (xgboost.XGBRegressor)。 这使我们能够像在 scikit-learn 中一样构建和拟合模型。 正如您将在输出中看到的,XGBRegressor类有许多可调参数——您很快就会了解这些!
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=None, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=None, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
We also make predictions and evaluate the model.
我们也进行预测并评估模型。
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))Mean Absolute Error: 239639.4608431517Parameter Tuning
参数调优
XGBoost has a few parameters that can dramatically affect accuracy and training speed. The first parameters you should understand are:
XGBoost 有一些参数可以显着影响准确性和训练速度。 您应该了解的第一个参数是:
n_estimators
n_estimators
n_estimators specifies how many times to go through the modeling cycle described above. It is equal to the number of models that we include in the ensemble.
n_estimators指定经历上述建模周期的次数。 它等于我们包含在集成中的模型数量。
- Too low a value causes underfitting, which leads to inaccurate predictions on both training data and test data.
- 值太 低 会导致拟合不足,从而导致训练数据和测试数据的预测不准确。
- Too high a value causes overfitting, which causes accurate predictions on training data, but inaccurate predictions on test data (which is what we care about).
- 太 高 的值会导致 过度拟合 ,这会导致对训练数据的预测准确,但对测试数据的预测不准确(这是我们真正关心的)。
Typical values range from 100-1000, though this depends a lot on the learning_rate parameter discussed below.
典型值范围为 100-1000,但这在很大程度上取决于下面讨论的learning_rate参数。
Here is the code to set the number of models in the ensemble:
以下是设置集成中模型数量的代码:
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
early_stopping_rounds
early_stopping_rounds
early_stopping_rounds offers a way to automatically find the ideal value for n_estimators. Early stopping causes the model to stop iterating when the validation score stops improving, even if we aren't at the hard stop for n_estimators. It's smart to set a high value for n_estimators and then use early_stopping_rounds to find the optimal time to stop iterating.
early_stopping_rounds提供了一种自动查找n_estimators理想值的方法。 当验证分数停止提高时,提前停止会导致模型停止迭代,即使我们没有处于n_estimators的硬停止状态。 明智的做法是为n_estimators设置一个较高的值,然后使用early_stopping_rounds来找到停止迭代的最佳时间。
Since random chance sometimes causes a single round where validation scores don't improve, you need to specify a number for how many rounds of straight deterioration to allow before stopping. Setting early_stopping_rounds=5 is a reasonable choice. In this case, we stop after 5 straight rounds of deteriorating validation scores.
由于随机选择有时会导致单轮验证分数没有提高,因此您需要指定一个数字,表示在停止之前允许有多少轮的恶化。 设置early_stopping_rounds=5是一个合理的选择。 在这种情况下,我们在连续 5 轮验证分数恶化后停止。
When using early_stopping_rounds, you also need to set aside some data for calculating the validation scores - this is done by setting the eval_set parameter.
使用early_stopping_rounds时,您还需要留出一些数据来计算验证分数 - 这是通过设置eval_set参数来完成的。
We can modify the example above to include early stopping:
我们可以修改上面的示例以包括提前停止:
my_model = XGBRegressor(n_estimators=500, early_stopping_rounds=5,)
my_model.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)],
verbose=False)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
If you later want to fit a model with all of your data, set n_estimators to whatever value you found to be optimal when run with early stopping.
如果您稍后想要使用所有数据来拟合模型,请将n_estimators设置为您在提前停止运行时发现的最佳值。
learning_rate
学习率
Instead of getting predictions by simply adding up the predictions from each component model, we can multiply the predictions from each model by a small number (known as the learning rate) before adding them in.
我们不是通过简单地将每个组件模型的预测相加来获得预测,而是可以将每个模型的预测乘以一个小数(称为学习率),然后再添加它们。
This means each tree we add to the ensemble helps us less. So, we can set a higher value for n_estimators without overfitting. If we use early stopping, the appropriate number of trees will be determined automatically.
这意味着我们添加到集合中的每棵树对我们的帮助都会减少。 因此,我们可以为n_estimators设置更高的值而不会过度拟合。 如果我们使用提前停止,则会自动确定适当的树木数量。
In general, a small learning rate and large number of estimators will yield more accurate XGBoost models, though it will also take the model longer to train since it does more iterations through the cycle. As default, XGBoost sets learning_rate=0.1.
一般来说,较小的学习率和大量的估计器将产生更准确的 XGBoost 模型,但模型的训练时间也会更长,因为它在循环中进行了更多的迭代。 默认情况下,XGBoost 设置learning_rate=0.1。
Modifying the example above to change the learning rate yields the following code:
修改上面的示例以更改学习率会产生以下代码:
my_model = XGBRegressor(
n_estimators=1000,
learning_rate=0.05,
early_stopping_rounds=5,
)
my_model.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)],
verbose=False)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=1000, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=1000, n_jobs=None,
num_parallel_tree=None, random_state=None, ...)
n_jobs
n_jobs
On larger datasets where runtime is a consideration, you can use parallelism to build your models faster. It's common to set the parameter n_jobs equal to the number of cores on your machine. On smaller datasets, this won't help.
在考虑运行时间较长的数据集上,您可以引入并行机制来更快地构建模型。 通常将参数n_jobs设置为等于计算机上的核心数。 对于较小的数据集,这没有帮助。
The resulting model won't be any better, so micro-optimizing for fitting time is typically nothing but a distraction. But, it's useful in large datasets where you would otherwise spend a long time waiting during the fit command.
生成的模型不会更好,因此对拟合时间进行微调通常只会分散注意力。 但是,它在大型数据集中非常有用,否则您将在fit命令期间花费很长时间等待。
Here's the modified example:
这是修改后的示例:
my_model = XGBRegressor(n_estimators=1000,
learning_rate=0.05,
n_jobs=4,
early_stopping_rounds=5,
)
my_model.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)],
verbose=False)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=1000, n_jobs=4,
num_parallel_tree=None, random_state=None, ...)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=5,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=1000, n_jobs=4,
num_parallel_tree=None, random_state=None, ...)
Conclusion
结论
XGBoost is a leading software library for working with standard tabular data (the type of data you store in Pandas DataFrames, as opposed to more exotic types of data like images and videos). With careful parameter tuning, you can train highly accurate models.
XGBoost 是一个领先的软件库,用于处理标准表格数据(存储在 Pandas DataFrame 中的数据类型,而不是更奇特的数据类型,例如 图片和视频)。 通过仔细调整参数,您可以训练高度准确的模型。
Your Turn
到你了
Train your own model with XGBoost in the next exercise!
在 下一个练习 中使用 XGBoost 训练您自己的模型!