Welcome to Feature Engineering!
欢迎来到特征工程!
In this course you'll learn about one of the most important steps on the way to building a great machine learning model: feature engineering. You'll learn how to:
在本课程中,您将了解构建出色的机器学习模型的最重要步骤之一:特征工程。 您将学习如何:
- determine which features are the most important with mutual information
- 通过互信息确定哪些特征最重要
- invent new features in several real-world problem domains
- 在几个现实问题领域发明新功能
- encode high-cardinality categoricals with a target encoding
- 使用目标编码对高基数分类进行编码
- create segmentation features with k-means clustering
- 使用k-means聚类创建分段特征
- decompose a dataset's variation into features with principal component analysis
- 通过主成分分析将数据集的变量分解为特征
The hands-on exercises build up to a complete notebook that applies all of these techniques to make a submission to the House Prices Getting Started competition. After completing this course, you'll have several ideas that you can use to further improve your performance.
实践练习构建了一个完整的 笔记本 ,它应用了所有这些技术来参加 房价入门 竞赛。 完成本课程后,您将获得一些可以用来进一步提高表现的想法。
Are you ready? Let's go!
你准备好了吗? 我们开始!
The Goal of Feature Engineering
特征工程的目标
The goal of feature engineering is simply to make your data better suited to the problem at hand.
特征工程的目标很简单,就是让您的数据更适合当前的问题。
Consider "apparent temperature" measures like the heat index and the wind chill. These quantities attempt to measure the perceived temperature to humans based on air temperature, humidity, and wind speed, things which we can measure directly. You could think of an apparent temperature as the result of a kind of feature engineering, an attempt to make the observed data more relevant to what we actually care about: how it actually feels outside!
考虑“表观温度”测量,例如炎热指数和风寒。 这些量试图根据我们可以直接测量的气温、湿度和风速来测量人类的“感知”温度。 您可以将表观温度视为一种特征工程的结果,试图使观察到的数据与我们真正关心的内容更相关:外面的实际感觉如何!
You might perform feature engineering to:
您可以执行特征工程来:
- improve a model's predictive performance
- 提高模型的预测性能
- reduce computational or data needs
- 减少计算或数据需求
- improve interpretability of the results
- 提高结果的可解释性
A Guiding Principle of Feature Engineering
特征工程的指导原则
For a feature to be useful, it must have a relationship to the target that your model is able to learn. Linear models, for instance, are only able to learn linear relationships. So, when using a linear model, your goal is to transform the features to make their relationship to the target linear.
为了使某个特征有用,它必须与模型能够学习的目标有关系。 例如,线性模型只能学习线性关系。 因此,当使用线性模型时,您的目标是转换特征以使它们与目标的关系呈线性。
The key idea here is that a transformation you apply to a feature becomes in essence a part of the model itself. Say you were trying to predict the Price of square plots of land from the Length of one side. Fitting a linear model directly to Length gives poor results: the relationship is not linear.
这里的关键思想是,应用于特征的转换本质上成为模型本身的一部分。 假设您试图根据一侧的长度来预测方形土地的价格。 将线性模型直接拟合到长度会产生较差的结果:关系不是线性的。
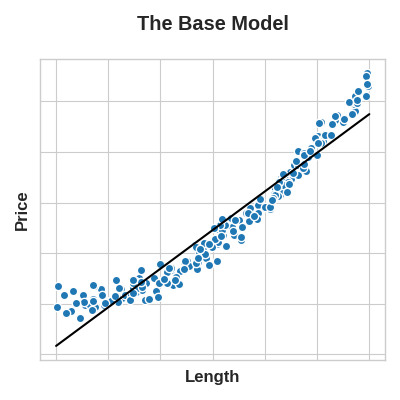
If we square the Length feature to get 'Area', however, we create a linear relationship. Adding Area to the feature set means this linear model can now fit a parabola. Squaring a feature, in other words, gave the linear model the ability to fit squared features.
然而,如果我们对长度特征求平方以获得面积,我们就会创建线性关系。 将Area添加到特征集中意味着该线性模型现在可以拟合抛物线。 换句话说,对特征进行平方使线性模型能够拟合平方特征。
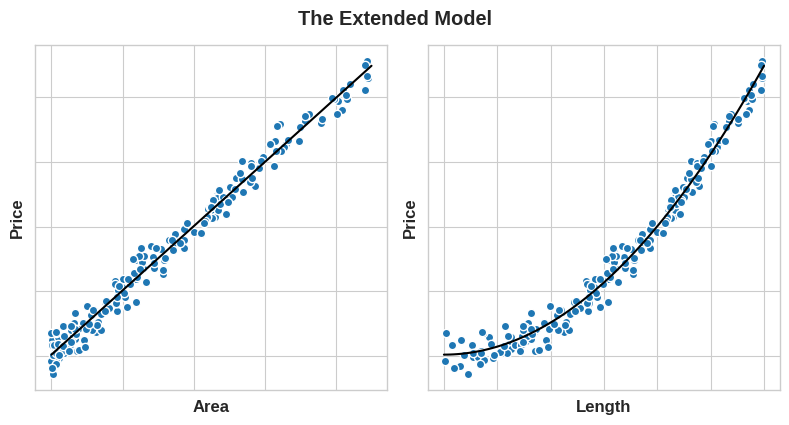
This should show you why there can be such a high return on time invested in feature engineering. Whatever relationships your model can't learn, you can provide yourself through transformations. As you develop your feature set, think about what information your model could use to achieve its best performance.
这应该向您展示为什么在特征工程上投入的时间可以获得如此高的回报。 无论您的模型无法学习到什么样的关系,您都可以通过转换来提供。 在开发特征集时,请考虑您的模型可以使用哪些信息来实现其最佳性能。
Example - Concrete Formulations
示例 - 混凝土配方
To illustrate these ideas we'll see how adding a few synthetic features to a dataset can improve the predictive performance of a random forest model.
为了说明这些想法,我们将了解如何向数据集添加一些合成特征来提高随机森林模型的预测性能。
The Concrete dataset contains a variety of concrete formulations and the resulting product's compressive strength, which is a measure of how much load that kind of concrete can bear. The task for this dataset is to predict a concrete's compressive strength given its formulation.
混凝土 数据集包含各种混凝土配方和所得产品的抗压强度,这是衡量混凝土承受的负载量的指标。 该数据集的任务是预测给定配方的混凝土的抗压强度。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
df = pd.read_csv("../00 datasets/ryanholbrook/fe-course-data/concrete.csv")
df.head()| Cement | BlastFurnaceSlag | FlyAsh | Water | Superplasticizer | CoarseAggregate | FineAggregate | Age | CompressiveStrength | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1040.0 | 676.0 | 28 | 79.99 |
| 1 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1055.0 | 676.0 | 28 | 61.89 |
| 2 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 270 | 40.27 |
| 3 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 365 | 41.05 |
| 4 | 198.6 | 132.4 | 0.0 | 192.0 | 0.0 | 978.4 | 825.5 | 360 | 44.30 |
You can see here the various ingredients going into each variety of concrete. We'll see in a moment how adding some additional synthetic features derived from these can help a model to learn important relationships among them.
您可以在这里看到各种混凝土的各种成分。 稍后我们将看到添加从这些特征派生的一些额外的综合特征如何帮助模型学习它们之间的重要关系。
We'll first establish a baseline by training the model on the un-augmented dataset. This will help us determine whether our new features are actually useful.
我们首先通过在未增强的数据集上训练模型来建立基线。 这将帮助我们确定我们的新功能是否真正有用。
Establishing baselines like this is good practice at the start of the feature engineering process. A baseline score can help you decide whether your new features are worth keeping, or whether you should discard them and possibly try something else.
在特征工程过程开始时建立这样的基线是一个很好的做法。 基线分数可以帮助您决定您的新特征是否值得保留,或者您是否应该放弃它们并可能尝试其他功能。
X = df.copy()
y = X.pop("CompressiveStrength")
# Train and score baseline model
baseline = RandomForestRegressor(criterion="absolute_error", random_state=0)
baseline_score = cross_val_score(
baseline, X, y, cv=5, scoring="neg_mean_absolute_error"
)
baseline_score = -1 * baseline_score.mean()
print(f"MAE Baseline Score: {baseline_score:.4}")MAE Baseline Score: 8.232If you ever cook at home, you might know that the ratio of ingredients in a recipe is usually a better predictor of how the recipe turns out than their absolute amounts. We might reason then that ratios of the features above would be a good predictor of CompressiveStrength.
如果您曾经在家做饭,您可能知道食谱中成分的比例通常比其绝对数量更能预测食谱的结果。 我们可能会推断,上述特征的比率将是压缩强度的良好预测指标。
The cell below adds three new ratio features to the dataset.
下面的单元格向数据集添加了三个新的比率特征。
X = df.copy()
y = X.pop("CompressiveStrength")
# Create synthetic features
X["FCRatio"] = X["FineAggregate"] / X["CoarseAggregate"]
X["AggCmtRatio"] = (X["CoarseAggregate"] + X["FineAggregate"]) / X["Cement"]
X["WtrCmtRatio"] = X["Water"] / X["Cement"]
# Train and score model on dataset with additional ratio features
model = RandomForestRegressor(criterion="absolute_error", random_state=0)
score = cross_val_score(
model, X, y, cv=5, scoring="neg_mean_absolute_error"
)
score = -1 * score.mean()
print(f"MAE Score with Ratio Features: {score:.4}")MAE Score with Ratio Features: 7.948And sure enough, performance improved! This is evidence that these new ratio features exposed important information to the model that it wasn't detecting before.
果然,性能提高了! 这证明这些新的比率特征向模型暴露了之前未检测到的重要信息。
Continue
继续
We've seen that engineering new features can improve model performance. But how do you identify features in the dataset that might be useful to combine? Discover useful features with mutual information.
我们已经看到设计新特征可以提高模型性能。 但是如何识别数据集中可能对组合有用的特征呢? 发现有用的特征 以及相互信息。