Introduction
简介
There are many different ways of defining what we might look for in a fair machine learning (ML) model. For instance, say we're working with a model that approves (or denies) credit card applications. Is it:
定义公平机器学习 (ML) 模型中我们可能寻找的内容有很多不同的方法。例如,假设我们正在使用一个批准(或拒绝)信用卡申请的模型。它是:
- fair if the approval rate is equal across genders, or is it
- 如果批准率在性别之间相等,是否公平,或者
- better if gender is removed from the dataset and hidden from the model?
- 如果将性别从数据集中删除并从模型中隐藏,是否更好?
In this tutorial, we'll cover four criteria that we can use to decide if a model is fair. Then, you'll apply what you've learned in a hands-on exercise where you'll run code to train several models and analyze fairness of each. (As for every lesson in this course, no prior coding experience is required.)
在本教程中,我们将介绍四个标准,我们可以使用它们来决定模型是否公平。然后,您将在 [动手练习](https://www.kaggle.com/kernels/fork/15622664) 中应用您学到的知识,您将在其中运行代码来训练多个模型并分析每个模型的公平性。(与本课程的每一节课一样,不需要任何编码经验。)
Four fairness criteria
四个公平标准
These four fairness criteria are a useful starting point, but it's important to note that there are more ways of formalizing fairness, which you are encouraged to explore.
这四个公平标准是一个有用的起点,但需要注意的是,还有更多形式化公平的方法,我们鼓励您探索。
Assume we're working with a model that selects individuals to receive some outcome. For instance, the model could select people who should be approved for a loan, accepted to a university, or offered a job opportunity. (So, we don't consider models that perform tasks like facial recognition or text generation, among other things.)
假设我们正在使用一个模型来选择个人以获得某种结果。例如,该模型可以选择应该获得贷款批准、被大学录取或提供工作机会的人。(因此,我们不考虑执行面部识别或文本生成等任务的模型。)
1. Demographic parity / statistical parity
1. 人口均等/统计均等
Demographic parity says the model is fair if the composition of people who are selected by the model matches the group membership percentages of the applicants.
人口均等表示,如果模型选择的人员构成与申请人的群体成员百分比相匹配,则该模型是公平的。
A nonprofit is organizing an international conference, and 20,000 people have signed up to attend. The organizers write a ML model to select 100 attendees who could potentially give interesting talks at the conference. Since 50% of the attendees will be women (10,000 out of 20,000), they design the model so that 50% of the selected speaker candidates are women.
一家非营利组织正在组织一次国际会议,已有 20,000 人报名参加。组织者编写了一个 ML 模型来选择 100 名可能在会议上发表有趣演讲的与会者。由于 50% 的与会者将是女性(20,000 人中的 10,000 人),因此他们设计模型时,选定的演讲者候选人中有 50% 是女性。
2. Equal opportunity
2. 平等机会
Equal opportunity fairness ensures that the proportion of people who should be selected by the model ("positives") that are correctly selected by the model is the same for each group. We refer to this proportion as the true positive rate (TPR) or sensitivity of the model.
平等机会公平确保模型应选择的人员(“正向”)中正确选择的比例对于每个组都是相同的。我们将此比例称为模型的真阳性率 (TPR) 或敏感度。
A doctor uses a tool to identify patients in need of extra care, who could be at risk for developing serious medical conditions. (This tool is used only to supplement the doctor's practice, as a second opinion.) It is designed to have a high TPR that is equal for each demographic group.
医生使用一种工具来识别需要额外护理的患者,这些患者可能有患上严重疾病的风险。(此工具仅用于补充医生的实践,作为第二意见。)它旨在具有每个人口群体均等的高 TPR。
3. Equal accuracy
3. 同等准确度
Alternatively, we could check that the model has equal accuracy for each group. That is, the percentage of correct classifications (people who should be denied and are denied, and people who should be approved who are approved) should be the same for each group. If the model is 98% accurate for individuals in one group, it should be 98% accurate for other groups.
或者,我们可以检查模型对每个群体的同等准确度。也就是说,正确分类的百分比(应该被拒绝和被拒绝的人,以及应该被批准和被批准的人)对每个群体来说应该是相同的。如果模型对一个群体中的个人的准确率为 98%,那么对其他群体的准确率也应该是 98%。
A bank uses a model to approve people for a loan. The model is designed to be equally accurate for each demographic group: this way, the bank avoids approving people who should be rejected (which would be financially damaging for both the applicant and the bank) and avoid rejecting people who should be approved (which would be a failed opportunity for the applicant and reduce the bank's revenue).
一家银行使用模型来批准贷款。该模型旨在对每个人口统计群体都具有同等的准确性:这样,银行就可以避免批准应该被拒绝的人(这对申请人和银行来说都是经济损失),并避免拒绝应该被批准的人(这对申请人来说是一个失败的机会,并会减少银行的收入)。
4. Group unaware / "Fairness through unawareness"
4. 群体不知情/“通过不知情实现公平”
Group unaware fairness removes all group membership information from the dataset. For instance, we can remove gender data to try to make the model fair to different gender groups. Similarly, we can remove information about race or age.
群体不知情公平性会从数据集中删除所有群体成员信息。例如,我们可以删除性别数据,以尝试使模型对不同性别群体公平。同样,我们可以删除有关种族或年龄的信息。
One difficulty of applying this approach in practice is that one has to be careful to identify and remove proxies for the group membership data. For instance, in cities that are racially segregated, zip code is a strong proxy for race. That is, when the race data is removed, the zip code data should also be removed, or else the ML application may still be able to infer an individual's race from the data. Additionally, group unaware fairness is unlikely to be a good solution for historical bias.
在实践中应用这种方法的一个困难是,必须小心识别和删除群体成员数据的代理。例如,在种族隔离的城市中,邮政编码是种族的有力代理。也就是说,当删除种族数据时,邮政编码数据也应该被删除,否则 ML 应用程序可能仍然能够从数据中推断出个人的种族。此外,群体不知情的公平性不太可能成为解决历史偏见的好方法。
Example
示例
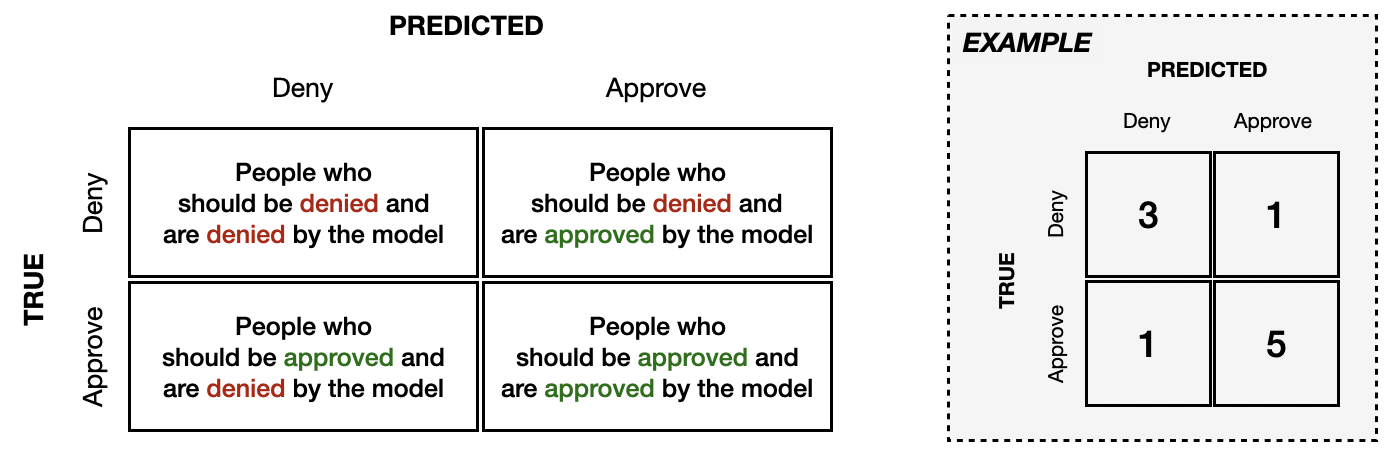
We'll work with a small example to illustrate the differences between the four different types of fairness. We'll use a confusion matrix, which is a common tool used to understand the performance of a ML model. This tool is depicted in the example below, which depicts a model with 80% accuracy (since 8/10 people were correctly classified) and has an 83% true positive rate (since 5/6 "positives" were correctly classified).
我们将通过一个小例子来说明四种不同类型的公平性之间的差异。我们将使用 混淆矩阵 ,这是一种用于了解 ML 模型性能的常用工具。下面的示例描述了此工具,该示例描述了一个准确率为 80% 的模型(因为 10 个人中有 8 个人被正确分类),真实阳性率为 83%(因为 6 个“阳性”中有 5 个人被正确分类)。
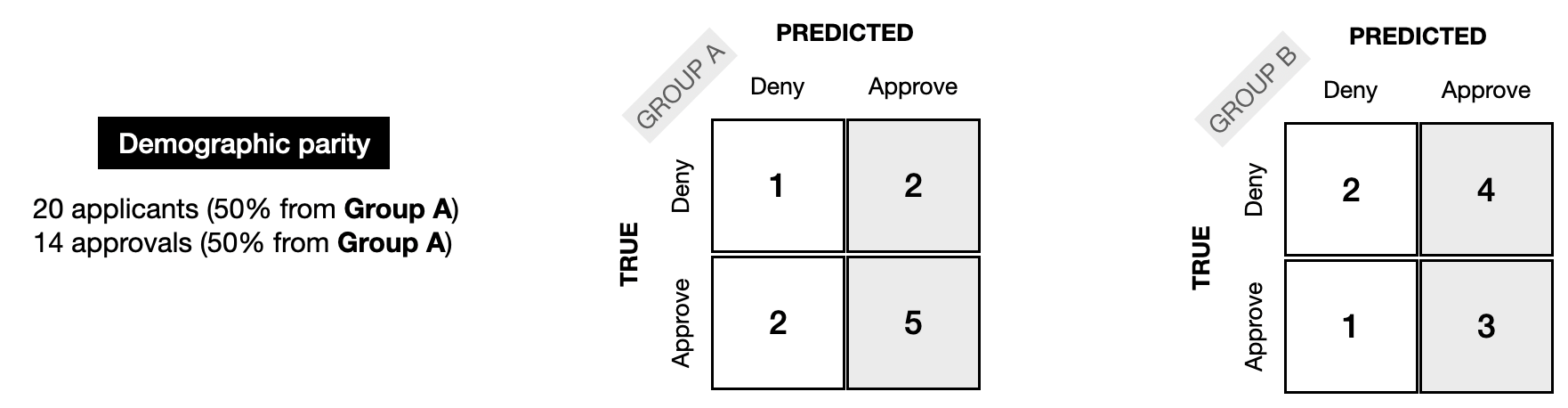
To understand how a model's performance varies across groups, we can construct a different confusion matrix for each group. In this small example, we'll assume that we have data from only 20 people, equally split between two groups (10 from Group A, and 10 from Group B).
为了了解模型在不同群体中的表现如何不同,我们可以为每个群体构建不同的混淆矩阵。在这个小例子中,我们假设只有 20 个人的数据,平均分为两组(10 人来自 A 组,10 人来自 B 组)。
The next image shows what the confusion matrices could look like, if the model satisfies demographic parity fairness. 10 people from each group (50% from Group A, and 50% from Group B) were considered by the model. 14 people, also equally split across groups (50% from Group A, and 50% from Group B) were approved by the model.
下图显示了如果模型满足人口统计学均等公平性,混淆矩阵可能是什么样子。模型考虑了每组中的 10 个人(50% 来自 A 组,50% 来自 B 组)。模型批准了 14 个人,他们也平均分为两组(50% 来自 A 组,50% 来自 B 组)。
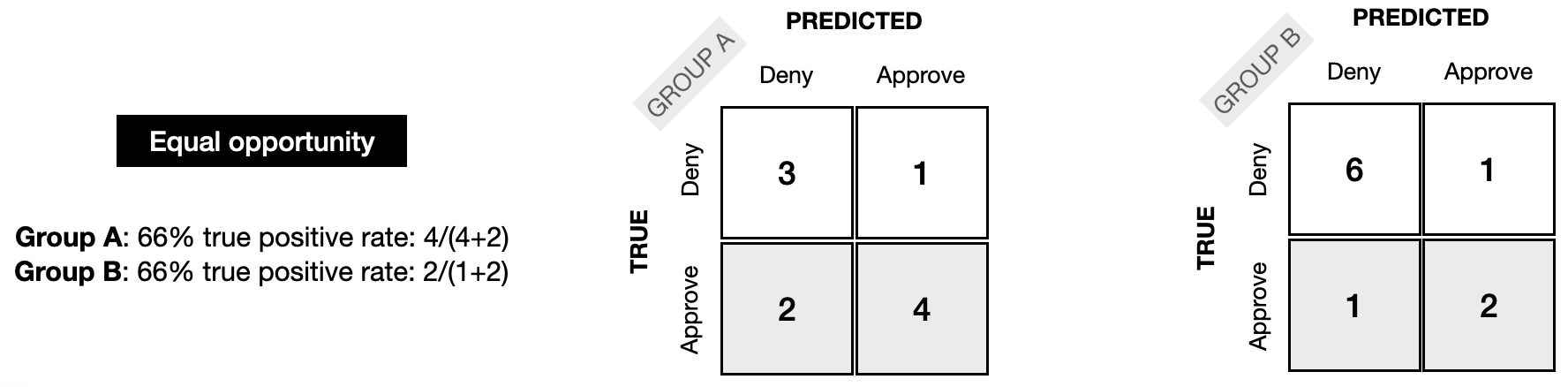
For equal opportunity fairness, the TPR for each group should be the same; in the example below, it is 66% in each case.
为了 平等机会 ,每个组的TPR应该相同;在下面的例子中,每种情况下的TPR都是66%。
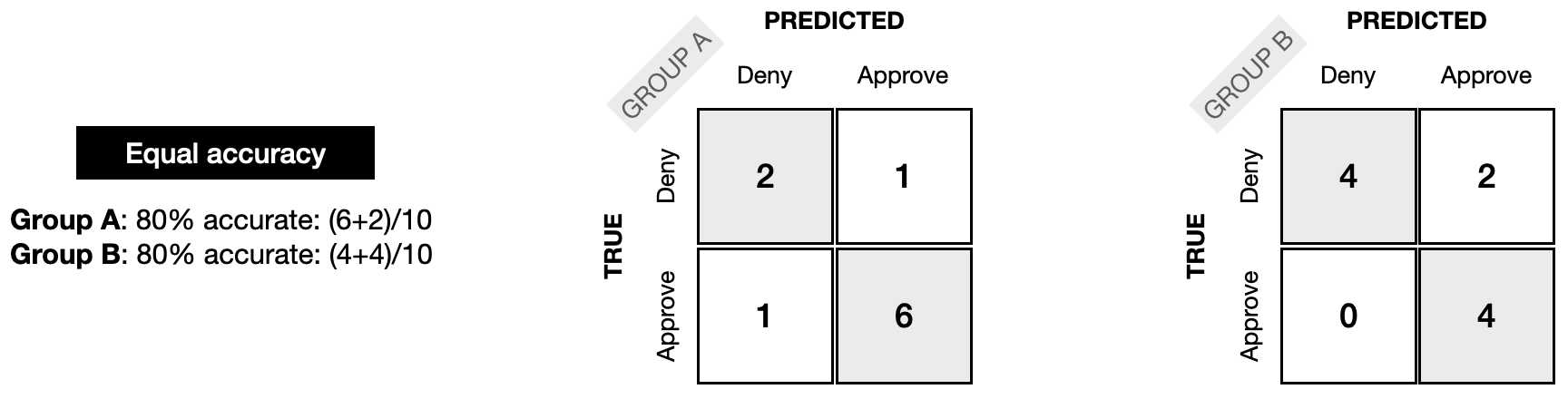
Next, we can see how the confusion matrices might look for equal accuracy fairness. For each group, the model was 80% accurate.
接下来,我们可以看到混淆矩阵如何实现同等准确率公平性。对于每个组,该模型的准确率为 80%。
Note that group unaware fairness cannot be detected from the confusion matrix, and is more concerned with removing group membership information from the dataset.
请注意,无法从混淆矩阵中检测到 群体不知情 公平性,而更关心从数据集中删除群体成员信息。
Take the time now to study these toy examples, and use it to build your intuition for the differences between the different types of fairness. How does the example change if Group A has double the number of applicants of Group B?
现在花点时间研究这些玩具示例,并用它来建立您对不同类型公平性之间差异的直觉。如果 A 组的申请人数是 B 组的两倍,示例会如何变化?
Also note that none of the examples satisfy more than one type of fairness. For instance, the demographic parity example does not satisfy equal accuracy or equal opportunity. Take the time to verify this now. In practice, it is not possible to optimize a model for more than one type of fairness: to read more about this, explore the Impossibility Theorem of Machine Fairness. So which fairness criterion should you select, if you can only satisfy one? As with most ethical questions, the correct answer is usually not straightforward, and picking a criterion should be a long conversation involving everyone on your team.
还请注意,没有一个示例满足多种类型的公平性。例如,人口均等示例不满足同等准确性或平等机会。现在花点时间验证这一点。在实践中,不可能针对多种类型的公平性优化模型:要了解有关此内容的更多信息,请探索 机器公平性的不可能定理。 那么,如果只能满足一个公平标准,那么应该选择哪个标准呢? 与大多数道德问题一样,正确答案通常并不简单,选择一个标准应该是一个涉及团队中每个人的长时间对话。
When working with a real project, the data will be much, much larger. In this case, confusion matrices are still a useful tool for analyzing model performance. One important thing to note, however, is that real-world models typically cannot be expected to satisfy any fairness definition perfectly. For instance, if "demographic parity" is chosen as the fairness metric, where the goal is for a model to select 50% men, it may be the case that the final model ultimately selects some percentage close to, but not exactly 50% (like 48% or 53%).
在处理实际项目时,数据会大得多。在这种情况下,混淆矩阵仍然是分析模型性能的有用工具。然而,需要注意的一件重要事情是,现实世界的模型通常不能完美地满足任何公平定义。例如,如果选择“人口平等”作为公平指标,目标是让模型选择 50% 的男性,那么最终模型可能会选择接近但不完全是 50% 的百分比(例如 48% 或 53%)。
Learn more
了解更多
- Explore different types of fairness with an interactive tool.
- 使用 交互式工具 探索不同类型的公平性。
- You can read more about equal opportunity in this blog post.
- 您可以在 此博客文章 中阅读有关平等机会的更多信息。
- Analyze ML fairness with this walkthrough of the What-If Tool, created by the People and AI Research (PAIR) team at Google. This tool allows you to quickly amend an ML model, once you've picked the fairness criterion that is best for your use case.
- 使用 Google 人员和 AI 研究 (PAIR) 团队创建的 What-If 工具的 此演练 分析 ML 公平性。一旦您选择了最适合您用例的公平性标准,此工具可让您快速修改 ML 模型。
Your turn
轮到你了
Continue to the exercise to run code to train models and determine fairness.
继续练习 运行代码 来训练模型并确定公平性。