Introduction
介绍
Structured Query Language, or SQL, is the programming language used with databases, and it is an important skill for any data scientist. In this course, you'll build your SQL skills using BigQuery, a web service that lets you apply SQL to huge datasets.
结构化查询语言(或 SQL)是用于数据库的编程语言,对于任何数据科学家来说都是一项重要技能。 在本课程中,您将使用 BigQuery 培养您的 SQL 技能,这是一项可让您将 SQL 应用于大型数据集的 Web 服务。
In this lesson, you'll learn the basics of accessing and examining BigQuery datasets. After you have a handle on these basics, we'll come back to build your SQL skills.
在本课程中,您将学习访问和检查 BigQuery 数据集的基础知识。 在您掌握了这些基础知识后,我们将回来培养您的 SQL 技能。
Your first BigQuery commands
您的第一个 BigQuery 命令
To use BigQuery, we'll import the Python package below:
要使用 BigQuery,我们将导入以下 Python 包:
# 非Kaggle环境,需要安装google cloud SDK
# https://cloud.google.com/sdk/docs/install#deb For Installation
# https://cloud.google.com/docs/authentication/provide-credentials-adc#how-to For Config
# gcloud auth application-default login
# gcloud auth list
# gcloud config set project PROJECT_NAME
from google.cloud import bigqueryThe first step in the workflow is to create a Client object. As you'll soon see, this Client object will play a central role in retrieving information from BigQuery datasets.
工作流程的第一步是创建一个 Client 对象。 您很快就会看到,这个Client对象将在从 BigQuery 数据集中检索信息中发挥核心作用。
# Create a "Client" object
client = bigquery.Client()/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
/home/codespace/.python/current/lib/python3.10/site-packages/google/auth/_default.py:76: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK without a quota project. You might receive a "quota exceeded" or "API not enabled" error. See the following page for troubleshooting: https://cloud.google.com/docs/authentication/adc-troubleshooting/user-creds.
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)We'll work with a dataset of posts on Hacker News, a website focusing on computer science and cybersecurity news.
我们将使用 Hacker News 上的帖子数据集,这是一个专注于计算机科学和网络安全新闻的网站。
In BigQuery, each dataset is contained in a corresponding project. In this case, our hacker_news dataset is contained in the bigquery-public-data project. To access the dataset,
在 BigQuery 中,每个数据集都包含在相应的项目中。 在本例中,我们的hacker_news数据集包含在bigquery-public-data项目中。 要访问数据集,
- We begin by constructing a reference to the dataset with the
dataset()method. - 我们首先使用
dataset()方法构建对数据集的引用。 - Next, we use the
get_dataset()method, along with the reference we just constructed, to fetch the dataset. - 接下来,我们使用
get_dataset()方法以及我们刚刚构建的引用来获取数据集。
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)Every dataset is just a collection of tables. You can think of a dataset as a spreadsheet file containing multiple tables, all composed of rows and columns.
每个数据集只是表的集合。 您可以将数据集视为包含多个表的电子表格文件,所有表均由行和列组成。
We use the list_tables() method to list the tables in the dataset.
我们使用list_tables()方法列出数据集中的表。
# List all the tables in the "hacker_news" dataset
# 列出“hacker_news”数据集中的所有表
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset (there are four!)
# 打印数据集中所有表的名称(有四个!)
for table in tables:
print(table.table_id)fullSimilar to how we fetched a dataset, we can fetch a table. In the code cell below, we fetch the full table in the hacker_news dataset.
与获取数据集的方式类似,我们可以获取表。 在下面的代码单元中,我们获取hacker_news数据集中的full表。
# Construct a reference to the "full" table
table_ref = dataset_ref.table("full")
# API request - fetch the table
table = client.get_table(table_ref)In the next section, you'll explore the contents of this table in more detail. For now, take the time to use the image below to consolidate what you've learned so far.
在下一节中,您将更详细地探讨该表的内容。 现在,花点时间使用下图来巩固您到目前为止所学到的知识。
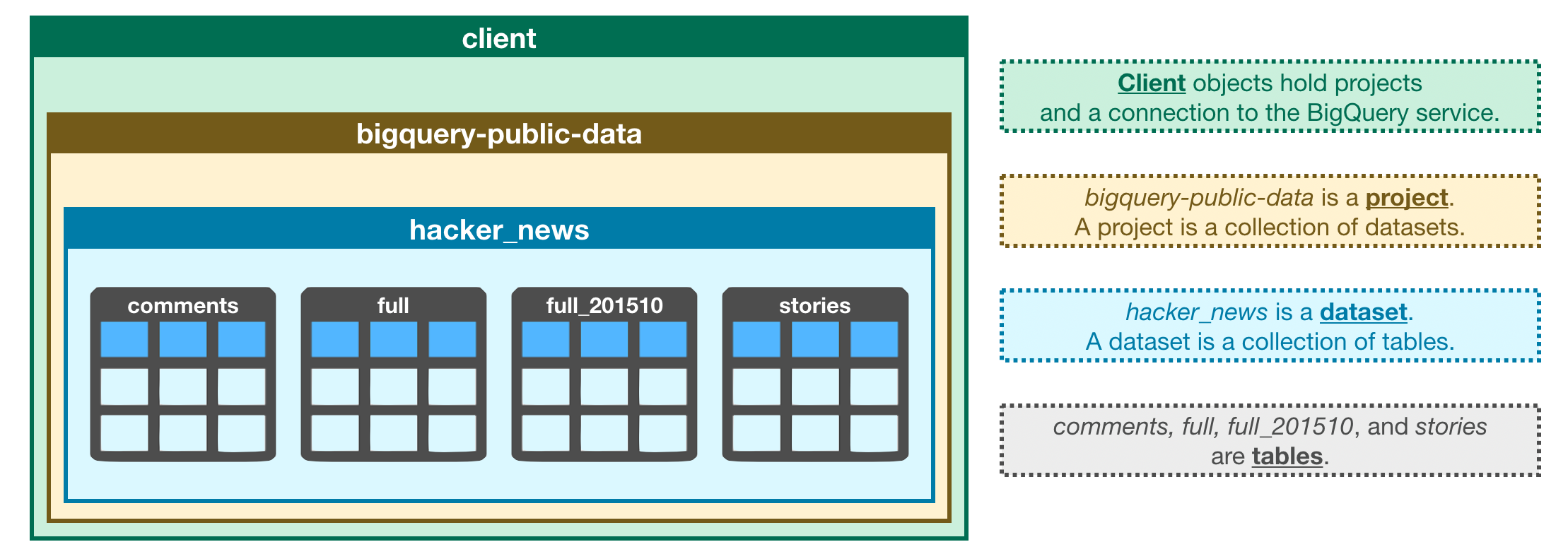
Table schema
表模式
The structure of a table is called its schema. We need to understand a table's schema to effectively pull out the data we want.
表的结构称为其模式。 我们需要了解表的模式才能有效地提取我们想要的数据。
In this example, we'll investigate the full table that we fetched above.
在此示例中,我们将研究上面获取的full表。
# Print information on all the columns in the "full" table in the "hacker_news" dataset
# 打印“hacker_news”数据集中“full”表中所有列的信息
table.schema[SchemaField('title', 'STRING', 'NULLABLE', None, 'Story title', (), None),
SchemaField('url', 'STRING', 'NULLABLE', None, 'Story url', (), None),
SchemaField('text', 'STRING', 'NULLABLE', None, 'Story or comment text', (), None),
SchemaField('dead', 'BOOLEAN', 'NULLABLE', None, 'Is dead?', (), None),
SchemaField('by', 'STRING', 'NULLABLE', None, "The username of the item's author.", (), None),
SchemaField('score', 'INTEGER', 'NULLABLE', None, 'Story score', (), None),
SchemaField('time', 'INTEGER', 'NULLABLE', None, 'Unix time', (), None),
SchemaField('timestamp', 'TIMESTAMP', 'NULLABLE', None, 'Timestamp for the unix time', (), None),
SchemaField('type', 'STRING', 'NULLABLE', None, 'type of details (comment comment_ranking poll story job pollopt)', (), None),
SchemaField('id', 'INTEGER', 'NULLABLE', None, "The item's unique id.", (), None),
SchemaField('parent', 'INTEGER', 'NULLABLE', None, 'Parent comment ID', (), None),
SchemaField('descendants', 'INTEGER', 'NULLABLE', None, 'Number of story or poll descendants', (), None),
SchemaField('ranking', 'INTEGER', 'NULLABLE', None, 'Comment ranking', (), None),
SchemaField('deleted', 'BOOLEAN', 'NULLABLE', None, 'Is deleted?', (), None)]Each SchemaField tells us about a specific column (which we also refer to as a field). In order, the information is:
每个 SchemaField告诉我们特定的列(我们也将其称为字段)。 按顺序,信息依次是:
- The name of the column
- 列的名称
- The field type (or datatype) in the column
- 列中的字段类型(或数据类型)
- The mode of the column (
'NULLABLE'means that a column allows NULL values, and is the default) - 列的模式(“NULLABLE”表示列允许 NULL 值,并且是默认值)
- A description of the data in that column
- 该列中数据的 描述
The first field has the SchemaField:
第一个字段有 SchemaField:
SchemaField('by', 'string', 'NULLABLE', "The username of the item's author.",())
This tells us:
这告诉我们:
- the field (or column) is called
by, - 字段(或列)称为
by, - the data in this field is strings,
- 该字段中的数据是字符串,
- NULL values are allowed, and
- 允许 NULL 值,并且
- it contains the usernames corresponding to each item's author.
- 它包含与每个项目的作者相对应的用户名。
We can use the list_rows() method to check just the first five lines of of the full table to make sure this is right. (Sometimes databases have outdated descriptions, so it's good to check.) This returns a BigQuery RowIterator object that can quickly be converted to a pandas DataFrame with the to_dataframe() method.
我们可以使用 list_rows() 方法仅检查full表的前五行,以确保这是正确的。 (有时数据库有过时的描述,所以最好检查一下。)这会返回一个 BigQuery RowIterator 对象,可以使用 to_dataframe() 快速转换为 Pandas DataFrame。
# Preview the first five lines of the "full" table
# pip install db-dtypes
client.list_rows(table, max_results=5).to_dataframe()| title | url | text | dead | by | score | time | timestamp | type | id | parent | descendants | ranking | deleted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | None | If the crocodile looked him up on Google, we b... | <NA> | raxxorrax | <NA> | 1633421535 | 2021-10-05 08:12:15+00:00 | comment | 28756662 | 28750122 | <NA> | <NA> | <NA> |
| 1 | None | None | What exactly are you looking for? I think Pyto... | <NA> | abiro | <NA> | 1569141387 | 2019-09-22 08:36:27+00:00 | comment | 21040311 | 21040141 | <NA> | <NA> | <NA> |
| 2 | None | None | Ironically, this very project might help out w... | <NA> | mjevans | <NA> | 1505769703 | 2017-09-18 21:21:43+00:00 | comment | 15279716 | 15276626 | <NA> | <NA> | <NA> |
| 3 | None | None | As you start to gain some experience it can be... | <NA> | every_other | <NA> | 1538575027 | 2018-10-03 13:57:07+00:00 | comment | 18130207 | 18128477 | <NA> | <NA> | <NA> |
| 4 | None | None | That’s what I was referring to, yes. I heard o... | <NA> | manmal | <NA> | 1615664155 | 2021-03-13 19:35:55+00:00 | comment | 26449260 | 26449237 | <NA> | <NA> | <NA> |
The list_rows() method will also let us look at just the information in a specific column. If we want to see the first five entries in the by column, for example, we can do that!
list_rows() 方法还可以让我们只查看特定列中的信息。 例如,如果我们想查看by列中的前五个条目,我们可以这样做!
# Preview the first five entries in the "by" column of the "full" table
# 预览“full”表的“by”列中的前五个条目
client.list_rows(table, selected_fields=table.schema[:1], max_results=5).to_dataframe()| title | |
|---|---|
| 0 | None |
| 1 | None |
| 2 | None |
| 3 | None |
| 4 | None |
Disclaimer
声明
Before we go into the coding exercise, a quick disclaimer for those who already know some SQL:
在我们开始编码练习之前,对于那些已经了解一些 SQL 的人来说,有一个快速的声明:
Each Kaggle user can scan 5TB every 30 days for free. Once you hit that limit, you'll have to wait for it to reset.
每个 Kaggle 用户每 30 天可以免费扫描 5TB 数据。 一旦达到该限制,您将不得不等待它重置。
The commands you've seen so far won't demand a meaningful fraction of that limit. But some BiqQuery datasets are huge. So, if you already know SQL, wait to run SELECT queries until you've seen how to use your allotment effectively. If you are like most people reading this, you don't know how to write these queries yet, so you don't need to worry about this disclaimer.
到目前为止,您所看到的命令不会要求该限制的有意义的一部分。 但有些 BiqQuery 数据集非常庞大。 因此,如果您已经了解 SQL,请等待运行 SELECT 查询,直到您了解如何有效地使用您的份额。 如果您像大多数阅读本文的人一样,您还不知道如何编写这些查询,因此您无需担心此声明。
Your turn
到你了
Practice the commands you've seen to explore the structure of a dataset with crimes in the city of Chicago.
使用芝加哥市的犯罪事件来通过练习您所见过的命令来 探索数据集的结构 。