In this notebook, we're going to work with dates.
在此笔记本中,我们将处理日期。
Let's get started!
让我们开始吧!
Get our environment set up
设置我们的环境
The first thing we'll need to do is load in the libraries and dataset we'll be using. We'll be working with a dataset that contains information on landslides that occured between 2007 and 2016. In the following exercise, you'll apply your new skills to a dataset of worldwide earthquakes.
我们需要做的第一件事是加载我们将使用的库和数据集。 我们将使用包含 2007 年至 2016 年期间发生的山体滑坡信息的数据集。在以下练习中,您会将您的新技能应用于全球地震数据集。
# modules we'll use
import pandas as pd
import numpy as np
import seaborn as sns
import datetime
# read in our data
landslides = pd.read_csv("../00 datasets/nasa/landslide-events/catalog.csv")
# set seed for reproducibility
np.random.seed(0)Now we're ready to look at some dates!
现在我们准备好看看一些日期了!
Check the data type of our date column
检查日期列的数据类型
We begin by taking a look at the first five rows of the data.
我们首先查看数据的前五行。
landslides.head()| id | date | time | continent_code | country_name | country_code | state/province | population | city/town | distance | ... | geolocation | hazard_type | landslide_type | landslide_size | trigger | storm_name | injuries | fatalities | source_name | source_link | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 34 | 3/2/07 | Night | NaN | United States | US | Virginia | 16000 | Cherry Hill | 3.40765 | ... | (38.600900000000003, -77.268199999999993) | Landslide | Landslide | Small | Rain | NaN | NaN | NaN | NBC 4 news | http://www.nbc4.com/news/11186871/detail.html |
| 1 | 42 | 3/22/07 | NaN | NaN | United States | US | Ohio | 17288 | New Philadelphia | 3.33522 | ... | (40.517499999999998, -81.430499999999995) | Landslide | Landslide | Small | Rain | NaN | NaN | NaN | Canton Rep.com | http://www.cantonrep.com/index.php?ID=345054&C... |
| 2 | 56 | 4/6/07 | NaN | NaN | United States | US | Pennsylvania | 15930 | Wilkinsburg | 2.91977 | ... | (40.4377, -79.915999999999997) | Landslide | Landslide | Small | Rain | NaN | NaN | NaN | The Pittsburgh Channel.com | https://web.archive.org/web/20080423132842/htt... |
| 3 | 59 | 4/14/07 | NaN | NaN | Canada | CA | Quebec | 42786 | Châteauguay | 2.98682 | ... | (45.322600000000001, -73.777100000000004) | Landslide | Riverbank collapse | Small | Rain | NaN | NaN | NaN | Le Soleil | http://www.hebdos.net/lsc/edition162007/articl... |
| 4 | 61 | 4/15/07 | NaN | NaN | United States | US | Kentucky | 6903 | Pikeville | 5.66542 | ... | (37.432499999999997, -82.493099999999998) | Landslide | Landslide | Small | Downpour | NaN | NaN | 0.0 | Matthew Crawford (KGS) | NaN |
5 rows × 23 columns
We'll be working with the "date" column from the landslides dataframe. Let's make sure it actually looks like it contains dates.
我们将使用landslides数据框中的date列。 让我们确保它实际上看起来包含日期。
# print the first few rows of the date column
print(landslides['date'].head())0 3/2/07
1 3/22/07
2 4/6/07
3 4/14/07
4 4/15/07
Name: date, dtype: objectYep, those are dates! But just because I, a human, can tell that these are dates doesn't mean that Python knows that they're dates. Notice that at the bottom of the output of head(), you can see that it says that the data type of this column is "object".
是的,那些是日期! 但仅仅因为我,一个人类,可以知道这些是日期,并不意味着 Python 知道它们是日期。 请注意,在head()输出的底部,您可以看到它表明该列的数据类型是object。
Pandas uses the "object" dtype for storing various types of data types, but most often when you see a column with the dtype "object" it will have strings in it.
Pandas 使用
object数据类型来存储各种类型的数据类型,但大多数情况下,当您看到数据类型为object的列时,它会包含字符串。
If you check the pandas dtype documentation here, you'll notice that there's also a specific datetime64 dtypes. Because the dtype of our column is object rather than datetime64, we can tell that Python doesn't know that this column contains dates.
如果您检查 pandas dtype 文档此处,您会注意到还有一个特定的datetime64dtypes。 因为我们列的数据类型是object而不是datetime64,所以我们可以知道Python不知道该列包含日期。
We can also look at just the dtype of a column without printing the first few rows:
我们还可以只查看列的 dtype,而不打印前几行:
# check the data type of our date column
landslides['date'].dtypedtype('O')You may have to check the numpy documentation to match the letter code to the dtype of the object. "O" is the code for "object", so we can see that these two methods give us the same information.
您可能需要检查numpy文档以匹配对象数据类型的字母代码。 O是object的代码,所以我们可以看到这两个方法给了我们相同的信息。
Convert our date columns to datetime
将日期列转换为日期时间
Now that we know that our date column isn't being recognized as a date, it's time to convert it so that it is recognized as a date. This is called "parsing dates" because we're taking in a string and identifying its component parts.
现在我们知道我们的日期列没有被识别为日期,是时候将其转换为可以识别的日期了。 这称为解析日期,因为我们接收一个字符串并识别其组成部分。
We can determine what the format of our dates are with a guide called "strftime directive", which you can find more information on at this link. The basic idea is that you need to point out which parts of the date are where and what punctuation is between them. There are lots of possible parts of a date, but the most common are %d for day, %m for month, %y for a two-digit year and %Y for a four digit year.
我们可以通过名为strftime 指令来确定日期的格式,您可以在此链接中找到更多信息。 基本思想是,您需要指出日期的哪些部分在哪里以及它们之间的标点符号是什么。 日期有很多可能的部分,但最常见的是%d表示日、%m表示月份、%y表示两位数年份和%Y表示四位数年份。
Some examples:
一些例子:
- 1/17/07 has the format "%m/%d/%y"
- 2007 年 1 月 17 日的格式为
%m/%d/%y - 17-1-2007 has the format "%d-%m-%Y"
- 17-1-2007 的格式为
%d-%m-%Y
Looking back up at the head of the "date" column in the landslides dataset, we can see that it's in the format "month/day/two-digit year", so we can use the same syntax as the first example to parse in our dates:
回顾一下山体滑坡数据集中日期列的头部,我们可以看到它的格式是月/日/两位数年份,因此我们可以使用与第一个示例相同的语法来解析 我们的日期:
# create a new column, date_parsed, with the parsed dates
landslides['date_parsed'] = pd.to_datetime(landslides['date'], format="%m/%d/%y")Now when I check the first few rows of the new column, I can see that the dtype is datetime64. I can also see that my dates have been slightly rearranged so that they fit the default order datetime objects (year-month-day).
现在,当我检查新列的前几行时,我可以看到 dtype 是datetime64。 我还可以看到我的日期已稍微重新排列,以便它们符合默认顺序的日期时间(年月日)。
# print the first few rows
landslides['date_parsed'].head()0 2007-03-02
1 2007-03-22
2 2007-04-06
3 2007-04-14
4 2007-04-15
Name: date_parsed, dtype: datetime64[ns]Now that our dates are parsed correctly, we can interact with them in useful ways.
现在我们的日期已正确解析了,我们可以以有用的方式与它们交互。
- What if I run into an error with multiple date formats? While we're specifying the date format here, sometimes you'll run into an error when there are multiple date formats in a single column. If that happens, you can have pandas try to infer what the right date format should be. You can do that like so:
- 如果我遇到多种日期格式的错误怎么办? 虽然我们在此处指定日期格式,但有时当单列中存在多种日期格式时,您会遇到错误。 如果发生这种情况,您可以让 pandas 尝试推断正确的日期格式应该是什么。 你可以这样做:
landslides['date_parsed'] = pd.to_datetime(landslides['Date'], infer_datetime_format=True)
- Why don't you always use
infer_datetime_format = True?There are two big reasons not to always have pandas guess the time format. The first is that pandas won't always been able to figure out the correct date format, especially if someone has gotten creative with data entry. The second is that it's much slower than specifying the exact format of the dates. - 为什么不总是使用
infer_datetime_format = True? 不总是让 pandas 猜测时间格式有两个重要原因。 首先,pandas 并不总是能够找出正确的日期格式,特别是如果有人在数据输入方面发挥了创意。 第二个是它比指定日期的确切格式慢得多。
Select the day of the month
选择一月中的某一天
Now that we have a column of parsed dates, we can extract information like the day of the month that a landslide occurred.
现在我们有一列已解析的日期,我们可以提取信息,例如山体滑坡发生的月份中的哪一天。
# get the day of the month from the date_parsed column
day_of_month_landslides = landslides['date_parsed'].dt.day
day_of_month_landslides.head()0 2.0
1 22.0
2 6.0
3 14.0
4 15.0
Name: date_parsed, dtype: float64If we tried to get the same information from the original "date" column, we would get an error: AttributeError: Can only use .dt accessor with datetimelike values. This is because dt.day doesn't know how to deal with a column with the dtype "object". Even though our dataframe has dates in it, we have to parse them before we can interact with them in a useful way.
如果我们尝试从原始日期列获取相同的信息,我们会收到错误:AttributeError:只能使用具有类似日期时间值的 .dt 访问器。 这是因为 dt.day 不知道如何处理数据类型为object的列。 尽管我们的数据帧中有日期,但我们必须先解析它们,然后才能以有用的方式与它们交互。
Plot the day of the month to check the date parsing
绘制该月的日期来检查日期解析
One of the biggest dangers in parsing dates is mixing up the months and days. The to_datetime() function does have very helpful error messages, but it doesn't hurt to double-check that the days of the month we've extracted make sense.
解析日期的最大危险之一是混淆月份和日期。 to_datetime() 函数确实有非常有用的错误消息,但仔细检查我们提取的月份中的日期是否有意义也没有什么坏处。
To do this, let's plot a histogram of the days of the month. We expect it to have values between 1 and 31 and, since there's no reason to suppose the landslides are more common on some days of the month than others, a relatively even distribution. (With a dip on 31 because not all months have 31 days.) Let's see if that's the case:
为此,我们绘制该月各天的直方图。 我们预计它的值在 1 到 31 之间,并且由于没有理由认为山体滑坡在每月的某些日子比其他日子更常见,因此分布相对均匀。 (31 日有所下降,因为并非所有月份都有 31 天。)让我们看看情况是否如此:
# remove na's
day_of_month_landslides = day_of_month_landslides.dropna()
# plot the day of the month
sns.histplot(day_of_month_landslides, kde=False, bins=31)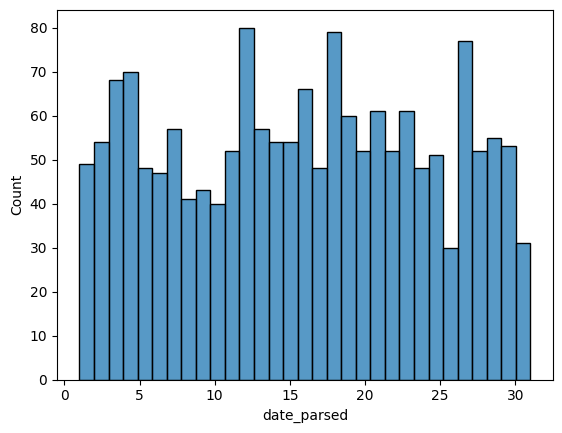
Yep, it looks like we did parse our dates correctly & this graph makes good sense to me.
是的,看起来我们确实正确解析了日期,并且这张图对我来说很有意义。
Your turn
到你了
Write code to parse the dates in a dataset of worldwide earthquakes.
编写代码以解析全球地震数据集中的日期。