Explainable AI, also known as XAI, is a field of machine learning(ML) consisting of techniques that aim to give a better understanding of model behavior by providing explanations as to how a model made a prediction. Knowing how a model behaves, and how it is influenced by its training dataset, gives anyone who builds or uses ML powerful new abilities to improve models, build confidence in their predictions, and understand when things go awry. Explainable AI techniques are especially useful because they do not rely on a particular model—once you know an Explainable AI method, you can use it in many scenarios. This book is designed to give you the ability to understand how Explainable AI techniques work so you can build an intuition for when to use one approach over another, how to apply these techniques, and how to evaluate these explanations so you understand their benefits and limitations, as well as communicate them to your stakeholders. Explanations can be very powerful and are easily able to convey a new understanding of why a model makes a certain prediction, as Figure 1-1 demonstrates, but they also require skill and nuance to use correctly.
可解释人工智能(Explainable AI,简称 XAI)是机器学习 (ML) 的一个分支,它包含一系列旨在通过解释模型如何做出预测来更好地理解模型行为的技术。了解模型的行为方式及其受训练数据集的影响,能够为任何构建或使用机器学习的人员提供强大的新能力,从而改进模型、增强预测的可靠性,并了解何时出现问题。可解释人工智能技术尤其有用,因为它们不依赖于特定的模型——一旦掌握了某种可解释人工智能方法,就可以将其应用于多种场景。本书旨在帮助您理解可解释人工智能技术的工作原理,从而建立一种直觉,判断何时使用哪种方法,如何应用这些技术,以及如何评估这些解释,从而了解它们的优势和局限性,并将其传达给您的利益相关者。解释可以非常有效,并且能够轻松地传达对模型做出某个预测原因的新理解,如图 1-1 所示,但它们也需要技巧和细微差别才能正确使用。

Figure 1-1. An explanation using Blur-IG (described in Chapter 4) that shows what pixels influenced an image classification model to predict that the animal on the cover of this book is a parrot.
图 1-1。使用 Blur-IG 的解释(详见第 4 章)展示了哪些像素影响了图像分类模型,使其能够预测本书封面上的动物是鹦鹉。
Why Explainable AI
为什么需要可解释人工智能
In 2018, data scientists built a machine learning (ML) model to identify diseases from chest X-rays. The goal was to allow radiologists to be able to review more X-rays per day with the help of AI. In testing, the model achieved very high, but not perfect, accuracy with a validation dataset. There was just one problem: the model performed terribly in real-world settings. For months, the researchers tried to find why there was a discrepancy. The model had been trained on the same type of chest X-rays shown in Figure 1-2, and the X-rays had any identifying information removed. Even with new data, they kept encountering the same problem: fantastic performance in training, only to be followed by terrible results in a hospital setting. Why was this happening?
2018 年,数据科学家构建了一个机器学习 (ML) 模型,用于从胸部 X 光片中识别疾病。其目标是让放射科医生借助人工智能每天能够查看更多 X 光片。在测试中,该模型使用验证数据集实现了非常高但并非完美的准确率。问题在于:该模型在实际应用中表现糟糕。几个月来,研究人员一直在努力寻找造成这种差异的原因。该模型使用与图 1-2所示相同的胸部 X 光片进行训练,并且 X 光片上的所有识别信息均已去除。即使使用新数据,他们仍然遇到同样的问题:训练时表现极佳,但在医院环境中却结果糟糕。这是为什么呢?
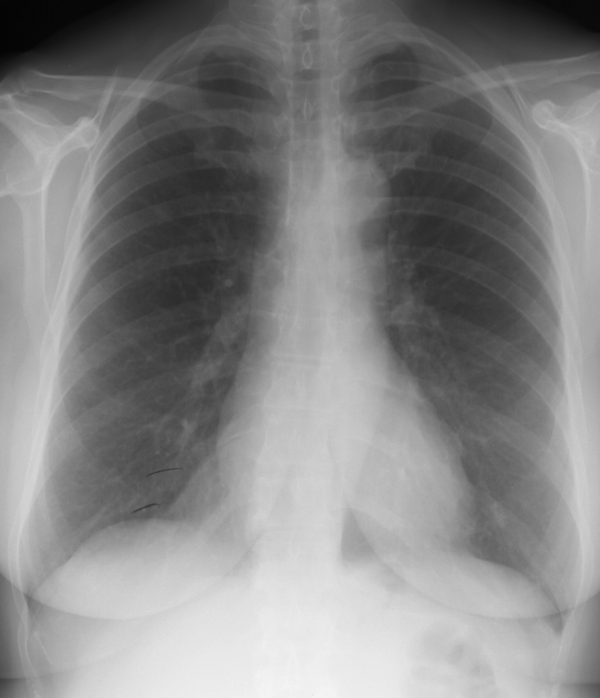
Figure 1-2. An example of the chest X-rays used to train the model to recognize diseases. Can you identify what led the model astray?1
图 1-2。用于训练模型识别疾病的胸部 X 光片示例。你能找出模型出错的原因吗?1
A few years later, another research group, this time eye doctors in the UK, embarked on a mission to train a model to identify diseases from retinal scans of a patient’s eye. After they had trained the model, they encountered an equally surprising, but very different result. While the model was very good at identifying diseases, it was uncannily accurate at also predicting the sex of the patient.
几年后,另一个研究小组(这次是英国的眼科医生)开始了一项任务,旨在训练一个模型,使其能够根据患者眼部的视网膜扫描图像识别疾病(参见图 1-3)。在训练完模型后,他们得到了一个同样令人惊讶但却截然不同的结果。虽然该模型在识别疾病方面表现出色,但它在预测患者性别方面也达到了惊人的准确度。

Figure 1-3. An example of retinal fundus images, which show the interior of an eye and can be used to predict diseases such as diabetes.
图 1-3. 视网膜眼底图像示例,该图像显示眼睛内部结构,可用于预测糖尿病等疾病。
There were two fascinating aspects of this prediction. First, the
doctors had not designed the ML to predict the patient’s sex; this was
an inadvertent output of their model architecture and ML experiments.
Second, if these predictions were accurate, this correlation between the
interior of our eyes and our sex was a completely new discovery in
ophthalmology. Had the ML made a brand-new discovery, or was something
flawed in the model or dataset such that information about a patient’s
sex was leaking into the model’s inference?
这项预测有两个引人入胜之处。首先,医生们最初设计机器学习模型时并非为了预测患者的性别;这只是他们的模型架构和机器学习实验意外产生的输出结果。其次,如果这些预测准确无误,那么我们眼睛内部特征与性别之间的这种关联将是眼科学领域的一项全新发现。究竟是机器学习模型做出了一项全新的发现,还是模型或数据集存在缺陷,导致患者性别信息泄露并影响了模型的推断结果?
In both cases of the chest X-ray and the retinal images, the opaque nature of machine learning had turned on its users. Modern machine learning has succeeded precisely because computers could teach themselves how to perform many tasks using an approach of consuming vast amounts of information to iteratively tune a large number of parameters. However, the large quantities of data involved in training these models have made it pragmatically impossible for a human to directly examine and understand the behavior of a model or how a dataset influenced the model. While any machine learning model can be inspected by looking at individual weights or specific data samples used to train the model, this examination rarely yields useful insights.
在胸部X光片和视网膜图像这两种情况下,机器学习的“黑箱”特性都给用户带来了困扰。现代机器学习之所以取得成功,正是因为计算机能够通过消耗海量信息并迭代调整大量参数的方式,自学如何执行许多任务。然而,训练这些模型所需的大量数据使得人类实际上无法直接检查和理解模型的行为,也无法理解数据集如何影响模型。虽然可以通过查看单个权重或用于训练模型的特定数据样本来检查任何机器学习模型,但这种检查很少能提供有用的见解。
In the first example we gave, the X-ray model that performed well in testing and was useless in practice, the data scientists who built the model did all the right things. They removed text labels from the images to prevent the model from learning how to read and predict a disease based on ancillary information. They properly divided their training, testing, and validation datasets, and used a reasonable model architecture that built upon an existing process (radiologists examining X-rays) that already proved it was feasible to identify diseases from a patient’s X-ray. And yet, even with these precautions and expertise, their model was still a failure. The eye doctors who built an ML model for classifying eye disease were world-class experts in their own field who understood ophthalmology but were not machine learning experts. If their discovery that our eyes, which have been exhaustively studied for hundreds of years, still held secrets about human biology, how could they perform a rigorous analysis of the machine learning model to be certain their discovery was real? Fortunately, Explainable AI provides new ways for ML practitioners, stakeholders, and end users to answer these types of questions.
在我们给出的第一个例子中,那个在测试中表现良好但在实际应用中却毫无用处的X射线模型,构建该模型的数据科学家们做了所有正确的事情。他们从图像中移除了文本标签,以防止模型学习如何根据辅助信息进行阅读并预测疾病。他们正确地划分了训练集、测试集和验证集,并使用了合理的模型架构,该架构基于现有的流程(放射科医生检查X射线片)构建,而该流程已经证明从患者的X射线片中识别疾病是可行的。然而,即使采取了这些预防措施并拥有丰富的专业知识,他们的模型仍然失败了。那些构建用于分类眼部疾病的机器学习模型的眼科医生是各自领域的顶尖专家,他们精通眼科学,但并非机器学习专家。如果他们发现我们的人眼(尽管已经被深入研究了数百年)仍然蕴藏着关于人类生物学的秘密,那么他们如何才能对机器学习模型进行严格的分析,以确保他们的发现是真实的呢?幸运的是,可解释人工智能为机器学习从业者、利益相关者和最终用户提供了新的方法来回答这些类型的问题。
What Is Explainable AI?
什么是可解释人工智能?
At Explainable AI’s core is the creation of explanations, or to create explainability for a model. Explainability is the concept that a model’s actions can be described in terms that are comprehensible to whoever is consuming the predictions of the ML model. This explainability serves a variety of purposes, from improving model quality to building confidence, and even providing a pathway for remediation when a prediction is not one you were expecting. As we have built increasingly complex models, we have discovered that a high-performing model is not sufficient to be acceptable in the real world. It is necessary that a prediction also has a reasonable explanation and, overall, the model behaves in the way its creators intended.
可解释人工智能的核心在于创建解释,或者说为模型赋予可解释性。可解释性是指模型的行为可以用机器学习模型预测结果的使用者能够理解的术语来描述。这种可解释性具有多种用途,从提高模型质量到增强信任,甚至在预测结果与预期不符时提供补救途径。随着我们构建的模型越来越复杂,我们发现高性能模型不足以在现实世界中被接受。预测结果必须具有合理的解释,并且总体而言,模型的行为方式必须符合其创建者的预期。
Imagine an AI who is your coworker on a project. Regardless of how well your AI coworker performs any task you give them, it would be incredibly frustrating if your entire collaboration with the AI consisted of them vanishing after taking on a task, suddenly reappearing with the finished work, and then vanishing again as soon as they delivered it to you. If their work was superb, perhaps you would be accepting of this transactional relationship, but the quality of your AI coworker’s results can vary considerably. Unfortunately, the AI never answers your questions or even tells you how they arrived at the result.
想象一下,一个人工智能是你的项目同事。无论你的AI同事完成你交给它的任务有多出色,如果你们之间的合作模式是这样的:它接受任务后就消失不见,突然又带着完成的工作出现,然后一交给你就再次消失,这种合作方式会让人感到非常沮丧。如果它的工作质量非常出色,或许你可以接受这种单向的合作关系,但你的AI同事的工作成果质量可能会参差不齐。更糟糕的是,这个AI从不回答你的问题,甚至不告诉你它是如何得出结果的。
As AI becomes our coworkers, colleagues, and more responsible for decisions affecting many aspects of our life, the feedback is clear that having AI as a silent partner is unsatisfying. We want (and in the future, will have a right) to expect we can have a two-way dialogue with our machine learning model to understand why it performed the way it did. Explainable AI represents the beginning of this dialogue, by opening up a new way for an ML system to convey how it works instead of simply delivering the results of a task.
随着人工智能成为我们的同事、伙伴,并越来越多地负责影响我们生活方方面面的决策,人们普遍认为,让人工智能充当一个沉默的伙伴是令人不满意的。我们希望(而且将来我们有权)能够与机器学习模型进行双向对话,以了解它做出特定决策的原因。可解释人工智能正是这种对话的开端,它开辟了一种新的途径,让机器学习系统能够解释其工作原理,而不仅仅是给出任务结果。
Who Needs Explainability?
谁需要可解释性?
To understand how explainability aided the researchers in our two examples of where conventional ML workflows failed to address the issues encountered, it is also necessary to talk about who uses explainability and why. In our work on Explainable AI for Google Cloud, we have engaged with many companies, data scientists, ML engineers, and business executives who have sought to understand how a model works and why. From these interactions, we have found that there are three distinct groups of people who are seeking explanations, and each group has distinct but overlapping motivations and needs. Throughout the book, we will refer to all of these groups as explainability consumers because they are the recipient of an explanation and act upon that explanation. Our consumers can be divided into three roles:
为了理解可解释性如何帮助研究人员解决我们在两个示例中遇到的问题(这些示例表明传统机器学习工作流程无法解决这些问题),我们还需要探讨谁在使用可解释性以及原因。在我们为 Google Cloud 开发可解释人工智能的工作中,我们与许多公司、数据科学家、机器学习工程师和企业高管进行了交流,他们都希望了解模型的工作原理和原因。通过这些互动,我们发现有三类不同的人群正在寻求解释,而且每一类人群都有独特但又相互重叠的动机和需求。在本书中,我们将所有这些群体统称为“可解释性使用者”,因为他们是解释的接收者,并会根据解释采取行动。我们的使用者可以分为以下三类角色:
Practitioners : Data scientists and engineers who are familiar with machine learning
从业人员:熟悉机器学习的数据科学家和工程师
Observers : Business stakeholders and regulators who have some familiarity with machine learning but are primarily concerned with the function and overall performance of the ML system
观察者:对机器学习有所了解但主要关注机器学习系统的功能和整体性能的商业利益相关者和监管机构。
End users : Domain experts and affected users who may have little-to-no knowledge of ML and are also recipients of the ML system’s output
最终用户:领域专家和受影响的用户,他们可能对机器学习知之甚少,但却是机器学习系统输出结果的接收者。
A person can simultaneously assume multiple roles as an ML consumer. For example, a common pattern we see is that data scientists start as ML practitioners, but over time build up an understanding of the field they are serving and eventually become domain experts themselves, allowing them to act as an end user in evaluating a prediction and explanation.
一个人可以同时扮演机器学习消费者的多种角色。例如,我们常见的一种模式是,数据科学家最初是机器学习实践者,但随着时间的推移,他们对所服务的领域有了更深入的了解,最终成为该领域的专家,从而能够以最终用户的身份评估预测结果和解释。
In our chest X-ray case study, the ML practitioners built the model but did not have domain expertise in radiology. They understood how the ML system works and how it was trained but did not have a deep understanding of the practice of radiology. In contrast, in the retina images case study, the ophthalmologist researchers with domain expertise who built the model found the ML had discovered a new correlation between the appearance of the interior of our eyes and our sex, but they lacked the expertise of ML practitioners to be confident the model was functioning correctly.
在我们的胸部X光片案例研究中,机器学习工程师构建了模型,但他们缺乏放射学领域的专业知识。他们了解机器学习系统的工作原理和训练过程,但对放射学实践没有深入的理解。相比之下,在视网膜图像案例研究中,拥有领域专业知识的眼科医生研究人员构建了模型,他们发现机器学习模型揭示了眼睛内部外观与性别之间的新关联,但他们缺乏机器学习工程师的专业知识,无法确信模型运行正确。
Each group had very different needs for explaining why the model acted the way it did. The ML practitioners were looking for precise and accurate explanations that could expose the step at which the ML had failed. The ophthalmologists, as end users, were looking for an explanation that was more conceptual and would help them construct a hypothesis for why the classification occurred and also allow them to build trust in the model’s predictions.
两组人员对模型行为的解释需求截然不同。机器学习工程师需要精确详细的解释,以便找出机器学习模型出错的具体步骤。而作为最终用户的眼科医生则需要更概念化的解释,帮助他们构建关于分类原因的假设,并增强他们对模型预测结果的信任。
Challenges in Explainability
可解释性方面的挑战
How we use Explainable AI for a model depends on the goals of those consuming the explanations. Suppose, based on just the information we have given about these individuals, their ML, and their challenges, we asked you to implement an Explainable AI technique that will generate explanations of how the model arrived at its predictions. You toil away and implement a way to generate what you think are good explanations for these ML models by using Integrated Gradients (Chapter 4) to highlight pixels that were influential in the prediction. You excitedly deliver a set of predictions with relevant pixels highlighted in the image, but rather than being celebrated as the person who saved the day, you immediately get questions like:
我们如何使用可解释人工智能(Explainable AI)来解释模型,取决于解释的使用者的目标。假设,仅基于我们提供的关于这些个体、他们的机器学习模型以及他们面临的挑战的信息,我们要求您实施一种可解释人工智能技术,以生成模型如何得出预测结果的解释。您辛勤工作,并使用集成梯度(第四章)来突出显示对预测有影响的像素,从而实现了一种生成您认为对这些机器学习模型而言是良好解释的方法。您兴奋地交付了一组预测结果,并在图像中突出显示了相关的像素,但您非但没有被誉为救世主,反而立即收到了这样的问题:
- How do I know this explanation is accurate?
- 我怎么知道这个解释是准确的?
- What does it mean that one pixel is highlighted more than another?
- 一个像素比另一个像素更突出显示是什么意思?
- What happens if we remove these pixels?
- 如果我们移除这些像素会发生什么?
- Why did it highlight these pixels instead of what we think is important over here?
- 为什么它突出显示的是这些像素,而不是我们认为重要的其他部分?
- Could you do this for the entire dataset?
- 你能对整个数据集都这样做吗?
In trying to answer one question, you inadvertently caused five more questions to be asked! Each of these questions are valid and worth asking, but may not help your audience in their original goal to understand the model’s behavior. However, as explainability is a relatively new field in AI, it is likely you will encounter these questions, for which there are no easy answers. In Explainable AI, there are several outstanding challenges:
在试图回答一个问题的过程中,您无意中又引出了五个问题!这些问题都有效且值得探讨,但可能无助于您的受众理解模型的行为,也无法帮助他们实现最初的目标。然而,由于可解释人工智能(Explainable AI,简称 XAI)是一个相对较新的领域,您很可能会遇到这些问题,而这些问题目前还没有简单的答案。在可解释人工智能领域,存在一些突出的挑战:
- Demonstrating the semantic correctness of explanation techniques above and beyond the theoretical soundness of the underlying mathematics
- 证明上述解释技术的语义正确性,而不仅仅是底层数学理论的正确性
- Combining different explanation techniques in an easy and safe way that enhances understanding rather than generating more confusion
- 以一种简单安全的方式结合不同的解释技术,从而增强理解而不是造成更多困惑
- Building tools that allow consumers to easily explore, probe, and build richer explanations
- 构建工具,使使用者能够轻松探索、探究和构建更丰富的解释
- Generating explanations that are computationally efficient
- 生成计算效率高的解释
- Building a strong framework for determining the robustness of explanation techniques
- 构建一个强大的框架来确定解释技术的鲁棒性
Promising research is being conducted in all of these areas; however, none have yet achieved acceptance within the explainability community to the level that we would feel confident in recommending them. Additionally, many of these questions have led to research papers that investigate how explanation techniques may be fundamentally broken. This is a very promising line of research but, as we discuss in Chapter 7, may be better viewed as research that probes how susceptible XAI techniques are to adversarial attacks or are brittle and unable to generate good explanations outside of their original design parameters. Many of these questions are sufficiently interesting that we recommend caution when using explanations for high-risk or safety-critical AIs.
所有这些领域都在进行着富有前景的研究;然而,目前还没有任何研究成果在可解释性社区获得广泛认可,达到我们可以自信地推荐它们的程度。此外,许多这些问题都促使研究人员撰写论文,探讨解释技术可能存在的根本缺陷。这是一个非常有前景的研究方向,但正如我们在第 7 章中所讨论的,这可能更应该被视为研究 XAI 技术对对抗性攻击的脆弱性,或者它们在超出其原始设计参数范围时无法生成良好解释的能力。由于其中许多问题都非常重要,我们建议在将解释用于高风险或安全关键型人工智能系统时要谨慎。
Evaluating Explainability
评估可解释性
Let’s return to our two case studies to see how they fared after using explainability. For the chest X-ray, the ML practitioners had been unable to discover why the model performed very well in training and testing, but poorly in the real world. One of the researchers used an explainability technique, Integrated Gradients, to highlight pixels in the chest X-ray that were influential in the prediction. Integrated Gradients (covered in more depth in Chapter 4) evaluates the prediction by starting with a baseline image—for example, one that is all black, and progressively generating new images with pixels that are closer to the original input. These intermediate images are then fed to the model to create new predictions. The predictions are consolidated into a new version of the input image where pixels that were influential to the model’s original prediction are shown in a new color, which is known as a saliency map. The intensity of the coloring reflects how strong the pixels influenced the model. At first glance, the explanations were as baffling as the original problem.
让我们回到之前的两个案例研究,看看在使用可解释性技术后,它们的情况如何。对于胸部X光片案例,机器学习从业者一直无法弄清楚为什么模型在训练和测试阶段表现良好,但在实际应用中却表现不佳。其中一位研究人员使用了一种可解释性技术——集成梯度(Integrated Gradients),来突出显示胸部X光片中对预测结果有影响的像素。集成梯度(在第4章中有更详细的介绍)通过从基线图像(例如,全黑图像)开始,逐步生成像素越来越接近原始输入图像的新图像来评估预测结果。然后,这些中间图像被输入到模型中以生成新的预测结果。这些预测结果被整合到原始输入图像的一个新版本中,其中对模型原始预测结果有影响的像素会以新的颜色显示,这被称为显著性图。颜色的强度反映了这些像素对模型的影响程度。乍一看,这些解释和最初的问题一样令人费解。

Figure 1-4. The explanation for which pixels, highlighted in red, the model thought indicated a disease in the chest X-ray. For readability, the area of the image containing the most attributed pixels is outlined by the blue box. (Print readers can see the color image at https://oreil.ly/xai-fig-1-4.)
图 1-4。图中用红色突出显示的像素是模型认为指示胸部 X 光片中存在疾病的区域。为了便于阅读,包含最多相关像素的区域已用蓝色框线标出。
An example of one of these images is shown in Figure 1-4, and it may appear that no pixels were used in the prediction. However, if you look at the lower left of this image, you will notice a smattering of red pixels among the black and white of the chest X-ray. These appear to be quite random as well. It’s not until one closely looks at this area of the image that you can barely perceive what appear to be scratch marks on the X-ray. However, these are not random scratches, but the pen marks of a radiologist who had drawn where the disease was in the X-ray, as we can see in Figure 1-5. The model then became trained to associate pen markings with a disease being present. However, in the real-world setting, the X-rays had no pen markings on them because the raw X-ray images were fed to the model before being shown to a radiologist who could have marked them up.
图 1-4 展示了其中一张图像的示例,乍一看,似乎没有使用任何像素进行预测。然而,如果您仔细观察图像的左下角,会发现胸部 X 光片黑白图像中散布着一些红色像素。这些像素看起来也相当随机。只有仔细观察图像的这一区域,才能勉强辨认出 X 光片上的一些划痕。然而,这些并非随机划痕,而是放射科医生用笔标记疾病位置的痕迹,如图 1-5 所示。模型因此被训练成将笔迹标记与疾病的存在联系起来。然而,在实际应用中,X 光片上并没有这些笔迹标记,因为原始 X 光图像是在显示给放射科医生进行标记之前就被输入到模型中的。

Figure 1-5. Example of the pen markings in a chest X-ray within the training dataset.
图 1-5. 训练数据集中胸部 X 光片上的笔迹标记示例。
Once the researchers figured out the cause of their performance mismatch, that pen markings had leaked information to the model about whether to classify the X-ray as showing disease or not, they could build a new dataset that had not been annotated by radiologists. The model’s subsequent performance was not noticeably worse in training than the original model and performed better in the real-world setting.
研究人员弄清楚了性能不匹配的原因——笔迹标记泄露了信息,让模型能够判断X光片是否显示疾病——之后,他们构建了一个未经放射科医生标注的新数据集。模型在新数据集上的训练性能与原始模型相比没有明显下降,并且在实际应用场景中表现更好。
Let’s turn to the retina study. How did ophthalmologists use Explainable AI to become confident that their ML model could predict the sex of a patient based on their retinal fundus images? The researchers used a technique known as XRAI (discussed in Chapter 4; no relation to X-rays) to highlight regions of the eye image that influenced the model’s prediction. The explanations, seen in Figure 1-6, showed that the model was attentive to the optic nerve (the large blob to one side of the retina) and the blood vessels radiating out from the optic nerve.
接下来我们来看视网膜研究。眼科医生是如何利用可解释人工智能来确信他们的机器学习模型能够根据患者的视网膜眼底图像预测患者性别的呢?研究人员使用了一种名为 XRAI 的技术(详见第 4 章;与X射线无关),来突出显示影响模型预测的眼部图像区域。如图1-6所示,解释结果表明,模型关注的是视神经(视网膜一侧的大块区域)以及从视神经放射状延伸出来的血管。
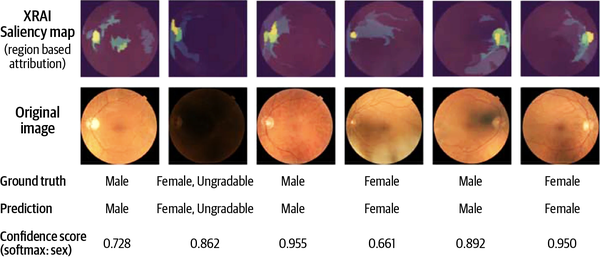
Figure 1-6. XRAI used to highlight what pixels influenced the model’s prediction of a patient’s sex based on a photograph of the interior of their eye, from an article by Korot et al.
图 1-6 XRAI 技术用于突出显示哪些像素影响了模型根据患者眼部内部照片预测其性别的结果,该图摘自 Korot 等人发表的一篇文章。
By seeing that the model had become influenced by such specific parts of the eye’s anatomy, the researchers were convinced that the model was indeed making correct predictions. This work was also sufficient to convince the broader scientific community, as the results were eventually published as a paper in Scientific Reports.
研究人员发现该模型受到了眼睛特定解剖结构的影响,因此确信该模型能够做出正确的预测。这项研究成果也足以说服更广泛的科学界,最终以论文形式发表在《科学报告》(Scientific Reports)杂志上。
How Has Explainability Been Used?
可解释性人工智能的应用案例
The two examples we gave focused on explainability for image models in medical research and healthcare. You may often find that examples of explainability involve an image model because it is easier to understand the explanation for an image than the relative importance of different features in structured data or the mapping of influential tokens in a language model. In this section, we look at some other case studies of how Explainable AI has been used beyond image models.
我们前面给出的两个例子都侧重于医学研究和医疗保健领域图像模型的可解释性。您可能会发现,可解释性人工智能的示例通常涉及图像模型,因为理解图像的解释比理解结构化数据中不同特征的相对重要性或语言模型中有影响力的标记的映射更容易。在本节中,我们将探讨一些其他案例研究,了解可解释性人工智能在图像模型之外的应用。
How LinkedIn Uses Explainable AI
LinkedIn 如何使用可解释性人工智能
Since 2018, LinkedIn has successfully used Explainable AI across many areas of its business, from recruiting to sales, and ML engineering. For example, in 2022 LinkedIn revealed that Explainable AI was key to the adoption of a ranking and recommendation ML system used by their sales team to prioritize which customers to engage with based on the ML’s prediction of how likely it was that the customer would stop using existing products (also known as churn), or their potential to be sold new ones (known as upselling). While the ML performed well, the AI team at LinkedIn quickly discovered that the system was not going to be used by their sales teams unless it included a rationale for the predictions:
自 2018 年以来,LinkedIn 已在其业务的许多领域成功应用了可解释性人工智能,包括招聘、销售和机器学习工程。例如,2022 年,LinkedIn 透露,可解释性人工智能是其销售团队采用排名和推荐机器学习系统的关键。该系统根据机器学习模型预测客户停止使用现有产品的可能性(也称为“客户流失”)或购买新产品的潜力(也称为“追加销售”)来确定与哪些客户进行互动。虽然机器学习模型的性能良好,但 LinkedIn 的人工智能团队很快发现,除非该系统包含对预测结果的解释,否则销售团队不会使用它:
While this ML-based approach was very useful, we found from focus > group studies that ML-based model scores alone weren’t the most > helpful tool for our sales representatives. Rather, they wanted to > understand the underlying reasons behind the scores—such as why the > model score was higher for Customer A but lower for > Customer B—and they also wanted to > be able to double-check the reasoning with their domain > knowledge.^ data-type="noteref">3^
虽然这种基于机器学习的方法非常有用,但我们通过焦点小组研究发现,仅凭基于机器学习的模型分数对我们的销售代表来说并不是最有用的工具。相反,他们想要了解分数背后的根本原因——例如,为什么客户 A 的模型分数更高,而客户 B 的模型分数更低——他们还希望能够利用他们的领域知识来验证这些推理。
Similar to our chest X-ray example, LinkedIn has also used Explainable AI to improve the quality of their ML models. In this case, their ML team productionized the use of explainability across many models by building a tool that allows LinkedIn data scientists and engineers to perturb features (see Chapter 3) to generate alternative scenarios for predictions to understand how a model may behave with a slightly different set of inputs.^4^
与我们之前的胸部 X 光片示例类似,LinkedIn 也使用可解释性人工智能来提高其机器学习模型的质量。在这种情况下,他们的机器学习团队通过构建一个工具,将可解释性应用于多个模型,该工具允许 LinkedIn 的数据科学家和工程师扰动特征(参见第 3 章),从而生成不同的预测场景,以了解模型在输入略有不同的情况下会如何表现。
LinkedIn has gone a step further to create an app, CrystalCandle,^5^ that translates raw explanations for structured data, which are often just numbers, into narrative explanations (we discuss narrative explanations further in Chapter 7). An example of the narrative explanations they have built are shown in Table 1-1.
LinkedIn 更进一步,创建了一个名为 CrystalCandle 的应用程序,该应用程序可以将结构化数据的原始解释(通常只是数字)转换为叙述性解释(我们将在第 7 章中进一步讨论叙述性解释)。他们构建的叙述性解释示例显示在表 1-1 中。
| Model prediction and interpretation (nonintuitive) | Narrative insights (user-friendly) |
|---|---|
|
Propensity score: 0.85 (top 2%)
|
This account is extremely likely to upsell. Its upsell likelihood is larger than 98% of all accounts, which is driven by:
|
| 模型预测和解释(非直观) | 叙述性见解(用户友好) |
|---|---|
|
倾向得分:0.85(前 2%)
|
该账户极有可能进行追加销售。其追加销售的可能性高于 98% 的所有账户,主要原因如下:
|
PwC Uses Explainable AI for Auto Insurance Claims
普华永道利用可解释人工智能处理汽车保险理赔
Working with a large auto insurer, PricewaterhouseCoopers (PwC) built an ML system to estimate the amount of an insurance claim. In building the system, PwC clearly highlights how Explainable AI was not an optional addition to their core project, but a necessary requirement for the ML to be adopted by the insurance company, their claims adjusters, and customers. They call out four different benefits from using explainability in their ML solution:
普华永道 (PwC) 与一家大型汽车保险公司合作,构建了一个机器学习系统来估算保险理赔金额。在构建该系统的过程中,普华永道明确指出,可解释人工智能并非其核心项目的可选附加功能,而是保险公司、理赔员和客户采用该机器学习系统的必要条件。他们列举了在其机器学习解决方案中使用可解释性带来的四项益处:
The company’s explainable AI model was a game changer as it enabled > the following: >
- empowered auto claim estimators to identify where to focus attention > during an assessment >
- provided approaches for sharing knowledge among the estimator team > to accurately determine which group should handle specific estimates >
- identified 29% efficiency savings possible with full implementation > of proof of concept models across the estimator team >
- reduced rework and improved customer experience through reduced > cycle > times^ data-type="noteref">6^
该公司的可解释人工智能模型带来了颠覆性的改变,因为它实现了以下目标:
- 使汽车理赔估算员能够确定在评估过程中应重点关注哪些方面
- 为估算团队提供了知识共享的方法,以准确确定哪个团队应该处理特定的估算任务
- 确定了在估算团队全面实施概念验证模型后,可实现 29% 的效率提升
- 通过缩短周期时间,减少了返工,并改善了客户体验
In our work with customers at Google Cloud, we have also seen similar benefits to many customers who have built explainability into their AI.
在与 Google Cloud 客户的合作中,我们也看到许多客户通过将可解释性融入其人工智能解决方案而获得了类似的益处。
Accenture Labs Explains Loan Decisions
埃森哲实验室解释贷款决策
The experience of receiving a loan from a bank can be a confusing experience. The loan applicant is asked to fill in many forms and provide evidence of their financial situation and history in order to apply for a loan, often only asking for approval for the broad terms of the loan and the amount. In response, consumers are either approved, often with an interest rate decided by the bank, or they are denied with no further information. Accenture Labs demonstrated how even a common loan, the Home Equity Line of Credit (HELOC), could benefit from providing positive counterfactual explanations (covered in Chapter 2) as part of an ML’s prediction for whether to approve or deny a loan application. These counterfactual explanations focused on creating a “what-if” scenario for what aspects of the applicant’s credit history and financial situation would have resulted in the loan being approved or denied. In this case study, Accenture focused on understanding how explainability could be used across different ML systems,^7^ demonstrating the value of how using Explainable AI allowed for explanations to still be generated, while the underlying model was changed to different model architectures.
从银行获得贷款的经历可能令人困惑。贷款申请人需要填写大量表格,并提供其财务状况和历史记录的证明,才能申请贷款,而通常只能获得贷款大致条款和金额的批准。之后,消费者要么获得批准(通常利率由银行决定),要么被拒绝,且没有任何进一步的解释。埃森哲实验室展示了即使是常见的房屋净值信贷额度 (HELOC) 贷款,也可以通过提供积极的反事实解释(参见第 2 章)来改进机器学习模型对贷款申请的批准或拒绝预测。这些反事实解释侧重于创建“假设”场景,以说明申请人的信用记录和财务状况的哪些方面会导致贷款被批准或拒绝。在本案例研究中,埃森哲着重探讨了如何在不同的机器学习系统中应用可解释性,并展示了使用可解释人工智能的价值,即使底层模型更改为不同的模型架构,仍然可以生成解释。
DARPA Uses Explainable AI to Build “Third-Wave AI”
DARPA 利用可解释人工智能构建“第三代人工智能”
The Defense Advanced Research Projects Agency (DARPA), an arm of the US Department of Defense, conducted a five-year program^8^ with many projects to investigate the use of Explainable AI. DARPA’s goals in using Explainable AI are to “produce more explainable models, while maintaining a high level of learning performance” and “enable human users to understand, appropriately trust, and effectively manage the emerging generation of artificially intelligent partners.” DARPA believes explainability is a key component of the next generation of AI systems, where “machines understand the context and environment in which they operate, and over time build underlying explanatory models that allow them to characterize real-world phenomena.” Over the past few years, the program has had several annual workshops demonstrating the feasibility of building explainability into many different types of ML, from data analysis to autonomous systems and assistive decision-making tools.
美国国防部下属的国防高级研究计划局(DARPA)开展了一项为期五年的项目,旨在研究可解释人工智能的应用。DARPA 使用可解释人工智能的目标是“在保持高水平学习性能的同时,生成更易于解释的模型”,并“使人类用户能够理解、适度信任并有效管理新一代人工智能伙伴”。DARPA 认为可解释性是下一代人工智能系统的关键组成部分,在这种系统中,“机器能够理解其运行的上下文和环境,并随着时间的推移构建底层解释模型,从而能够描述现实世界的现象”。在过去几年中,该项目举办了多次年度研讨会,展示了将可解释性融入多种不同类型机器学习的可行性,涵盖数据分析、自主系统和辅助决策工具等领域。
Summary
总结
In this chapter, we introduced the concept of Explainable AI, a set of techniques that can be applied to ML models, after they have been built, to explain their behavior for one or more predictions made by the model. We also explored why Explainable AI is needed by different groups who work with ML models, such as ML practitioners, observers, and end users. Each of these types of users has different needs for explainability, ranging from improving the quality of a model to building confidence in the model’s effectiveness. To demonstrate this, we looked at several case studies of how explainability has been used. We started by contrasting two real-world examples in medicine, where one set of ML practitioners was trying to debug a poorly performing model used for classifying diseases from chest X-rays, while another group, ophthalmologists, needed to understand why their model had made a novel discovery about the inside of our eyes. To provide an introduction to other ways Explainable AI has been used, we also looked at other use cases across sales, fintech, and the defense industry. This introduction should help show you the variety of ways that explainability can be used, from different types of data and explanations, to the universal need for explainability regardless of the specific domain you are working in and the problem that ML is solving for your business.
在本章中,我们介绍了可解释人工智能(Explainable AI,简称 XAI)的概念。XAI 是一系列技术,可以在机器学习模型构建完成后应用于模型,以解释模型对一个或多个预测结果的决策过程。我们还探讨了不同群体(例如机器学习从业者、观察者和最终用户)为何需要可解释人工智能。这些不同类型的用户对可解释性的需求各不相同,从提高模型质量到增强对模型有效性的信心,不一而足。为了说明这一点,我们研究了几个可解释性应用的案例。我们首先对比了医学领域的两个真实案例:一组机器学习从业者试图调试一个用于从胸部 X 光片中分类疾病的性能不佳的模型;而另一组眼科医生则需要了解他们的模型为何对人眼内部结构做出了新的发现。为了介绍可解释人工智能的其他应用方式,我们还探讨了销售、金融科技和国防工业领域的其他用例。本章的介绍旨在向您展示可解释性的多种应用方式,包括不同类型的数据和解释,以及无论您从事哪个特定领域或机器学习正在解决什么业务问题,可解释性都是普遍需要的。
In the rest of this book, we will discuss in more detail the tools and frameworks you need to effectively use Explainable AI as part of your day-to-day work in building and deploying ML models. We will also give you a background in explainability so you can reason about the trade-offs between different types of techniques and give you a guide to developing responsible, beneficial interactions with explainability for other ML users. Our toolbox covers the three most popular data modalities in ML: tabular, image, and text, with an additional survey of more advanced techniques, including example- and concept-based approaches to XAI and how to frame XAI for time-series models. Throughout this book, we try to give an opinionated perspective on which tools are best suited for different use cases, and why, so you can be more pragmatic in your choices about how to employ explainability.
在本书的其余部分,我们将更详细地讨论您在日常构建和部署机器学习模型工作中有效使用可解释人工智能所需的工具和框架。我们还将为您提供可解释性方面的背景知识,以便您能够权衡不同技术之间的利弊,并指导您如何与其他机器学习用户进行负责任且有益的可解释性互动。我们的工具箱涵盖了机器学习中最流行的三种数据模式:表格数据、图像和文本,此外还概述了更高级的技术,包括基于示例和基于概念的 XAI 方法,以及如何为时间序列模型构建 XAI。在本书中,我们力求就哪些工具最适合不同的用例以及原因提供一些有针对性的建议,以便您在选择如何应用可解释性时更加务实。
In Chapter 2, we give you a framework for how different explainability methods can be categorized and evaluated, along with a taxonomy of how to describe who is ultimately using an explanation to help clarify the goals you will have in developing an Explainable AI for your ML model.
在第二章中,我们将为您提供一个框架,用于对不同的可解释性方法进行分类和评估,并提供一个分类体系,用于描述最终使用解释的人员,从而帮助您明确为机器学习模型开发可解释人工智能的目标。
^1^ The authors thank the National Cancer Institute (NCI) for access to their data collected by the Prostate, Lung, Colorectal and Ovarian (PLCO) Cancer Screening Trial. The statements contained herein are solely those of the authors and do not represent or imply concurrence or endorsement by NCI.
^2^ Edward Korot et al., “Predicting Sex from Retinal Fundus Photographs Using Automated Deep Learning,” Scientific Reports 11, article no. 10286 (May 2021), https://oreil.ly/Le50t.
^3^ Jilei Yang et al., “The Journey to Build an Explainable AI-Driven Recommendation System to Help Scale Sales Efficiency Across LinkedIn,” LinkedIn, April 6, 2022, https://oreil.ly/JJPj9.
^4^ Daniel Qiu and Yucheng Qian, “Relevance Debugging and Explaining at LinkedIn,” LinkedIn, 2019, https://oreil.ly/cSFhj.
^5^ Jilei Yang et al., “CrystalCandle: A User-Facing Model Explainer for Narrative Explanations,” arXiv, 2021, https://arxiv.org/abs/2105.12941.
^6^ See PwC, “Insurance Claims Estimator Uses AI for Efficiency,” (https://oreil.ly/3vMUr) for more information.
^7^ Roy McGrath et al., “Interpretable Credit Application Predictions with Counterfactual Explanations,” arXiv, 2018, https://arxiv.org/abs/1811.05245.
^8^ Dr. Matt Turek, “Explainable Artificial Intelligence (XAI),” DARPA.