This notebook is an exercise in the Intro to Deep Learning course. You can reference the tutorial at this link.
Introduction
介绍
In this exercise, you'll build a model to predict hotel cancellations with a binary classifier.
在本练习中,您将构建一个模型来使用二元分类器预测酒店取消情况。
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex6 import *First, load the Hotel Cancellations dataset.
首先,加载 Hotel Cancellations 数据集。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
hotel = pd.read_csv('../input/dl-course-data/hotel.csv')
X = hotel.copy()
y = X.pop('is_canceled')
X['arrival_date_month'] = \
X['arrival_date_month'].map(
{'January':1, 'February': 2, 'March':3,
'April':4, 'May':5, 'June':6, 'July':7,
'August':8, 'September':9, 'October':10,
'November':11, 'December':12}
)
features_num = [
"lead_time", "arrival_date_week_number",
"arrival_date_day_of_month", "stays_in_weekend_nights",
"stays_in_week_nights", "adults", "children", "babies",
"is_repeated_guest", "previous_cancellations",
"previous_bookings_not_canceled", "required_car_parking_spaces",
"total_of_special_requests", "adr",
]
features_cat = [
"hotel", "arrival_date_month", "meal",
"market_segment", "distribution_channel",
"reserved_room_type", "deposit_type", "customer_type",
]
transformer_num = make_pipeline(
SimpleImputer(strategy="constant"), # there are a few missing values
StandardScaler(),
)
transformer_cat = make_pipeline(
SimpleImputer(strategy="constant", fill_value="NA"),
OneHotEncoder(handle_unknown='ignore'),
)
preprocessor = make_column_transformer(
(transformer_num, features_num),
(transformer_cat, features_cat),
)
# stratify - make sure classes are evenlly represented across splits
X_train, X_valid, y_train, y_valid = \
train_test_split(X, y, stratify=y, train_size=0.75)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
input_shape = [X_train.shape[1]]1) Define Model
1) 定义模型
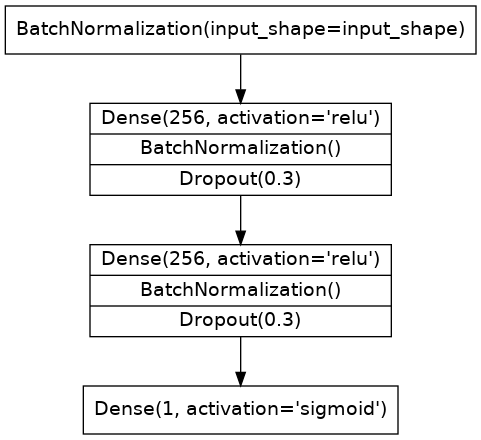
The model we'll use this time will have both batch normalization and dropout layers. To ease reading we've broken the diagram into blocks, but you can define it layer by layer as usual.
这次我们将使用的模型将同时具有批量归一化层和丢弃层。 为了便于阅读,我们将图表分成了多个块,但您可以像往常一样逐层定义它。
Define a model with an architecture given by this diagram:
使用下图给出的架构定义模型:
from tensorflow import keras
from tensorflow.keras import layers2024-04-28 03:01:32.392615: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-04-28 03:01:32.392671: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-04-28 03:01:32.394242: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registeredfrom tensorflow import keras
from tensorflow.keras import layers
# YOUR CODE HERE: define the model given in the diagram
# model = ____
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(1, activation='sigmoid')
]
)
# Check your answer
q_1.check()Correct
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
batch_normalization (Batch (None, 63) 252
Normalization)
dense (Dense) (None, 256) 16384
batch_normalization_1 (Bat (None, 256) 1024
chNormalization)
dropout (Dropout) (None, 256) 0
dense_1 (Dense) (None, 256) 65792
batch_normalization_2 (Bat (None, 256) 1024
chNormalization)
dropout_1 (Dropout) (None, 256) 0
dense_2 (Dense) (None, 1) 257
=================================================================
Total params: 84733 (330.99 KB)
Trainable params: 83583 (326.50 KB)
Non-trainable params: 1150 (4.49 KB)
_________________________________________________________________keras.utils.plot_model(model)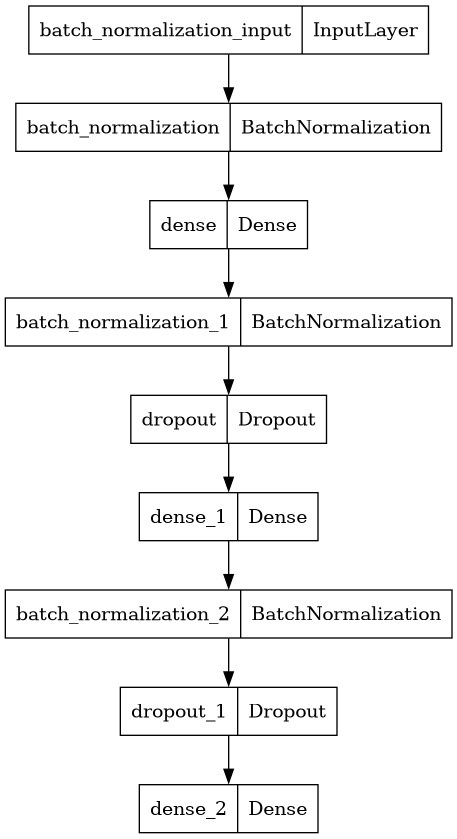
2) Add Optimizer, Loss, and Metric
2) 添加优化器、损失和指标
Now compile the model with the Adam optimizer and binary versions of the cross-entropy loss and accuracy metric.
现在使用 Adam 优化器和交叉熵损失和准确度度量的二进制版本来编译模型。
# YOUR CODE HERE
# ____
model.compile(
optimizer="Adam",
loss="binary_crossentropy",
metrics=["binary_accuracy"],
)
# Check your answer
q_2.check()Correct
# Lines below will give you a hint or solution code
#q_2.hint()
q_2.solution()Solution:
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
Finally, run this cell to train the model and view the learning curves. It may run for around 60 to 70 epochs, which could take a minute or two.
最后,运行此单元来训练模型并查看学习曲线。 它可能会运行大约 60 到 70 个 epoch,这可能需要一两分钟。
early_stopping = keras.callbacks.EarlyStopping(
patience=20,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=200,
callbacks=[early_stopping],
verbose=False,
)
history_df = pd.DataFrame(history.history)
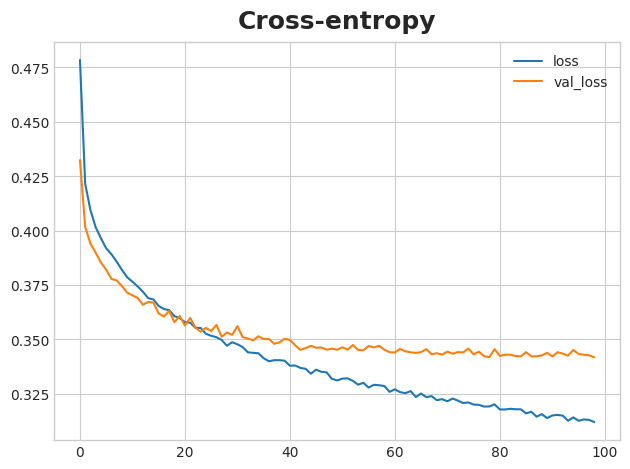
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")
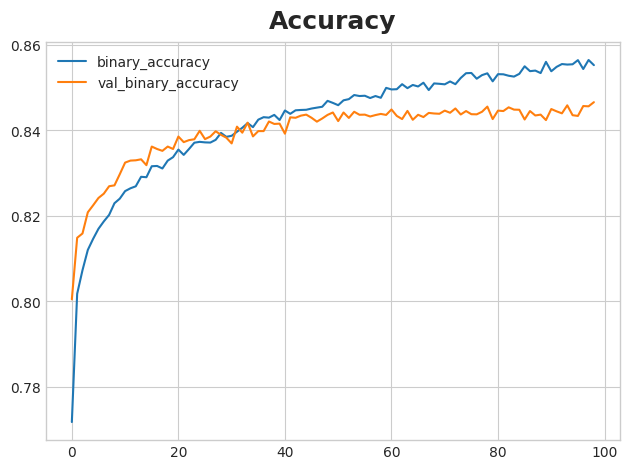
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1714273299.932021 3858 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
3) Train and Evaluate
3) 训练和评估
What do you think about the learning curves? Does it look like the model underfit or overfit? Was the cross-entropy loss a good stand-in for accuracy?
您对学习曲线有何看法? 模型看起来是否欠拟合或过拟合? 交叉熵损失是准确度的良好替代品吗?
# View the solution (Run this cell to receive credit!)
q_3.check()Correct:
Though we can see the training loss continuing to fall, the early stopping callback prevented any overfitting. Moreover, the accuracy rose at the same rate as the cross-entropy fell, so it appears that minimizing cross-entropy was a good stand-in. All in all, it looks like this training was a success!
尽管我们可以看到训练损失继续下降,但提前停止回调可以防止任何过度拟合。 此外,准确率的上升速度与交叉熵下降的速度相同,因此最小化交叉熵似乎是一个很好的替代方法。 总而言之,看来这次训练很成功!
Conclusion
结论
Congratulations! You've completed Kaggle's Introduction to Deep Learning course!
恭喜! 您已经完成了 Kaggle 的 深度学习简介 课程!
With your new skills you're ready to take on more advanced applications like computer vision and sentiment classification. What would you like to do next?
掌握了新技能后,您就可以采用更高级的应用程序,例如计算机视觉和情感分类。 你接下来想做什么?
Why not try one of our Getting Started competitions?
为什么不尝试一下我们的入门竞赛之一?
- Classify images with TPUs in Petals to the Metal
- 使用 Petals to the Metal 中的 TPU 对图像进行分类
- Create art with GANs in I'm Something of a Painter Myself
- 使用 GAN 创作 我的自画像
- Classify Tweets in Real or Not? NLP with Disaster Tweets
- 对推文进行分类 真实与否? 带有灾难推文的 NLP
- Detect contradiction and entailment in Contradictory, My Dear Watson
- 检测矛盾,我亲爱的沃森中的矛盾和蕴涵
Until next time, Kagglers!
下次再见,Kagglers!