Introduction
介绍
Most of the techniques we've seen in this course have been for numerical features. The technique we'll look at in this lesson, target encoding, is instead meant for categorical features. It's a method of encoding categories as numbers, like one-hot or label encoding, with the difference that it also uses the target to create the encoding. This makes it what we call a supervised feature engineering technique.
我们在本课程中看到的大多数技术都是针对数字特征的。 我们将在本课中介绍的技术“目标编码”适用于分类特征。 它是一种将类别编码为数字的方法,类似于 one-hot 或标签编码,不同之处在于它还使用 target 来创建编码。 这使得它成为我们所说的监督特征工程技术。
import pandas as pd
autos = pd.read_csv("../00 datasets/ryanholbrook/fe-course-data/autos.csv")Target Encoding
目标编码
A target encoding is any kind of encoding that replaces a feature's categories with some number derived from the target.
目标编码是用从目标派生的一些用数字来替换特征类别的各种类型的编码。
A simple and effective version is to apply a group aggregation from Lesson 3, like the mean. Using the Automobiles dataset, this computes the average price of each vehicle's make:
一个简单而有效的版本是应用第 3 课中的组聚合,例如平均值。 使用 Automobiles 数据集,计算每辆车品牌的平均价格:
autos["make_encoded"] = autos.groupby("make")["price"].transform("mean")
autos[["make", "price", "make_encoded"]].head(10)| make | price | make_encoded | |
|---|---|---|---|
| 0 | alfa-romero | 13495 | 15498.333333 |
| 1 | alfa-romero | 16500 | 15498.333333 |
| 2 | alfa-romero | 16500 | 15498.333333 |
| 3 | audi | 13950 | 17859.166667 |
| 4 | audi | 17450 | 17859.166667 |
| 5 | audi | 15250 | 17859.166667 |
| 6 | audi | 17710 | 17859.166667 |
| 7 | audi | 18920 | 17859.166667 |
| 8 | audi | 23875 | 17859.166667 |
| 9 | bmw | 16430 | 26118.750000 |
This kind of target encoding is sometimes called a mean encoding. Applied to a binary target, it's also called bin counting. (Other names you might come across include: likelihood encoding, impact encoding, and leave-one-out encoding.)
这种目标编码有时称为平均编码。 应用于二进制目标,它也称为 二进制计数。 (您可能遇到的其他名称包括:似然编码、影响编码和留一编码。)
Smoothing
平滑
An encoding like this presents a couple of problems, however. First are unknown categories. Target encodings create a special risk of overfitting, which means they need to be trained on an independent "encoding" split. When you join the encoding to future splits, Pandas will fill in missing values for any categories not present in the encoding split. These missing values you would have to impute somehow.
然而,像这样的编码会带来一些问题。 首先是 未知类别。 目标编码会产生过度拟合的特殊风险,这意味着它们需要在独立的编码分割上进行训练。 当您将编码加入到未来的分割中时,Pandas 将填充编码分割中不存在的任何类别的缺失值。 您必须以某种方式对这些缺失值进行估算。
Second are rare categories. When a category only occurs a few times in the dataset, any statistics calculated on its group are unlikely to be very accurate. In the Automobiles dataset, the mercurcy make only occurs once. The "mean" price we calculated is just the price of that one vehicle, which might not be very representative of any Mercuries we might see in the future. Target encoding rare categories can make overfitting more likely.
其次是稀有类别。 当某个类别仅在数据集中出现几次时,对其聚合计算的任何统计数据都不太可能非常准确。 在 Automobiles 数据集中,mercurcy仅出现一次。 我们计算的平均价格只是那一辆车的价格,这可能不能很好地代表我们将来可能看到的任何mercurcy。 目标编码稀有类别可能会导致过度拟合的可能性更大。
A solution to these problems is to add smoothing. The idea is to blend the in-category average with the overall average. Rare categories get less weight on their category average, while missing categories just get the overall average.
这些问题的解决方案是添加平滑。 这个想法是将类别内平均值与整体平均值相结合。 稀有类别在其类别平均值上的权重较小,而缺失类别仅获得总体平均值。
In pseudocode:
在伪代码中:
encoding = weight * in_category + (1 - weight) * overallwhere weight is a value between 0 and 1 calculated from the category frequency.
其中权重是根据类别频率计算得出的 0 到 1 之间的值。
An easy way to determine the value for weight is to compute an m-estimate:
确定权重值的一个简单方法是计算 m 估计:
weight = n / (n + m)where n is the total number of times that category occurs in the data. The parameter m determines the "smoothing factor". Larger values of m put more weight on the overall estimate.
其中n是该类别在数据中出现的总次数。 参数m决定平滑因子。 m值越大,整体估计的权重就越大。
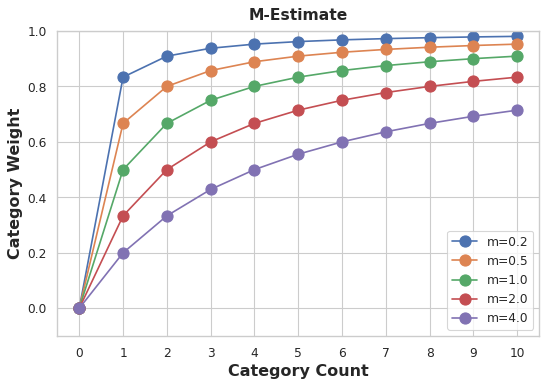
In the Automobiles dataset there are three cars with the make chevrolet. If you chose m=2.0, then the chevrolet category would be encoded with 60% of the average Chevrolet price plus 40% of the overall average price.
在 Automobiles 数据集中,有三辆汽车的品牌为chevrolet。 如果您选择m=2.0,则chevrolet类别将使用雪佛兰平均价格的 60% 加上总体平均价格的 40% 进行编码。
chevrolet = 0.6 * 6000.00 + 0.4 * 13285.03When choosing a value for m, consider how noisy you expect the categories to be. Does the price of a vehicle vary a great deal within each make? Would you need a lot of data to get good estimates? If so, it could be better to choose a larger value for m; if the average price for each make were relatively stable, a smaller value could be okay.
在选择m的值时,请考虑您期望类别的噪音程度。 不同品牌的车辆价格是否相差很大? 您需要大量数据才能获得良好的估计吗? 如果是这样,最好为m选择一个更大的值; 如果每个品牌的平均价格相对稳定,较小的值也可以。
Use Cases for Target Encoding
目标编码的用例Target encoding is great for:
目标编码非常适合:High-cardinality features: A feature with a large number of categories can be troublesome to encode: a one-hot encoding would generate too many features and alternatives, like a label encoding, might not be appropriate for that feature. A target encoding derives numbers for the categories using the feature's most important property: its relationship with the target.
高基数特征:具有大量类别的特征可能很难编码:one-hot 编码会生成太多特征,而替代方案(例如标签编码)可能不适合该特征。 目标编码使用特征最重要的属性(它与目标的关系)导出类别的数字。
Domain-motivated features: From prior experience, you might suspect that a categorical feature should be important even if it scored poorly with a feature metric. A target encoding can help reveal a feature's true informativeness.
领域驱动的特征:根据之前的经验,您可能会怀疑分类特征应该很重要,即使它在特征指标上得分很低。 目标编码可以帮助揭示特征的真实信息量。
Example - MovieLens1M
示例 - MovieLens1M
The MovieLens1M dataset contains one-million movie ratings by users of the MovieLens website, with features describing each user and movie. This hidden cell sets everything up:
MovieLens1M 数据集包含 MovieLens 网站用户的一百万部电影评分,包含描述每个用户和电影的特征。 这个隐藏的单元格设置了一切:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import warnings
plt.style.use("seaborn-v0_8-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
warnings.filterwarnings('ignore')
df = pd.read_csv("../00 datasets/ryanholbrook/fe-course-data/movielens1m.csv")
df = df.astype(np.uint8, errors='ignore') # reduce memory footprint
print("Number of Unique Zipcodes: {}".format(df["Zipcode"].nunique()))Number of Unique Zipcodes: 3439With over 3000 categories, the Zipcode feature makes a good candidate for target encoding, and the size of this dataset (over one-million rows) means we can spare some data to create the encoding.
Zipcode特征拥有超过 3000 个类别,是目标编码的良好候选者,并且该数据集的大小(超过一百万行)意味着我们可以节省一些数据来创建编码。
We'll start by creating a 25% split to train the target encoder.
我们将首先分割出 25% 的训练数据来创建目标编码器。
X = df.copy()
y = X.pop('Rating')
X_encode = X.sample(frac=0.25)
y_encode = y[X_encode.index]
X_pretrain = X.drop(X_encode.index)
y_train = y[X_pretrain.index]The category_encoders package in scikit-learn-contrib implements an m-estimate encoder, which we'll use to encode our Zipcode feature.
scikit-learn-contrib中的category_encoders包实现了一个 m 估计编码器,我们将用它来编码Zipcode功能。
# !pip install category_encoders
from category_encoders import MEstimateEncoder
# Create the encoder instance. Choose m to control noise.
# 创建编码器实例。 选择 m 来控制噪声。
encoder = MEstimateEncoder(cols=["Zipcode"], m=5.0)
# Fit the encoder on the encoding split.
# 编码分割数据集上训练编码器。
encoder.fit(X_encode, y_encode)
# Encode the Zipcode column to create the final training data
# 对 Zipcode 列进行编码以创建最终的训练数据
X_train = encoder.transform(X_pretrain)# 对比转化后的数据以及目标值
X_train[['Zipcode']].join(y)| Zipcode | Rating | |
|---|---|---|
| 1 | 3.028825 | 4 |
| 2 | 3.289590 | 1 |
| 3 | 3.635538 | 5 |
| 4 | 3.826385 | 4 |
| 5 | 3.212235 | 2 |
| ... | ... | ... |
| 1000202 | 3.641468 | 5 |
| 1000203 | 3.643851 | 4 |
| 1000205 | 3.741774 | 1 |
| 1000206 | 3.779227 | 5 |
| 1000207 | 3.772728 | 3 |
750157 rows × 2 columns
Let's compare the encoded values to the target to see how informative our encoding might be.
让我们将编码值与目标进行比较,看看我们的编码可以提供多少信息。
plt.figure(dpi=90)
ax = sns.distplot(y, kde=False, norm_hist=True)
# ax = sns.histplot(y, kde=False, norm_hist=True)
ax = sns.kdeplot(X_train.Zipcode, color='r', ax=ax)
ax.set_xlabel("Rating")
ax.legend(labels=['Zipcode', 'Rating']);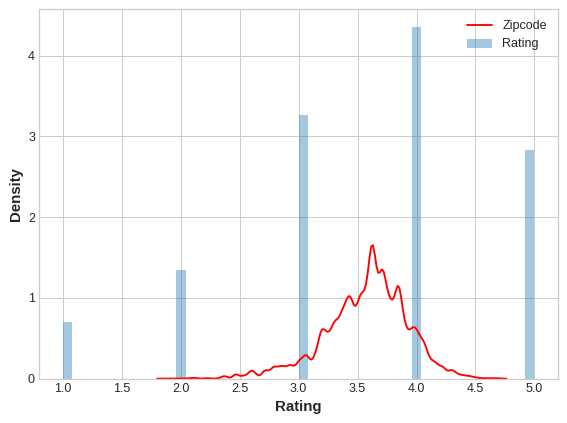
The distribution of the encoded Zipcode feature roughly follows the distribution of the actual ratings, meaning that movie-watchers differed enough in their ratings from zipcode to zipcode that our target encoding was able to capture useful information.
编码后的Zipcode特征的分布大致遵循实际评分的分布,这意味着电影观看者的评分在不同邮政编码之间有足够的差异,我们的目标编码能够捕获有用的信息。
Your Turn
到你了
Apply target encoding to features in Ames and investigate a surprising way that target encoding can lead to overfitting.
对于 Ames 中的特征应用目标编码,并研究目标编码可能导致令人惊讶的过度拟合。